Clear Sky Science · es
Un nuevo método de optimización por contracción escalonada de conjuntos de buenos puntos en modelos de aprendizaje automático para la predicción del rendimiento de nodos fog
Dispositivos más inteligentes necesitan un ajuste más inteligente
Desde pulseras de actividad hasta termostatos inteligentes y coches conectados, los aparatos actuales envían constantemente datos al éter digital. Gran parte de esa información se procesa en ordenadores «fog» cercanos, en el borde de la red, en lugar de en centros de datos remotos. Este procesamiento local mantiene las aplicaciones ágiles y reduce la congestión, pero solo si esos nodos fog se utilizan de forma eficiente. El artículo resumido aquí presenta una nueva forma de ajustar modelos de aprendizaje automático para que puedan predecir con mayor precisión el rendimiento de los nodos fog, ayudando a que los dispositivos conectados cotidianos funcionen más rápido, con mayor fluidez y con menos energía desperdiciada.
El desafío de los ordenadores en el borde ocupados
A medida que miles de millones de dispositivos del Internet de las Cosas se conectan, saturan la red con peticiones: lecturas de sensores que analizar, flujos de vídeo que filtrar y señales de control que decidir en tiempo real. La computación fog aborda esto llevando la computación más cerca de la fuente, en máquinas repartidas por hogares, coches, fábricas y calles. Para mantener las latencias bajas, un planificador debe decidir qué nodo fog debe ejecutar cada tarea, y esa decisión depende en gran medida de lo ocupado que esté el procesador de cada nodo y de la rapidez con la que pueda completar una tarea. Los autores se centran en predecir este rendimiento de los nodos a partir de indicadores simples, como el uso de la CPU, para que las tareas se asignen de forma inteligente en lugar de por intuición.
Por qué afinar modelos es tan costoso
Los modelos de aprendizaje automático tienen perillas, llamadas hiperparámetros, que deben fijarse antes del entrenamiento. Ejemplos son cuánto penaliza un modelo los errores, la velocidad con la que aprende de nuevos datos o cuántas unidades internas utiliza. Encontrar buenos valores para esas perillas suele importar más que la elección del propio modelo. Hoy en día, este ajuste suele apoyarse en métodos que reordenan los datos repetidamente (validación cruzada) y exploran el espacio de hiperparámetros con una mezcla de conjeturas aleatorias, reglas de búsqueda sofisticadas o estrategias evolutivas. Aunque potentes, estos enfoques tienen dos desventajas principales: introducen aleatoriedad que dificulta la reproducibilidad y pueden volverse extremadamente lentos, especialmente para redes neuronales profundas con cientos de configuraciones.
Una forma más ordenada de buscar
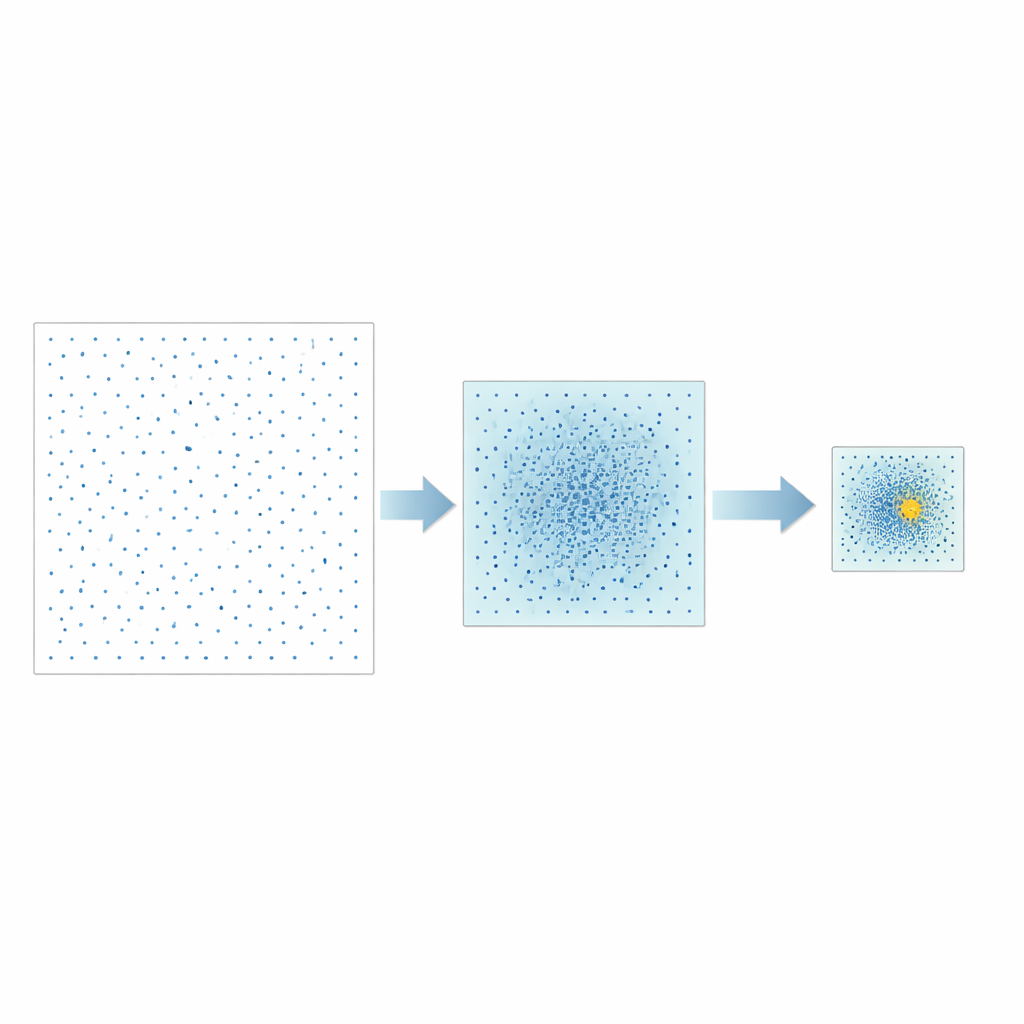
Los autores proponen una estrategia diferente llamada Contracción Escalonada de Conjuntos de Buenos Puntos, o GPSS por sus siglas en inglés. En lugar de muestrear aleatoriamente el espacio de hiperparámetros posibles, emplean conjuntos de puntos cuidadosamente construidos que se distribuyen de forma uniforme, un concepto desarrollado originalmente en teoría de números. En cada etapa, GPSS evalúa un lote de estos candidatos bien espaciados y mide lo bien que el modelo correspondiente predice el rendimiento de la CPU. Luego estrecha la ventana de búsqueda alrededor de la región de mejor rendimiento, reduce los límites en una proporción fija y genera un nuevo lote más denso de puntos bien distribuidos dentro de esa zona más pequeña. Repetir este proceso de «de lo grueso a lo fino» permite acercarse gradualmente a combinaciones prometedoras de hiperparámetros sin necesidad de reordenar aleatoriamente los datos repetidamente.
