Clear Sky Science · zh
一种用于雾节点性能预测的机器学习模型中新颖良点集逐步收缩优化方法
更聪明的设备需要更聪明的调优
从健身追踪器到智能恒温器和互联汽车,如今的设备不断将数据发送到数字空间。大量信息在网络边缘的附近“雾”计算节点上处理,而不是送往遥远的数据中心。这样的本地处理能保持应用响应快速并减少网络拥塞,但前提是这些雾节点被高效利用。本文所述论文提出了一种新的方法来调优机器学习模型,使其能够更准确地预测雾节点的性能,从而帮助日常互联设备运行得更快、更顺畅、并减少能耗浪费。
繁忙的边缘计算机所面临的挑战
随着数十亿物联网设备上线,它们向网络发送大量请求:需要分析的传感器读数、待过滤的视频流以及需要实时决策的控制信号。雾计算通过将计算移近数据源来应对这一点,部署在家庭、车辆、工厂和城市街道的分散机器上。为了保持低延迟,调度器必须决定将每项任务分配给哪个雾节点,这一决策在很大程度上依赖于每个节点处理器的繁忙程度以及完成任务的速度。作者侧重于从诸如 CPU 使用率等简单指标预测节点性能,以便能够智能分配任务,而不是凭运气分配。
为何调优机器学习代价高昂
机器学习模型有一些旋钮,称为超参数,必须在训练前设置。示例包括模型对错误的惩罚强度、从新数据中学习的速度或内部单元的数量。找到良好的旋钮设置往往比选择模型本身更重要。当前,这类调优通常依靠对数据反复打乱(交叉验证)并用随机猜测、巧妙搜索规则或进化策略等方法探索超参数空间。尽管这些方法很强大,但存在两个主要缺点:它们引入了随机性,导致结果难以复现;同时这类方法可能非常耗时,特别是对于具有数百个设置的深度神经网络。
一种更有序的搜索方式
作者提出了一种不同策略,称为良点集逐步收缩(Good Point Set Stepwise Shrinkage,简称 GPSS)。他们不是随机采样可能的超参数空间,而是使用精心构造、均匀分布的点集,这一概念源自数论。在每个阶段,GPSS 评估一批这些间距良好的候选点,并衡量相应模型对 CPU 性能的预测效果。然后它把搜索窗口收窄到表现最好的区域,按固定比例收缩边界,并在这更小的区域内生成新一批更密的均匀点。重复这一“粗到精”过程可以逐步锁定有前景的超参数组合,而无需对数据反复随机重排。
