Clear Sky Science · pl
Tłumaczalne wykrywanie muzyki generowanej przez maszynę i wczesna systematyczna ocena
Dlaczego ma to znaczenie dla fanów muzyki i twórców
Sztuczna inteligencja potrafi dziś skomponować przekonujące utwory w kilka sekund. To ekscytujące dla kreatywności, ale budzi obawy wśród muzyków, wytwórni i słuchaczy, którym zależy na oryginalności i sprawiedliwym uznaniu autorstwa. W tym badaniu zadano proste, ale pilne pytanie: czy można wiarygodnie rozpoznać, czy utwór został stworzony przez człowieka czy przez maszynę, i czy da się zrozumieć, jak systemy wykrywające podejmują swoje decyzje?
Trudność w wykrywaniu utworów stworzonych przez AI
Muzyka generowana maszynowo jest już wykorzystywana jako tło dźwiękowe, pomoc w pisaniu piosenek, a nawet w terapii. Te same narzędzia mogą jednak zasypać platformy streamingowe utworami niskiego wysiłku, zacierać autorstwo i osłabiać wartość kompozycji stworzonych przez ludzi. Wcześniejsze badania nad wykrywaniem fałszywego audio koncentrowały się głównie na mowie lub na wąskich przypadkach muzycznych i często opierały się na modelach nieudostępnionych publicznie albo na doraźnych testach. Autorzy twierdzą, że w tej dziedzinie brakuje jasnego, systematycznego porównania metod, szczególnie takiego, które wyjaśniałoby dlaczego detektor uzna utwór za prawdziwy lub fałszywy. Ich celem jest stworzenie wczesnego, kompleksowego benchmarku.
Jak badacze testowali detektory
Aby uczciwie porównać konkurencyjne podejścia, autorzy ocenili dziesięć popularnych typów modeli na dużym otwartym zbiorze danych o nazwie FakeMusicCaps, który miesza tysiące krótkich fragmentów muzyki skomponowanej przez ludzi z klipami wygenerowanymi przez kilka systemów text-to-music. Całe audio zostało przekształcone w spektrogramy Mel, wizualną reprezentację dźwięku szeroko stosowaną w współczesnym audio-AI, i każdy model otrzymał dokładnie te same wejścia. W skład zestawu wchodziły tradycyjne metody uczenia maszynowego, kilka rodzin sieci neuronowych głębokiego uczenia, systemy oparte na Transformerach oraz nowsze modele stanu (state space models) zaprojektowane do śledzenia długich sekwencji w czasie. Zespół następnie przetestował wytrenowane detektory na drugim, trudniejszym zbiorze danych o nazwie M6, zawierającym dłuższe i bardziej zróżnicowane utwory, aby sprawdzić, jak dobrze generalizują poza środowiskiem treningowym.
