Clear Sky Science · en
A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction
Smarter Devices Need Smarter Tuning
From fitness trackers to smart thermostats and connected cars, today’s gadgets constantly send data into the digital ether. Much of that information is processed on nearby “fog” computers at the edge of the network, rather than in far‑off data centers. This local processing keeps apps snappy and reduces congestion, but only if those fog nodes are used efficiently. The paper summarized here introduces a new way to tune machine‑learning models so they can more accurately predict how well fog nodes will perform, helping everyday connected devices run faster, smoother, and with less wasted energy.
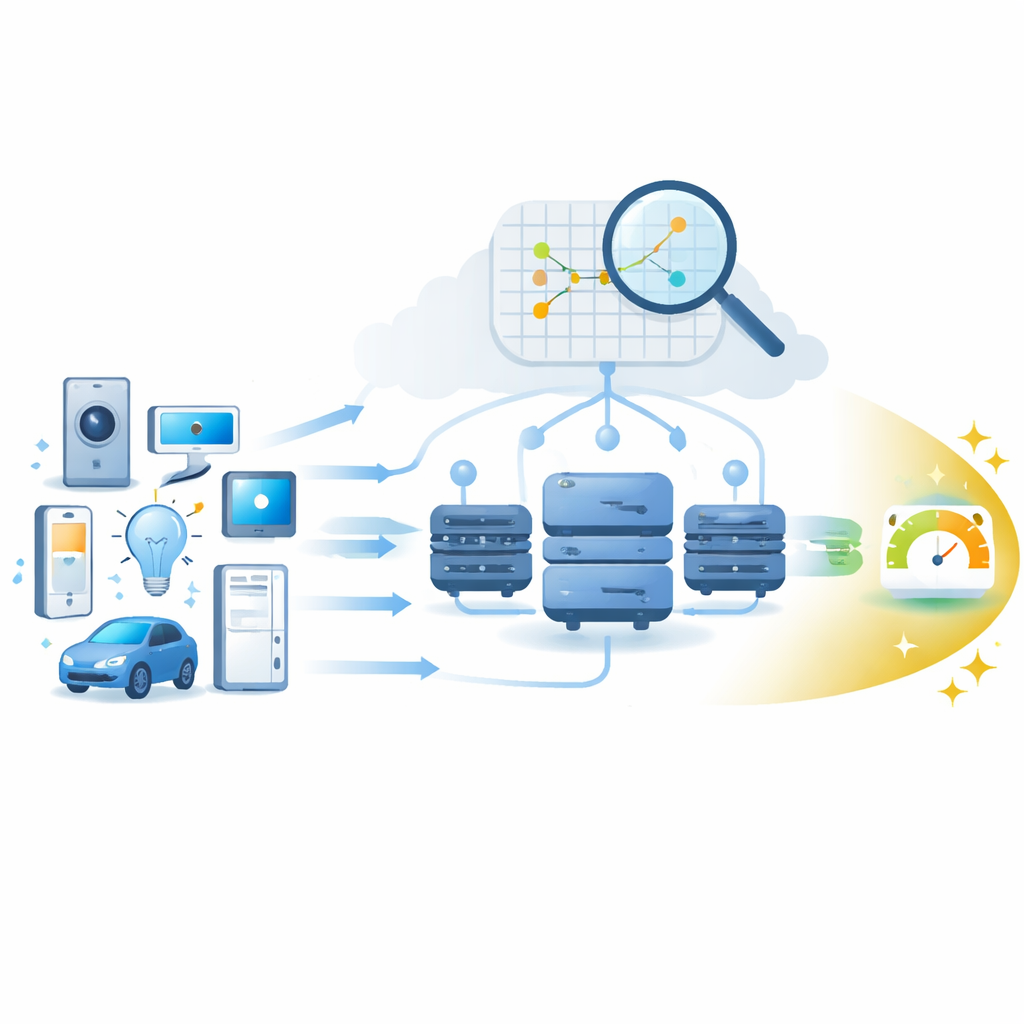
The Challenge of Busy Edge Computers
As billions of Internet of Things devices come online, they flood the network with requests: sensor readings to analyze, video streams to filter, and control signals to decide on in real time. Fog computing tackles this by moving computation closer to the source, on machines scattered throughout homes, cars, factories, and city streets. To keep delays low, a scheduler must decide which fog node should handle each job, and that decision depends heavily on how busy each node’s processor is and how quickly it can finish a task. The authors focus on predicting this node performance from simple indicators such as CPU usage, so that tasks can be assigned intelligently rather than by guesswork.
Why Tuning Machine Learning Is So Costly
Machine‑learning models have dials, called hyperparameters, that must be set before training. Examples include how strongly a model penalizes errors, how quickly it learns from new data, or how many internal units it uses. Finding good dial settings often matters more than the choice of model itself. Today, this tuning usually relies on methods that shuffle the data repeatedly (cross‑validation) and explore the hyperparameter landscape with a mix of random guesses, clever search rules, or evolutionary strategies. While powerful, these approaches have two major drawbacks: they inject randomness that makes results hard to reproduce, and they can become extremely time‑consuming, especially for deep neural networks with hundreds of settings.
A More Orderly Way to Search
The authors propose a different strategy called Good Point Set Stepwise Shrinkage, or GPSS. Instead of randomly sampling the space of possible hyperparameters, they use carefully constructed sets of points that spread out evenly, a concept originally developed in number theory. In each stage, GPSS evaluates a batch of these well‑spaced candidates and measures how well the corresponding model predicts CPU performance. It then narrows the search window around the best‑performing region, shrinks the boundaries by a fixed proportion, and generates a new, denser batch of well‑spread points inside this smaller area. Repeating this “coarse‑to‑fine” process gradually homes in on promising hyperparameter combinations without the need for repeated random reshuffling of the data.
