Clear Sky Science · pl
Nowa metoda optymalizacji stopniowego kurczenia się dobrych punktów w modelach uczenia maszynowego do przewidywania wydajności węzłów fog
Mądrzejsze urządzenia potrzebują mądrzejszego strojenia
Od opasek fitness po inteligentne termostaty i połączone samochody — dzisiejsze urządzenia nieustannie wysyłają dane w cyfrową przestrzeń. Duża część tych informacji jest przetwarzana na pobliskich komputerach „fog” na krawędzi sieci, zamiast w odległych centrach danych. To lokalne przetwarzanie utrzymuje aplikacje responsywnymi i zmniejsza przeciążenia, ale tylko wtedy, gdy węzły fog są wykorzystywane wydajnie. Artykuł streszczony tutaj przedstawia nowy sposób strojenia modeli uczenia maszynowego, dzięki któremu mogą dokładniej przewidywać wydajność węzłów fog, co pomaga urządzeniom codziennego użytku działać szybciej, płynniej i z mniejszym marnotrawstwem energii.
Wyzwanie zajętych komputerów brzegowych
W miarę jak miliardy urządzeń Internetu rzeczy pojawiają się online, zasypują sieć żądaniami: odczytami z czujników do analizowania, strumieniami wideo do filtrowania i sygnałami sterującymi do podejmowania decyzji w czasie rzeczywistym. Przetwarzanie fog radzi sobie z tym, przesuwając obliczenia bliżej źródła, na maszyny rozmieszczone w domach, samochodach, fabrykach i na ulicach miast. Aby utrzymać niskie opóźnienia, harmonogram musi zdecydować, który węzeł fog obsłuży każde zadanie, a decyzja ta zależy w dużej mierze od tego, jak zajęty jest procesor każdego węzła i jak szybko może zakończyć zadanie. Autorzy koncentrują się na przewidywaniu tej wydajności węzłów na podstawie prostych wskaźników, takich jak użycie CPU, tak aby zadania można było przypisywać inteligentnie, a nie metodą prób i błędów.
Dlaczego strojenie uczenia maszynowego jest takie kosztowne
Modele uczenia maszynowego mają pokrętła, zwane hiperparametrami, które należy ustawić przed treningiem. Przykłady to siła karania błędów, tempo uczenia się z nowych danych czy liczba jednostek wewnętrznych. Znalezienie dobrych ustawień tych pokręteł często ma większe znaczenie niż sam wybór modelu. Obecnie strojenie zazwyczaj opiera się na metodach, które wielokrotnie mieszają dane (walidacja krzyżowa) i eksplorują przestrzeń hiperparametrów przez mieszankę losowych prób, sprytnych reguł przeszukiwania lub strategii ewolucyjnych. Choć potężne, podejścia te mają dwie główne wady: wprowadzają losowość utrudniającą reprodukcję wyników i mogą stać się niezwykle czasochłonne, zwłaszcza dla głębokich sieci neuronowych z setkami ustawień.
Bardziej uporządkowany sposób przeszukiwania
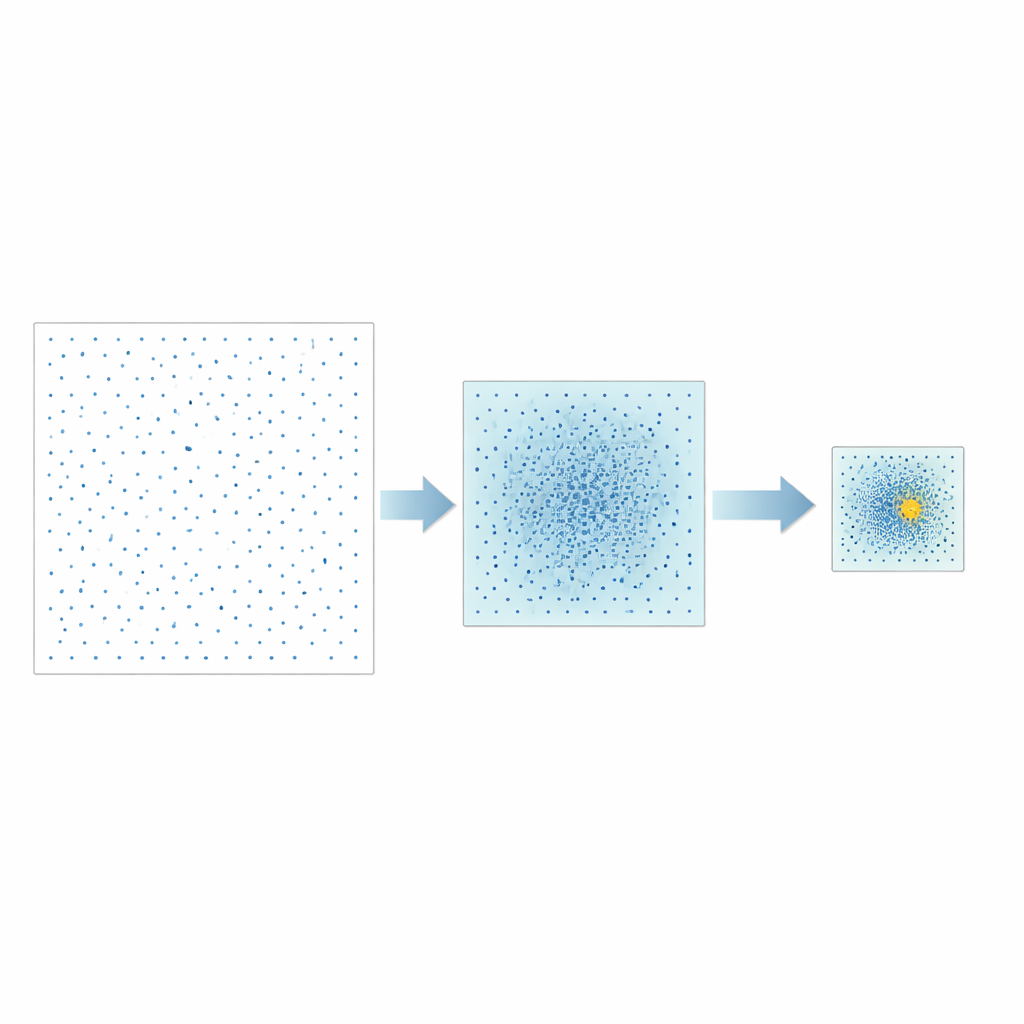
Autorzy proponują inną strategię nazwaną Good Point Set Stepwise Shrinkage, w skrócie GPSS. Zamiast losowo próbkować przestrzeń możliwych hiperparametrów, wykorzystują starannie skonstruowane zbiory punktów rozłożonych równomiernie — koncepcję pierwotnie rozwiniętą w teorii liczb. W każdym etapie GPSS ocenia partię tych dobrze rozmieszczonych kandydatów i mierzy, jak dobrze odpowiadający im model przewiduje wydajność CPU. Następnie zawęża okno przeszukiwania wokół najlepiej działającego obszaru, kurczy granice o stały współczynnik i generuje nową, gęstszą partię równomiernie rozmieszczonych punktów wewnątrz tego mniejszego obszaru. Powtarzanie tego procesu „od ogółu do szczegółu” stopniowo zawęża się na obiecujących kombinacjach hiperparametrów bez konieczności wielokrotnego losowego mieszania danych.