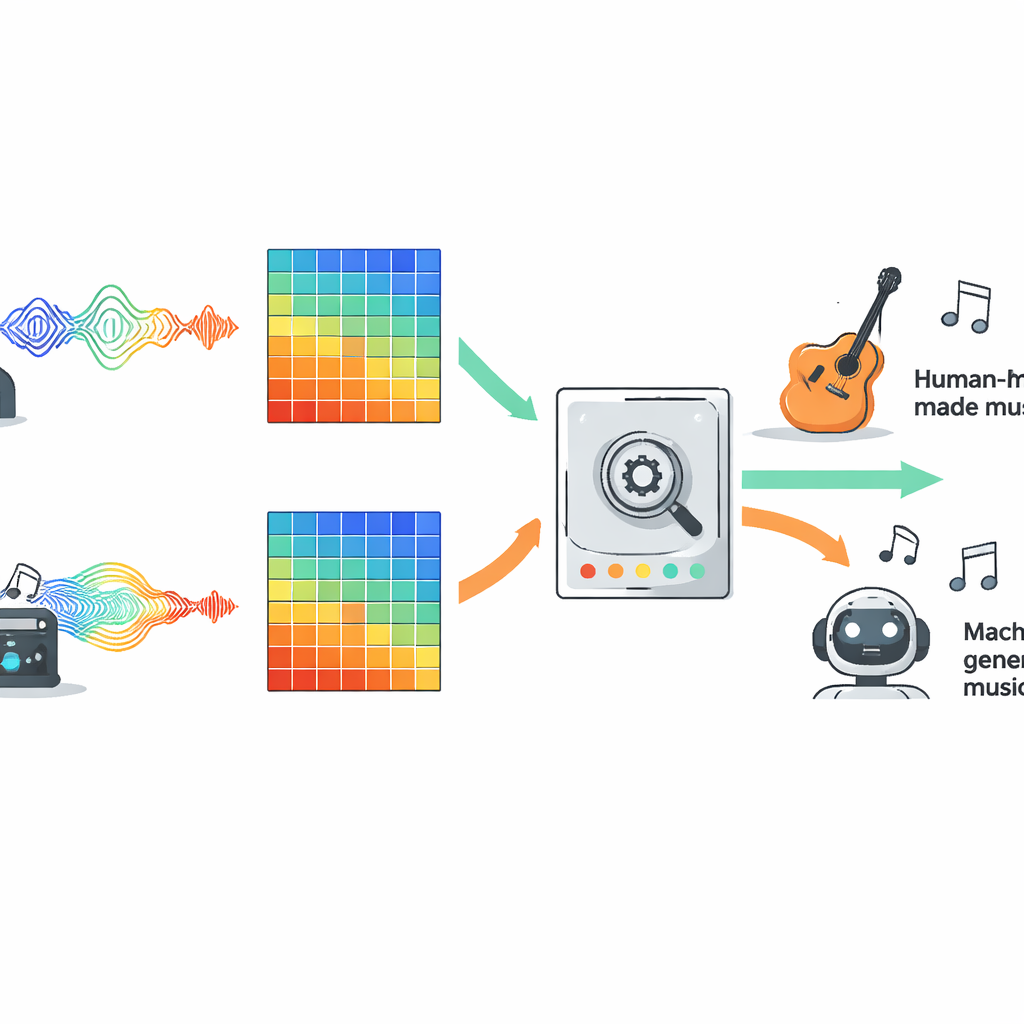
Co sprawdziło się najlepiej w różnych rodzajach muzyki
Na oryginalnych danych FakeMusicCaps wiele modeli głębokiego uczenia osiągnęło dobre wyniki. Zwięzła architektura o nazwie MobileNet uzyskała najwyższą dokładność i wynik F1, pokazując, że szybkie i lekkie systemy radzą sobie dobrze, gdy materiały testowe przypominają zbiór treningowy. Jednak na trudniejszej, pochodzącej z innej domeny kolekcji M6 wydajność spadła we wszystkich modelach, ujawniając, jak kruchy może być obecny stan detektorów w obliczu nowych generatorów, gatunków czy warunków nagrań. W bardziej realistycznym scenariuszu klasyczna sieć splotowa znana jako ResNet18 zapewniła najlepszą równowagę między sukcesem w obrębie domeny a odpornością poza nią, wyprzedzając bardziej złożone opcje takie jak Transformery i rozszerzone modele sekwencyjne. Badanie przetestowało także prostą konfigurację multimodalną, łączącą cechy audio z reprezentacjami tekstu piosenek; takie połączenie wyraźnie przewyższało podstawy oparte wyłącznie na audio, gdy dostępny był śpiewany tekst.
Wgląd do czarnej skrzynki
Samo wysokie wyniki nie wystarczą, gdy wykrywanie może wpływać na kariery i prawa autorskie, dlatego autorzy zwrócili się do narzędzi tłumaczalnej sztucznej inteligencji, aby zbadać, jak najlepszy model, ResNet18, podejmował decyzje. Zastosowali kilka popularnych metod wyjaśniających, które podświetlają, które obszary spektrogramu miały największe znaczenie przy klasyfikowaniu klipu jako ludzkiego lub maszynowego. Zamiast polegać na jednej technice, wprowadzili podejście „ensemble”, które szuka regionów, co do których zgadza się kilka metod. Gdy cyfrowo usunęli tylko te pokrywające się regiony z reprezentacji audio, wydajność wykrywania spadła gwałtownie, mimo że stosunkowo niewielka część spektrogramu została zamaskowana. Sugeruje to, że konsensus wskazuje naprawdę krytyczne wzorce akustyczne, a nie losowy szum.