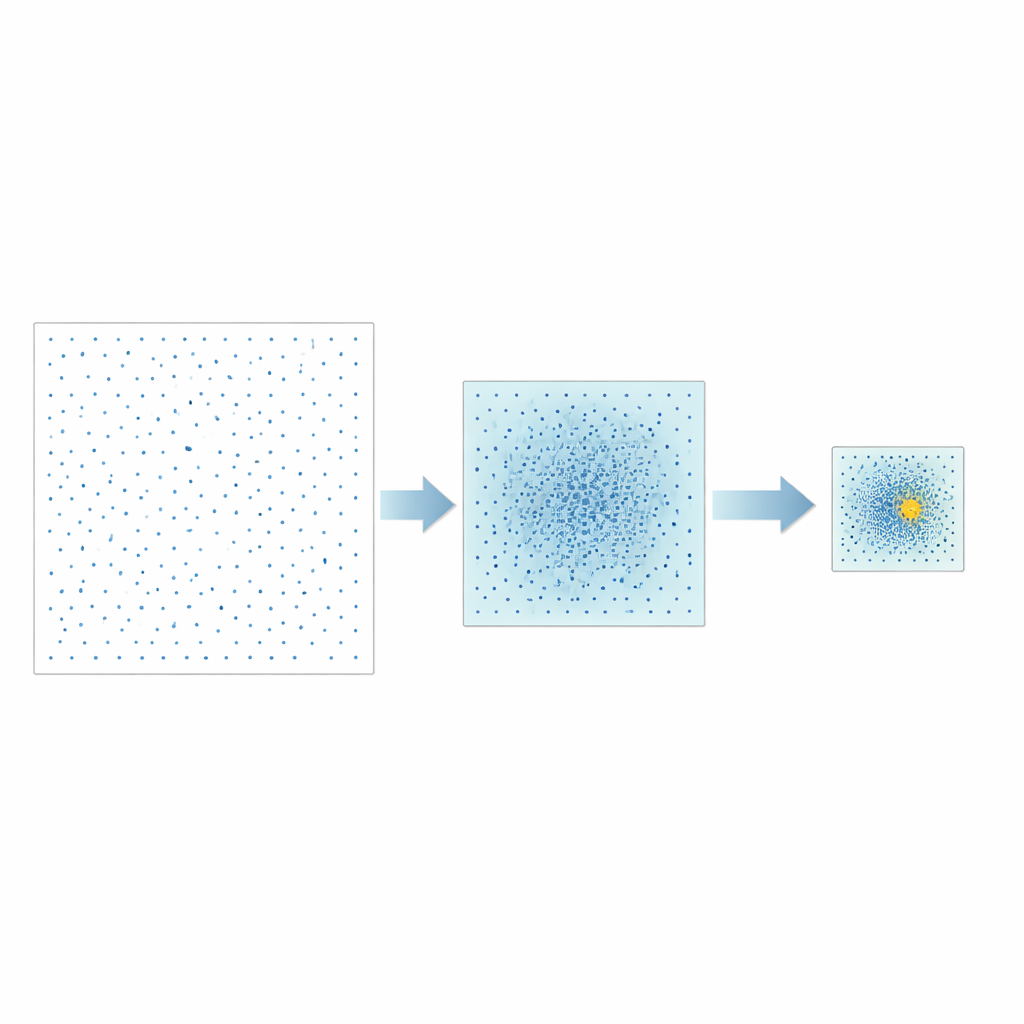
Testing on Different Types of Models
To see how well GPSS works in practice, the team applied it to three popular machine‑learning models: support vector machines, a classic shallow neural network called backpropagation, and a deeper convolutional neural network. All three were trained to predict fog‑node CPU performance from usage data collected in earlier work. GPSS was compared with several established optimization methods, including sequential uniform designs, genetic algorithms, and a swarm‑based technique. The researchers measured both prediction accuracy, using mean squared error, and the time needed for tuning. Across the board, GPSS matched or beat competing methods in accuracy while cutting down on computational cost, and it was the only method practical for the very high‑dimensional convolutional network case.
Making Results More Stable and Reproducible
Beyond raw accuracy, the authors emphasize stability. Because GPSS replaces random sampling with deterministic point sets and uses a structured alternative to traditional cross‑validation, its results vary much less from run to run. In simulations, predictions made by models tuned with GPSS clustered tightly around the true CPU performance, and repeated experiments gave nearly identical outcomes. The method also showed strong global search ability on standard mathematical test problems, indicating that it is unlikely to get stuck in local dead ends when exploring complex hyperparameter spaces.
What This Means for Everyday Connected Tech
In simple terms, this work is about turning the tuning knobs on learning algorithms in a more orderly and efficient way. By replacing trial‑and‑error randomness with evenly spread search points and a steady narrowing of focus, GPSS finds reliable settings that let models predict how busy fog nodes will be. Better predictions mean smarter task scheduling, shorter wait times for apps, and potentially lower energy use in networks of consumer devices. While the authors note limitations—such as difficulties with certain kinds of discrete settings and the need for broader testing—their approach offers a promising blueprint for keeping tomorrow’s ever‑growing web of smart gadgets running smoothly.
Citation: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Keywords: fog computing, hyperparameter optimization, edge machine learning, Internet of Things, performance prediction