Clear Sky Science · de
Erklärbare Erkennung von maschinell erzeugter Musik und frühe systematische Bewertung
Warum das für Musikfans und -schaffende wichtig ist
Künstliche Intelligenz kann inzwischen in Sekunden überzeugende Songs komponieren. Das ist einerseits spannend für die Kreativität, andererseits besorgniserregend für Musiker, Plattenfirmen und Hörer, denen Originalität und faire Anerkennung wichtig sind. Diese Studie stellt eine einfache, aber dringliche Frage: Lassen sich Stücke zuverlässig als menschlich oder maschinell erzeugt unterscheiden, und können wir nachvollziehen, wie diese Erkennungssysteme zu ihren Entscheidungen kommen?
Die Herausforderung, KI-erstellte Songs zu erkennen
Maschinell erzeugte Musik wird bereits für Hintergrundsoundtracks, als Hilfe beim Songwriting und sogar in der Therapie eingesetzt. Dieselben Werkzeuge können jedoch Streaming-Plattformen mit lieblosen Tracks überschwemmen, Urheberschaften verwischen und den Wert menschlicher Kompositionen schmälern. Frühere Forschung zur Erkennung gefälschter Audiodaten konzentrierte sich überwiegend auf Sprache oder auf enge musikalische Fälle und basierte oft auf unveröffentlichten Modellen oder Einzeltests. Die Autorinnen und Autoren argumentieren, dass es an einem klaren, systematischen Vergleich der Methoden fehlt — insbesondere an einem, der auch erklärt, warum ein Detektor einen Track als echt oder gefälscht einstuft. Ihr Ziel ist es, genau diesen frühen, umfassenden Benchmark zu bauen.
Wie die Forschenden die Detektoren getestet haben
Um konkurrierende Ansätze fair zu vergleichen, bewerteten die Autoren zehn verbreitete Modelltypen auf einem großen offenen Datensatz namens FakeMusicCaps, der Tausende kurzer Ausschnitte menschlich komponierter Musik mit von verschiedenen Text-zu-Musik-Systemen generierten Clips mischt. Alle Audiodaten wurden in Mel-Spektrogramme umgewandelt, eine visuelle Darstellung von Schall, die in moderner Audio-KI weit verbreitet ist, und jedes Modell erhielt exakt dieselben Eingaben. Die Auswahl umfasste klassische maschinelle Lernverfahren, mehrere Familien tiefer neuronaler Netze, Transformer-basierte Systeme und neuere State-Space-Modelle, die dafür entwickelt wurden, lange Sequenzen über die Zeit zu verfolgen. Das Team setzte die trainierten Detektoren anschließend auf einen zweiten, anspruchsvolleren Datensatz namens M6 an, der längere und vielfältigere Songs enthält, um zu prüfen, wie gut die Modelle über ihre Trainingsumgebung hinaus generalisieren.