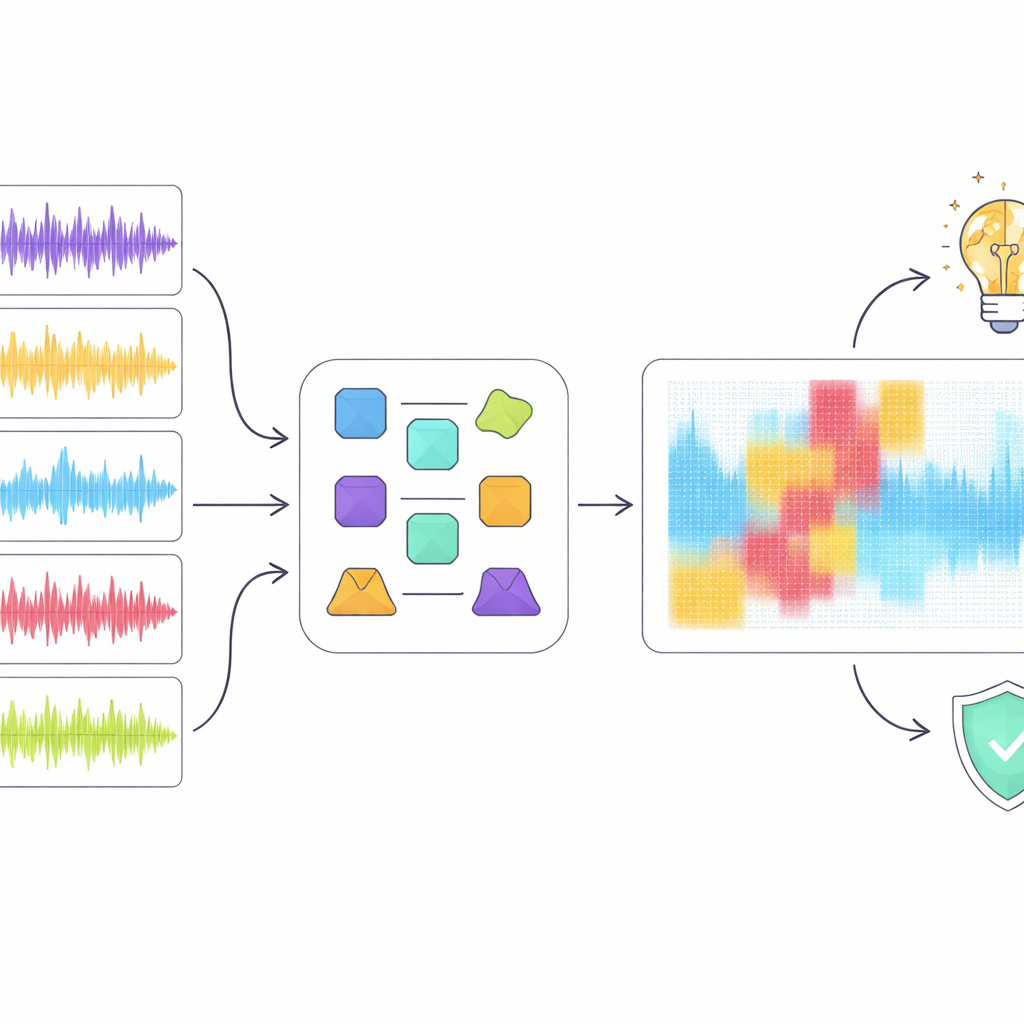
Co to ujawnia o muzyce i maszynach
Analiza tłumaczalności odkryła rozbieżność między tym, jak model „słucha”, a tym, jak ludzie odbierają muzykę. Na przykład detektor czasami traktował krótkie pauzy muzyczne jako podejrzane artefakty zamiast naturalnej struktury, karząc klipy, które słuchacze uznaliby za poprawnie ukształtowane. Ogólnie model wydawał się polegać bardziej na niskopoziomowych cechach widmowych niż na wysokopoziomowych pomysłach muzycznych, takich jak rytm, melodia czy forma. Autorzy argumentują, że przyszłe detektory powinny włączać bogatsze, świadome muzycznie cechy i lepiej wykorzystywać teksty, dążąc do podejmowania decyzji bardziej zgodnych z rozumieniem muzycznym, a nie tylko z powierzchownymi wzorcami.
Gdzie to stawia AI i muzykę dziś
Praca dostarcza jednej z pierwszych szerokich, przejrzystych miar do wykrywania muzyki generowanej przez AI oraz do wyjaśniania, jak takie detektory działają. Pokazuje, że obecne systemy potrafią często poprawnie oznaczać fałszywe utwory w kontrolowanych warunkach, ale mają trudności, gdy muzyka pochodzi z nowych źródeł, i że nie pojmują jeszcze struktury muzycznej tak jak ludzie. Autorzy proponują budowę detektorów następnej generacji, które łączyłyby wskazówki akustyczne, znaczenie tekstów, koncepcje teorii muzyki i metody tłumaczalne w jednym pipeline’ie. Jeśli się to uda, takie narzędzia mogłyby pomóc serwisom streamingowym, właścicielom praw i słuchaczom poruszać się w przyszłości, w której muzyka stworzona przez ludzi i maszyny współistnieje sprawiedliwiej i przejrzyściej.
Cytowanie: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
Słowa kluczowe: Muzyka generowana przez AI, wykrywanie deepfake audio, autentyczność muzyki, tłumaczalna sztuczna inteligencja, modele multimodalne