Pruebas en diferentes tipos de modelos
Para ver cómo funciona GPSS en la práctica, el equipo lo aplicó a tres modelos populares de aprendizaje automático: máquinas de vectores de soporte, una red neuronal poco profunda clásica llamada retropropagación y una red neuronal convolucional más profunda. Los tres se entrenaron para predecir el rendimiento de la CPU de nodos fog a partir de datos de uso recogidos en trabajos anteriores. GPSS se comparó con varios métodos de optimización consolidados, incluidos diseños uniformes secuenciales, algoritmos genéticos y una técnica basada en enjambres. Los investigadores midieron tanto la precisión de la predicción, mediante el error cuadrático medio, como el tiempo necesario para el ajuste. En general, GPSS igualó o superó a los métodos competidores en precisión al mismo tiempo que redujo el coste computacional, y fue el único método práctico para el caso de la red convolucional de muy alta dimensión.
Hacer los resultados más estables y reproducibles
Más allá de la precisión pura, los autores subrayan la estabilidad. Dado que GPSS reemplaza el muestreo aleatorio por conjuntos de puntos deterministas y usa una alternativa estructurada a la validación cruzada tradicional, sus resultados varían mucho menos de una ejecución a otra. En simulaciones, las predicciones realizadas por modelos ajustados con GPSS se agruparon estrechamente alrededor del verdadero rendimiento de la CPU, y los experimentos repetidos arrojaron resultados casi idénticos. El método también mostró una fuerte capacidad de búsqueda global en problemas matemáticos de prueba estándar, lo que indica que es poco probable que quede atrapado en mínimos locales al explorar espacios complejos de hiperparámetros.
Qué significa esto para la tecnología conectada de uso cotidiano
En términos sencillos, este trabajo trata de girar las perillas de los algoritmos de aprendizaje de una forma más ordenada y eficiente. Al sustituir el ensayo y error aleatorio por puntos de búsqueda uniformemente repartidos y una reducción gradual del foco, GPSS encuentra configuraciones fiables que permiten a los modelos predecir cuán ocupados estarán los nodos fog. Mejores predicciones significan una asignación de tareas más inteligente, tiempos de espera más cortos para las aplicaciones y, potencialmente, un menor consumo de energía en redes de dispositivos de consumo. Aunque los autores señalan limitaciones —como dificultades con ciertos tipos de configuraciones discretas y la necesidad de pruebas más amplias—, su enfoque ofrece un plano prometedor para mantener en buen funcionamiento la cada vez mayor red de dispositivos inteligentes del mañana.
Cita: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Palabras clave: computación fog, optimización de hiperparámetros, aprendizaje automático en el borde, Internet de las Cosas, predicción de rendimiento