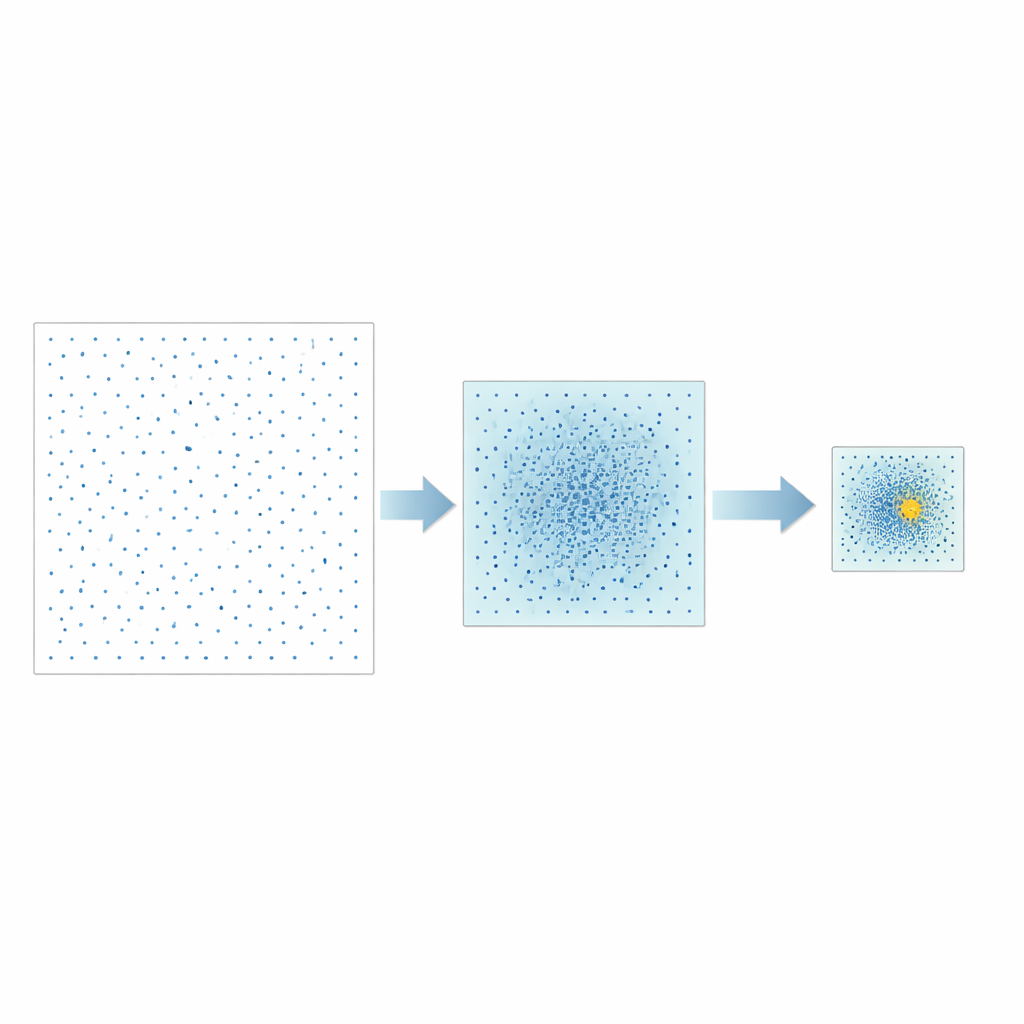
在不同类型模型上的测试
为评估 GPSS 的实际表现,团队将其应用于三种流行的机器学习模型:支持向量机、称为反向传播的经典浅层神经网络,以及更深的卷积神经网络。三者均被训练以根据先前工作收集的使用数据预测雾节点的 CPU 性能。研究将 GPSS 与若干已建立的优化方法进行比较,包括顺序均匀设计、遗传算法和一种基于群体的技术。研究者既衡量了预测精度(使用均方误差),也衡量了调优所需时间。总体上,GPSS 在精度上与竞争方法持平或优于它们,同时显著降低了计算成本,并且是唯一对高维卷积网络情形实用的方法。
提高结果的稳定性和可重复性
除了原始精度外,作者还强调稳定性。由于 GPSS 用确定性的点集替代了随机抽样,并且采用了对传统交叉验证的结构化替代方法,其结果在多次运行间的波动要小得多。在仿真中,使用 GPSS 调优的模型所做的预测紧密聚集在真实的 CPU 性能周围,重复实验几乎给出相同的结果。该方法在标准数学测试问题上也显示出很强的全局搜索能力,这表明在探索复杂超参数空间时不太可能陷入局部最优。
对日常互联技术的意义
简而言之,这项工作是关于以更有序、更高效的方式调整学习算法的旋钮。通过用均匀分布的搜索点和逐步收窄的聚焦替代试错式的随机性,GPSS 找到可靠的设置,使模型能够预测雾节点的繁忙程度。更好的预测意味着更智能的任务调度、更短的应用等待时间,以及消费设备网络中潜在的更低能耗。作者也指出了局限性——例如对某些离散设置存在挑战以及需要更广泛的测试——但他们的方法为保持未来日益增长的智能设备网络平稳运行提供了一个有前景的蓝图。
引用: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
关键词: 雾计算, 超参数优化, 边缘机器学习, 物联网, 性能预测