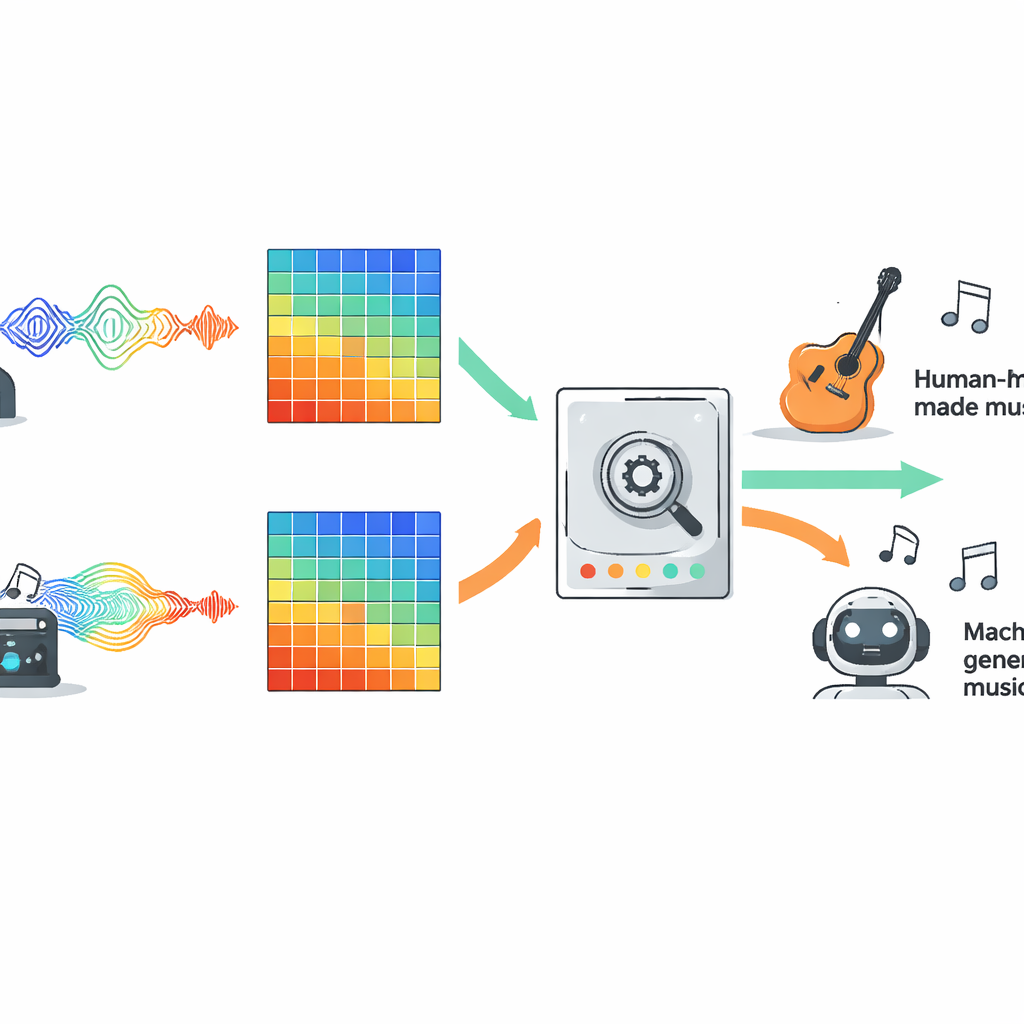
Was über verschiedene Musikarten hinweg am besten funktionierte
Auf den Originaldaten von FakeMusicCaps lieferten viele Deep-Learning-Modelle starke Leistungen. Eine kompakte Architektur namens MobileNet erreichte die höchste Genauigkeit und den besten F1-Wert, was zeigt, dass schnelle und leichte Systeme gute Ergebnisse erzielen können, wenn das Testmaterial dem Trainingssatz ähnelt. Auf der schwierigeren, out-of-domain M6-Sammlung sank die Leistung jedoch bei allen Modellen, was die Zerbrechlichkeit aktueller Detektoren offenbart, wenn sie mit neuen Generatoren, Genres oder Aufnahmebedingungen konfrontiert werden. In diesem realistischeren Szenario erzielte ein klassisches Faltungsnetzwerk, bekannt als ResNet18, die beste Balance zwischen Erfolgen im Trainingsbereich und Robustheit außerhalb davon und übertraf komplexere Optionen wie Transformer und erweiterte Sequenzmodelle. Die Studie prüfte außerdem ein einfaches multimodales Setup, das Audioeigenschaften mit Repräsentationen der Liedtexte kombinierte; diese Fusion übertraf deutlich die rein audio-basierten Baselines, sofern gesungener Text verfügbar war.
Ein Blick in die Black Box
Hohe Werte allein reichen nicht aus, wenn Erkennung Karrieren und Urheberrechte beeinflussen kann, daher wandten sich die Autorinnen und Autoren erklärbaren KI-Werkzeugen zu, um nachzuvollziehen, wie das beste Modell, ResNet18, zu seinen Entscheidungen gelangte. Sie setzten mehrere gängige Erklärmethoden ein, die hervorheben, welche Bereiche eines Spektrogramms für die Einordnung eines Clips als menschlich oder maschinell besonders wichtig waren. Statt einer einzigen Technik zu vertrauen, führten sie einen „Ensemble“-Ansatz ein, der nach Regionen sucht, denen mehrere Methoden zustimmen. Als sie nur diese überlappenden Regionen aus der Audio-Repräsentation digital entfernten, brach die Erkennungsleistung deutlich ein, obwohl ein relativ kleiner Teil des Spektrogramms maskiert wurde. Das deutet darauf hin, dass der Konsens tatsächlich kritische akustische Muster hervorhebt und nicht bloß zufälliges Rauschen.
