Clear Sky Science · sv
Förklarbar upptäckt av maskingenererad musik och tidig systematisk utvärdering
Varför detta är viktigt för musikfans och kreatörer
Artificiell intelligens kan nu komponera trovärdiga låtar på några sekunder. Det är spännande för kreativitet men oroande för musiker, skivbolag och lyssnare som värnar om originalitet och rättvis kreditgivning. Denna studie ställer en enkel men brådskande fråga: kan vi pålitligt avgöra om ett musikstycke skapats av en människa eller av en maskin, och kan vi förstå hur dessa detekteringssystem fattar sina beslut?
Utmaningen att upptäcka AI-skapade låtar
Maskingenererad musik används redan för bakgrundssoundtrack, hjälp vid låtskrivande och till och med terapi. Samma verktyg kan dock översvämma streamingtjänster med låginsatsspår, sudda ut upphovsskap och försvaga värdet av mänskligt skapade kompositioner. Tidigare forskning om upptäckt av falskt ljud har mest fokuserat på tal eller på snäva musikfall och förlitade sig ofta på opublicerade modeller eller engångstester. Författarna menar att fältet saknar en tydlig, systematisk jämförelse av metoder, särskilt en som också förklarar varför en detektor bedömer ett spår som äkta eller falskt. Deras mål är att bygga ett tidigt, omfattande riktmärke.
Hur forskarna testade detektorerna
För att jämföra konkurrerande angreppssätt rättvist utvärderade författarna tio populära modelltyper på en stor öppen dataset kallad FakeMusicCaps, som blandar tusentals korta klipp av människokomponerad musik med klipp genererade av flera text-till-musik-system. Allt ljud konverterades till Mel-spektrogram, en visuell representation av ljud som är allmänt använd i modern ljud-AI, och varje modell fick exakt samma indata. Upplägget inkluderade traditionell maskininlärning, flera familjer av djupa neurala nätverk, Transformer-baserade system och nyare state-space-modeller som är utformade för att följa långa sekvenser över tid. Teamet testade sedan de tränade detektorerna på en andra, tuffare dataset kallad M6, som innehåller längre och mer varierade låtar, för att se hur väl de generaliserade bortom sin träningsmiljö.
