Clear Sky Science · it
Rilevamento spiegabile della musica generata dalle macchine e prima valutazione sistematica
Perché questo è importante per fan e creatori di musica
L’intelligenza artificiale può ora comporre brani convincenti in pochi secondi. Questo apre possibilità creative entusiasmanti ma crea preoccupazioni per musicisti, etichette discografiche e ascoltatori che tengono all’originalità e al riconoscimento corretto dei meriti. Lo studio pone una domanda semplice ma urgente: possiamo distinguere in modo affidabile se un pezzo è stato creato da un essere umano o da una macchina, e possiamo capire come questi sistemi di rilevamento prendono le loro decisioni?
La sfida di individuare brani creati dall’IA
La musica generata da macchina viene già usata per colonne sonore di sottofondo, supporto alla scrittura di canzoni e persino terapie. Tuttavia, gli stessi strumenti possono saturare le piattaforme di streaming con tracce a basso sforzo, offuscare la paternità e indebolire il valore delle composizioni umane. Ricerche precedenti sul rilevamento di audio falsi si sono concentrate principalmente sul parlato o su casi musicali ristretti e spesso si sono basate su modelli non pubblicati o test isolati. Gli autori sostengono che il campo manca di un confronto chiaro e sistematico fra metodi, specialmente uno che spieghi anche il motivo per cui un rilevatore dichiara un brano reale o falso. Il loro obiettivo è costruire quel primo benchmark comprensivo.
Come i ricercatori hanno testato i rilevatori
Per confrontare gli approcci in modo equo, gli autori hanno valutato dieci tipi popolari di modelli su un ampio dataset aperto chiamato FakeMusicCaps, che mescola migliaia di clip brevi composti da umani con clip generate da diversi sistemi text-to-music. Tutti gli audio sono stati convertiti in spettrogrammi Mel, una rappresentazione visiva del suono ampiamente usata nell’IA audio moderna, e ogni modello ha visto esattamente gli stessi input. La selezione includeva apprendimento automatico tradizionale, diverse famiglie di reti neurali profonde, sistemi basati su Transformer e modelli di stato di sequenza più recenti progettati per seguire sequenze lunghe nel tempo. Il team ha poi messo i rilevatori addestrati su un secondo dataset più impegnativo chiamato M6, contenente brani più lunghi e vari, per verificare quanto bene si generalizzassero oltre l’ambiente di addestramento.