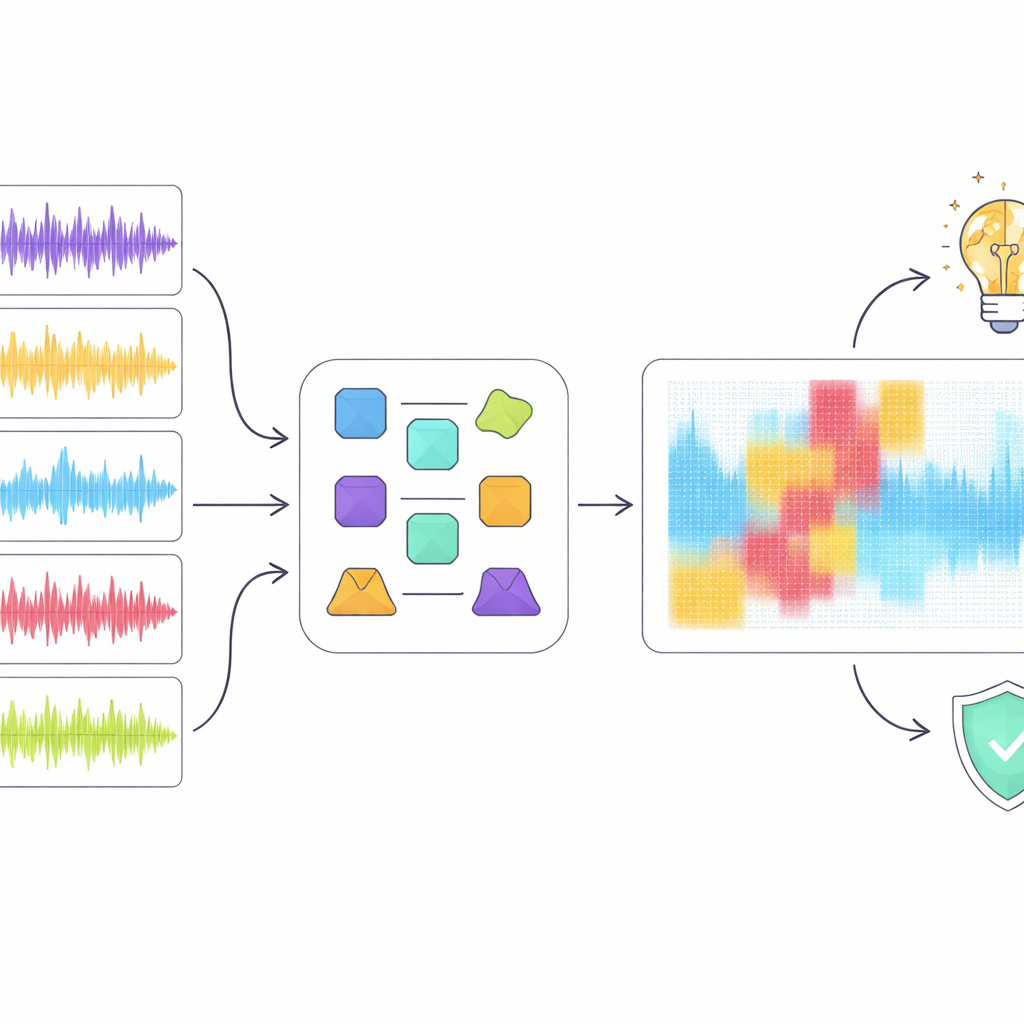
Was das über Musik und Maschinen offenbart
Die Erklärbarkeitsanalyse zeigte eine Lücke zwischen dem, wie das Modell „hört“, und der menschlichen Wahrnehmung von Musik. Beispielsweise behandelte der Detektor manchmal kurze musikalische Pausen als verdächtige Artefakte statt als natürliche Struktur und benachteiligte damit Ausschnitte, die menschliche Hörer als wohlgeformt ansehen würden. Insgesamt schien das Modell stärker auf niedrigstufige spektrale Eigenheiten zu setzen als auf höhere musikalische Konzepte wie Rhythmus, Melodie und Form. Die Autorinnen und Autoren schlagen vor, dass künftige Detektoren reichere musikwissenschaftlich informierte Merkmale und eine bessere Nutzung von Lyrics einbinden sollten, um Entscheidungen zu treffen, die musikalischem Verständnis näher kommen statt bloßen Oberflächenmustern.
Wo sich KI und Musik heute befinden
Diese Arbeit liefert eines der ersten breiten, transparenten Messinstrumente zur Erkennung KI-generierter Musik und zur Erklärung, wie solche Detektoren arbeiten. Sie zeigt, dass aktuelle Systeme in kontrollierten Settings oft gefälschte Tracks korrekt markieren können, bei Musik aus neuen Quellen jedoch Schwierigkeiten haben und musikalische Struktur noch nicht so erfassen, wie Menschen es tun. Die Autorinnen und Autoren schlagen vor, nächste Generationen von Detektoren zu entwickeln, die akustische Hinweise, Textbedeutung, musiktheoretische Konzepte und erklärbare Methoden in einer einzigen Pipeline vereinen. Gelingt das, könnten solche Werkzeuge Streaming-Diensten, Rechteinhabern und Hörern helfen, sich in einer Zukunft zurechtzufinden, in der menschliche und maschinell erzeugte Musik gerechter und transparenter koexistieren.
Zitation: Li, Y., Sun, Q., Li, H. et al. Explainable detection of machine generated music and early systematic evaluation. Sci Rep 16, 13757 (2026). https://doi.org/10.1038/s41598-026-42133-7
Schlüsselwörter: KI-generierte Musik, Deepfake-Audio-Erkennung, Musikauthentizität, erklärbare KI, multimodale Modelle