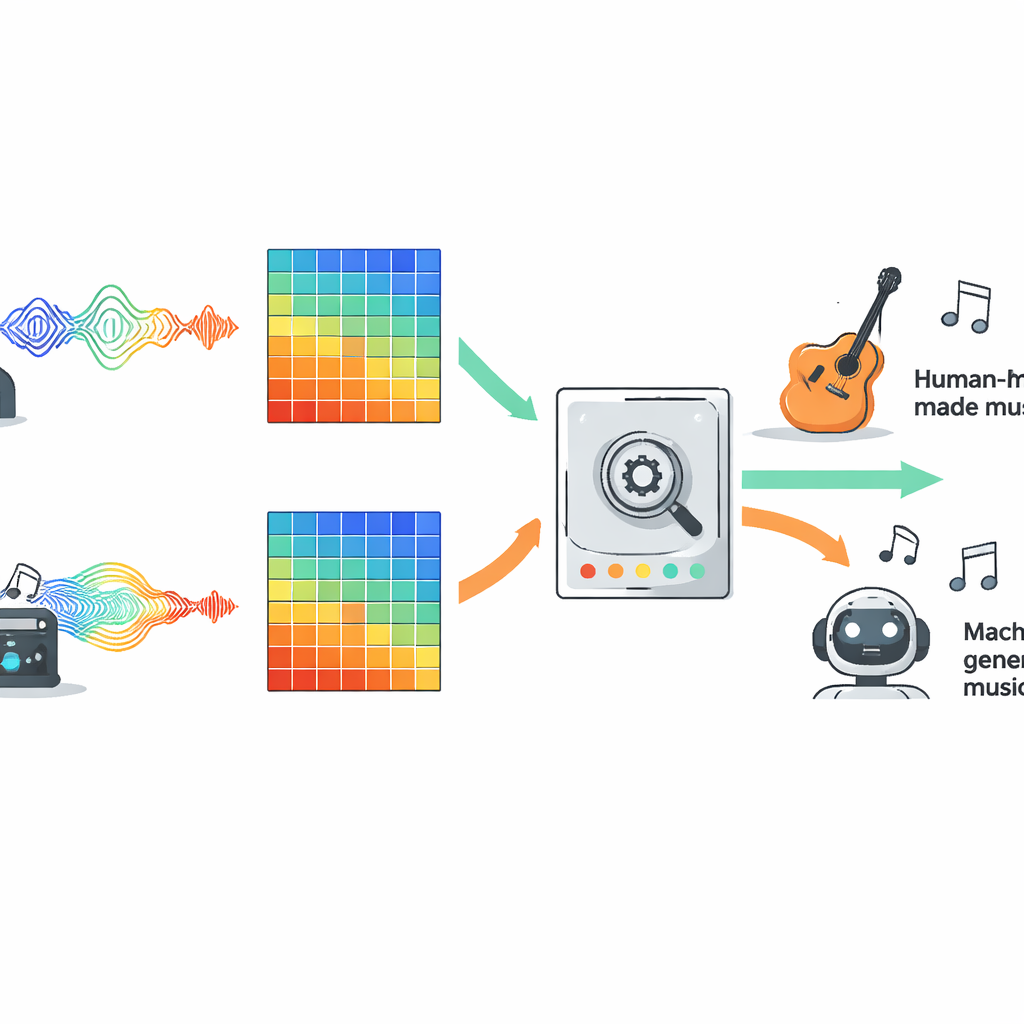
Vad som fungerade bäst över olika musiktyper
På den ursprungliga FakeMusicCaps-datan presterade många deep learning-modeller starkt. En kompakt arkitektur kallad MobileNet nådde högst noggrannhet och F1-poäng, vilket visar att snabba och lätta system kan fungera väl när testmaterial liknar träningsdatasetet. På den svårare, utanför-domain M6-samlingen sjönk dock prestandan för alla modeller, vilket blottlade hur sköra nuvarande detektorer kan vara när de konfronteras med nya generatorer, genrer eller inspelningsförhållanden. I denna mer realistiska situation levererade ett klassiskt konvolutionellt nätverk känt som ResNet18 den bästa balansen mellan framgång inom domänen och robusthet utanför den, och slog mer komplexa alternativ som Transformers och utökade sekvensmodeller. Studien testade också en enkel multimodal uppsättning som kombinerade ljudfunktioner med representationer av texterna, och denna fusion överträffade tydligt ljud-endast-baslinjer när sångtext fanns tillgänglig.
Att titta in i svart låda
Höga poäng räcker inte när upptäckt kan påverka karriärer och upphovsrätt, så författarna vände sig till förklarbar artificiell intelligens för att undersöka hur den bästa modellen, ResNet18, nådde sina beslut. De tillämpade flera populära förklaringsmetoder som lyfter fram vilka regioner i ett spektrogram som var viktigast för att klassificera ett klipp som mänskligt eller maskinskapade. Istället för att lita på en enda teknik introducerade de ett ”ensemble”-angreppssätt som söker efter regioner som flera metoder är ense om är viktiga. När de digitalt tog bort endast dessa överlappande regioner från ljudrepresentationen sjönk detekteringsprestandan kraftigt trots att en relativt liten del av spektrogrammet maskades. Detta tyder på att konsensusen framhäver genuint kritiska akustiska mönster snarare än slumpmässigt brus.