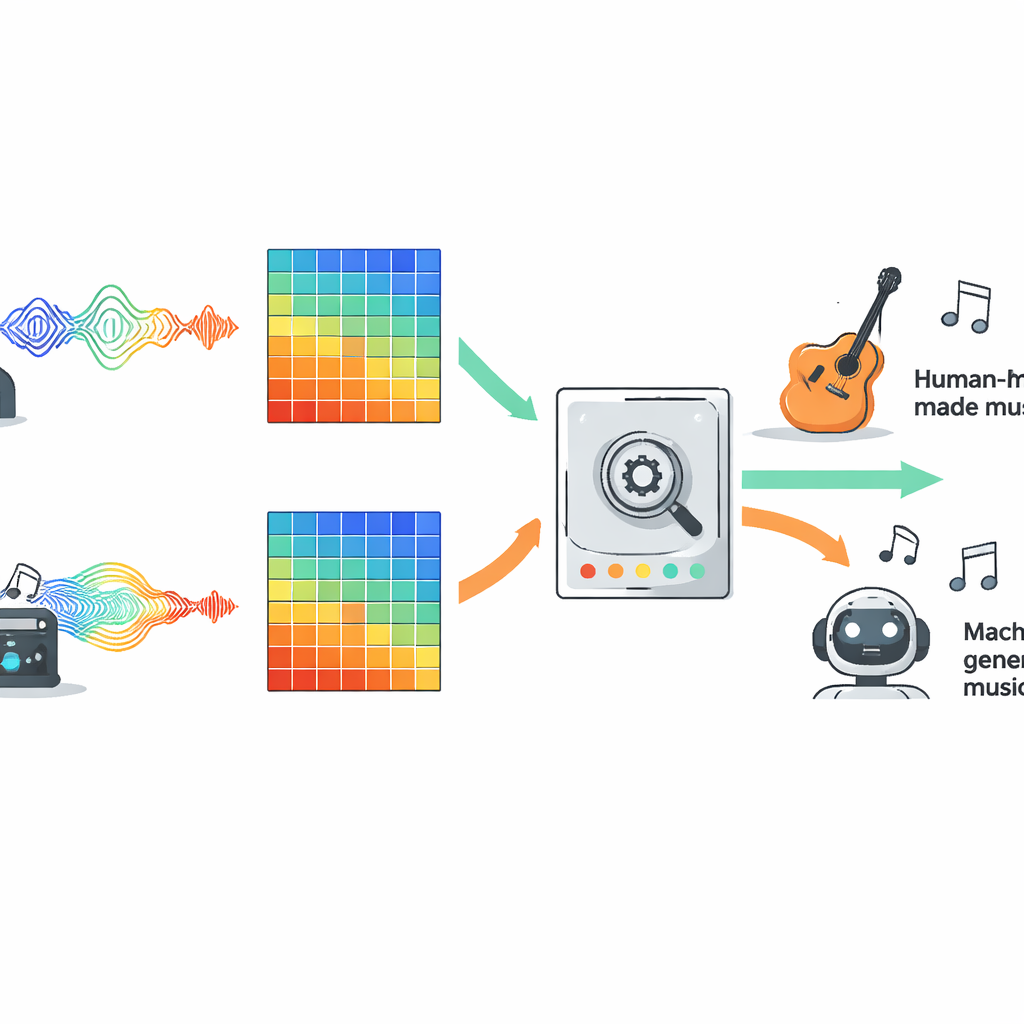
Cos’ha funzionato meglio attraverso diversi generi musicali
Sui dati originali di FakeMusicCaps molti modelli di deep learning hanno ottenuto buone prestazioni. Un’architettura compatta chiamata MobileNet ha raggiunto la massima accuratezza e il miglior punteggio F1, mostrando che sistemi rapidi e leggeri possono funzionare bene quando il materiale di test è simile al set di addestramento. Tuttavia, sulla più difficile collezione out-of-domain M6 le prestazioni sono calate per tutti i modelli, rivelando quanto gli attuali rilevatori possano essere fragili di fronte a nuovi generatori, generi o condizioni di registrazione. In questo contesto più realistico, una rete convoluzionale classica nota come ResNet18 ha offerto il miglior equilibrio tra successo in-domain e robustezza out-of-domain, battendo opzioni più complesse come i Transformer e i modelli per sequenze estese. Lo studio ha inoltre testato una semplice configurazione multimodale che combinava caratteristiche audio con rappresentazioni del testo dei testi, e questa fusione ha chiaramente superato le baseline solo-audio ogni volta che il testo cantato era disponibile.
Dentro la scatola nera
Punteggi elevati da soli non bastano quando il rilevamento può incidere su carriere e diritti d’autore, quindi gli autori hanno utilizzato strumenti di intelligenza artificiale spiegabile per ispezionare come il miglior modello, ResNet18, giungeva alle sue decisioni. Hanno applicato diversi metodi di spiegazione popolari che evidenziano quali regioni di uno spettrogramma erano più importanti per classificare una clip come umana o generata dalla macchina. Piuttosto che affidarsi a una singola tecnica, hanno introdotto un approccio “ensemble” che cerca regioni su cui più metodi concordano. Quando hanno rimosso digitalmente solo queste regioni sovrapposte dalla rappresentazione audio, le prestazioni di rilevamento sono precipitate anche se una porzione relativamente piccola dello spettrogramma era stata mascherata. Questo suggerisce che il consenso evidenzia pattern acustici realmente critici piuttosto che rumore casuale.