Testowanie na różnych typach modeli
Aby sprawdzić, jak GPSS działa w praktyce, zespół zastosował go do trzech popularnych modeli uczenia maszynowego: maszyn wektorów nośnych, klasycznej płytkiej sieci neuronowej zwanej wsteczną propagacją oraz głębszej konwolucyjnej sieci neuronowej. Wszystkie trzy zostały wytrenowane do przewidywania wydajności CPU węzła fog na podstawie danych o użyciu zebranych w wcześniejszych badaniach. GPSS porównano z kilkoma ugruntowanymi metodami optymalizacji, w tym z sekwencyjnymi jednolitymi projektami, algorytmami genetycznymi oraz techniką opartą na rojach. Naukowcy zmierzyli zarówno dokładność przewidywań (używając średniego błędu kwadratowego), jak i czas potrzebny na strojenie. W całym zestawie GPSS dorównał lub przewyższył metody konkurencyjne pod względem dokładności przy jednoczesnym obniżeniu kosztu obliczeniowego, i był jedyną metodą praktyczną dla bardzo wysokowymiarowego przypadku sieci konwolucyjnej.
Uczynienie wyników bardziej stabilnymi i powtarzalnymi
Ponad samą dokładność autorzy kładą nacisk na stabilność. Ponieważ GPSS zastępuje losowe próbkowanie deterministycznymi zbiorami punktów i stosuje uporządkowaną alternatywę dla tradycyjnej walidacji krzyżowej, jego wyniki zmieniają się znacznie mniej między uruchomieniami. W symulacjach przewidywania dokonywane przez modele strojone za pomocą GPSS skupiały się ciasno wokół rzeczywistej wydajności CPU, a powtarzane eksperymenty dawały niemal identyczne rezultaty. Metoda wykazała także silne zdolności globalnego przeszukiwania na standardowych matematycznych zadaniach testowych, co sugeruje, że ma małe prawdopodobieństwo utknięcia w lokalnych minimach podczas eksploracji złożonych przestrzeni hiperparametrów.
Co to oznacza dla codziennej technologii połączonej
Mówiąc prosto, praca ta dotyczy uporządkowanego i efektywnego ustawiania pokręteł w algorytmach uczących się. Zastępując losowość prób i błędów równomiernie rozłożonymi punktami poszukiwań i systematycznym zawężaniem obszaru, GPSS znajduje wiarygodne ustawienia, które pozwalają modelom przewidywać, jak bardzo zajęte będą węzły fog. Lepsze przewidywania oznaczają mądrzejsze planowanie zadań, krótsze czasy oczekiwania na aplikacje i potencjalnie niższe zużycie energii w sieciach urządzeń konsumenckich. Chociaż autorzy zauważają ograniczenia — takie jak trudności z pewnymi rodzajami dyskretnych ustawień oraz potrzebę szerszego testowania — ich podejście oferuje obiecujący schemat utrzymania rosnącej sieci inteligentnych urządzeń w sprawnym działaniu.
Cytowanie: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Słowa kluczowe: przetwarzanie fog, optymalizacja hiperparametrów, uczenie maszynowe na krawędzi, Internet rzeczy, predykcja wydajności