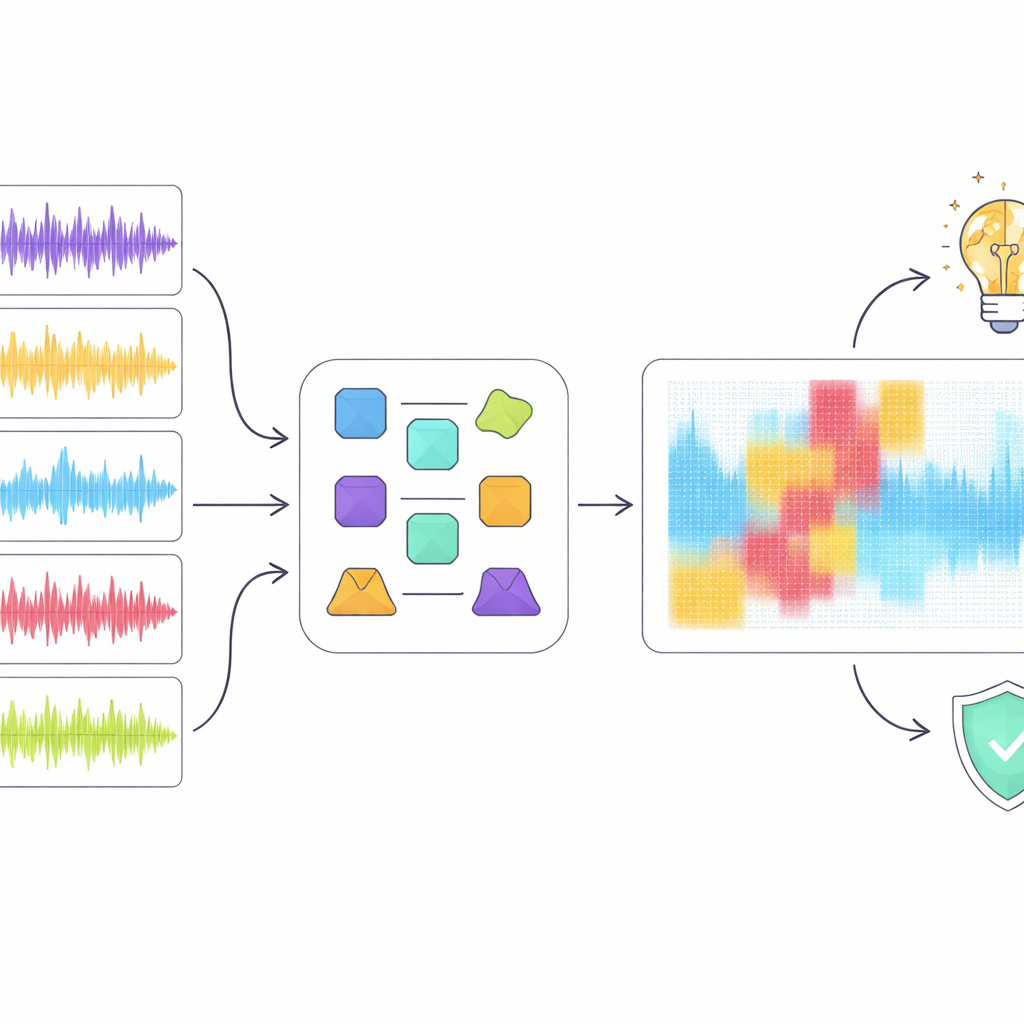
Vad detta avslöjar om musik och maskiner
Förklaringsanalysen avslöjade ett glapp mellan hur modellen ”lyssnar” och hur människor hör musik. Till exempel behandlade detektorn ibland korta musikaliska pauser som misstänkta artefakter istället för naturlig struktur och straffade klipp som mänskliga lyssnare skulle anse vara välformade. Överlag verkade modellen förlita sig mer på låg nivå spektrala egenheter än på högre musikaliska idéer som rytm, melodi och form. Författarna menar att framtida detektorer bör väva in rikare musikmedvetna funktioner och bättre utnyttjande av texter, i syfte att fatta beslut som ligger närmare musikalmänsklig förståelse snarare än enbart ytliga mönster.
Var det här lämnar AI och musik idag
Detta arbete levererar en av de första breda, transparenta måttstockarna för att upptäcka AI-genererad musik och för att förklara hur sådana detektorer fungerar. Det visar att nuvarande system ofta kan flagga falska spår korrekt i kontrollerade miljöer men har svårt när musik kommer från nya källor, och att de ännu inte förstår musikstruktur på samma sätt som människor gör. Författarna föreslår att bygga nästa generations detektorer som kombinerar akustiska ledtrådar, textens innebörd, musikteorikoncept och förklarbara metoder i ett enda arbetsflöde. Om det lyckas kan sådana verktyg hjälpa streamingtjänster, rättighetsinnehavare och lyssnare att navigera en framtid där mänskligt och maskinskapat musik samexisterar mer rättvist och transparent.
Citering: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
Nyckelord: AI-genererad musik, deepfake-ljudupptäckt, musikautenticitet, förklarbar AI, multimodala modeller