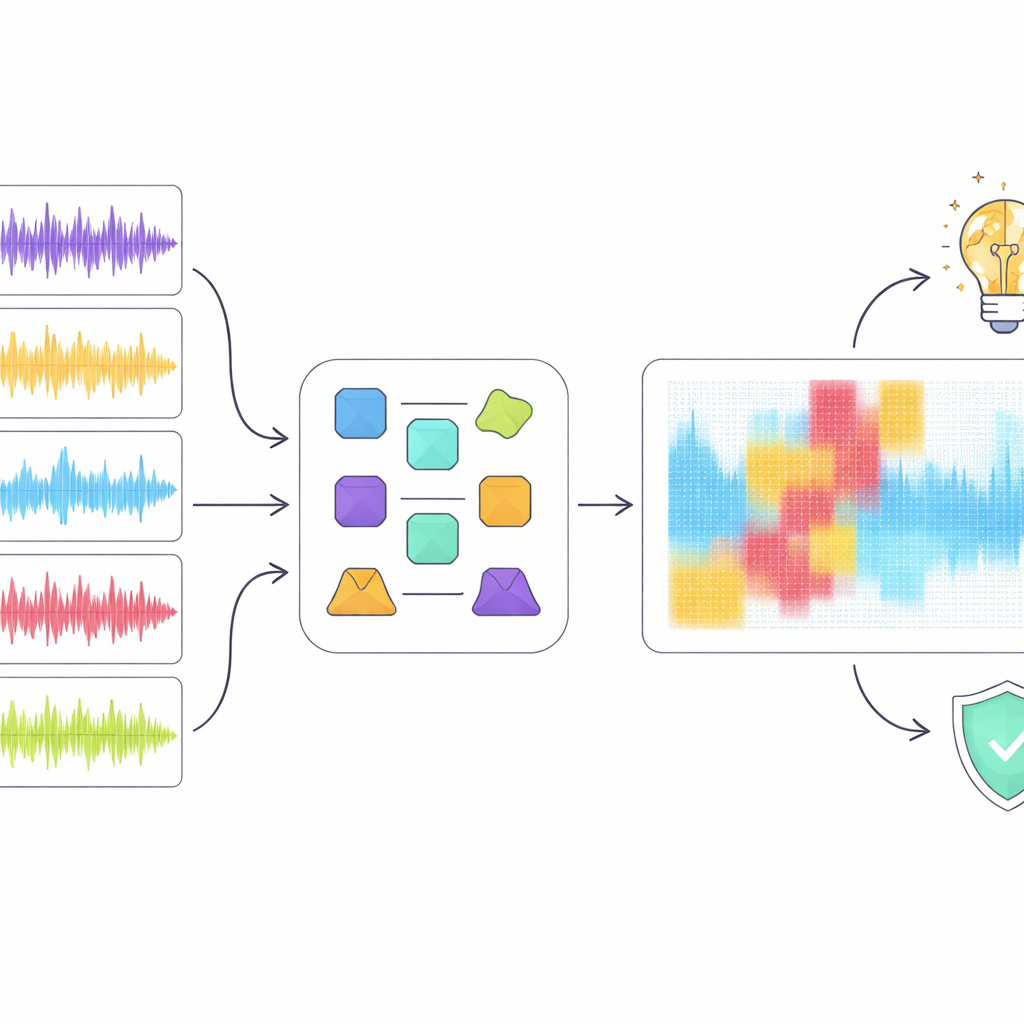
Cosa rivela questo sul rapporto fra musica e macchine
L’analisi di spiegabilità ha messo in luce un divario tra come il modello “ascolta” e come gli esseri umani percepiscono la musica. Per esempio, il rilevatore a volte trattava brevi pause musicali come artefatti sospetti anziché come struttura naturale, penalizzando clip che gli ascoltatori umani considererebbero ben formate. In generale, il modello sembrava fare maggiore affidamento su particolarità spettrali a basso livello piuttosto che su concetti musicali di alto livello come ritmo, melodia e forma. Gli autori sostengono che i futuri rilevatori dovrebbero integrare caratteristiche più ricche sensibili alla musica e un uso migliore dei testi, puntando a decisioni che si allineino più strettamente con la comprensione musicale piuttosto che con semplici pattern di superficie.
Dove lascia oggi l’IA e la musica
Questo lavoro fornisce uno dei primi criteri ampi e trasparenti per rilevare musica generata dall’IA e per spiegare come tali rilevatori operano. Mostra che i sistemi attuali spesso riescono a segnalare correttamente tracce false in contesti controllati ma faticano quando la musica proviene da nuove sorgenti, e che non comprendono ancora la struttura musicale come le persone. Gli autori propongono di costruire rilevatori di nuova generazione che combinino segnali acustici, significato dei testi, concetti di teoria musicale e metodi spiegabili in una pipeline unica. Se avviati con successo, tali strumenti potrebbero aiutare servizi di streaming, titolari dei diritti e ascoltatori a orientarsi in un futuro dove musica umana e generata dalle macchine coesistono in modo più equo e trasparente.
Citazione: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
Parole chiave: musica generata dall'IA, rilevamento deepfake audio, autenticità musicale, IA spiegabile, modelli multimodali