Clear Sky Science · ru
Новый метод оптимизации пошагового сжатия хороших точечных наборов в модели машинного обучения для предсказания производительности fog‑узлов
Умным устройствам нужна умная настройка
От фитнес‑браслетов до «умных» термостатов и подключённых автомобилей — современные гаджеты постоянно отправляют данные в цифровое пространство. Значительная часть этой информации обрабатывается на близко расположенных «fog»‑компьютерах на границе сети, а не в отдалённых центрах обработки данных. Локальная обработка сохраняет отзывчивость приложений и снижает нагрузку на сеть, но только если fog‑узлы используются эффективно. В статье, кратко изложенной здесь, предложен новый способ настройки моделей машинного обучения, который позволяет точнее предсказывать производительность fog‑узлов, помогая повседневным подключённым устройствам работать быстрее, плавнее и с меньими энергетическими потерями.
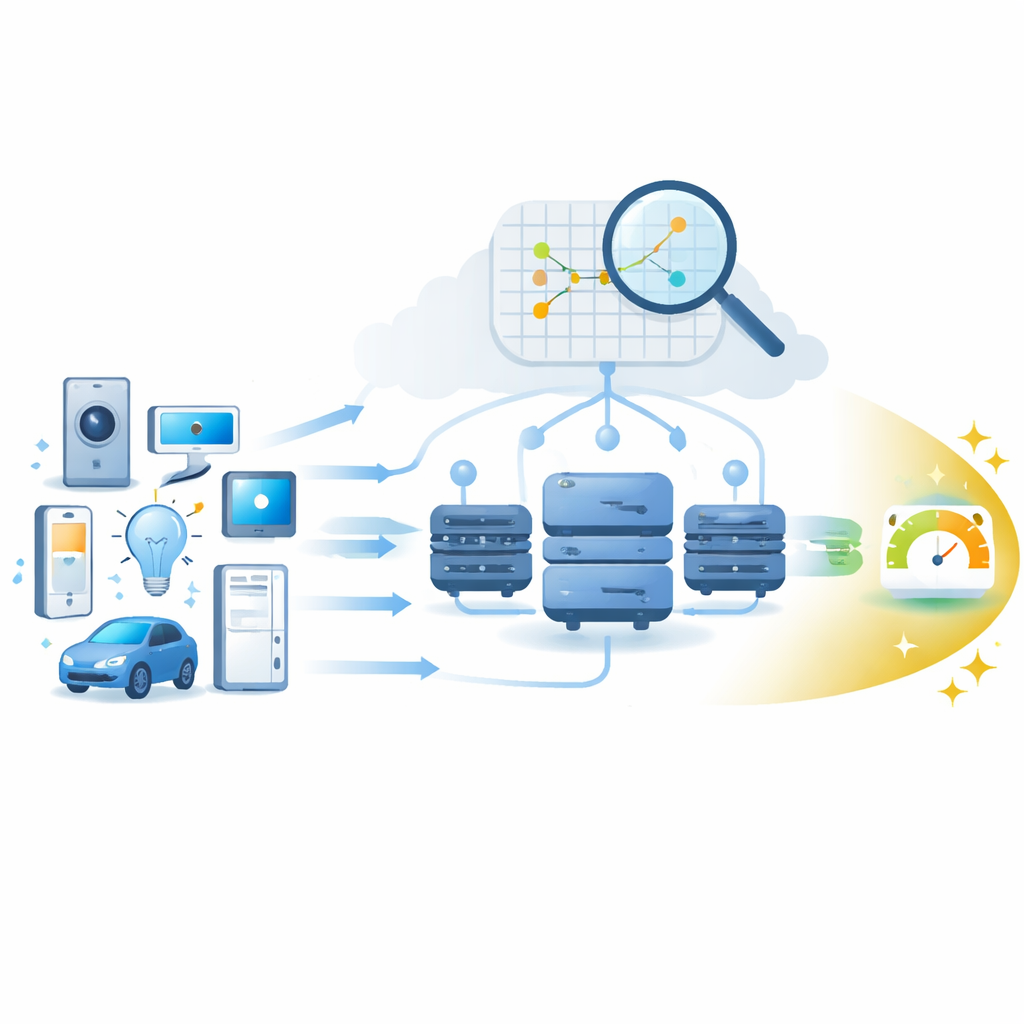
Проблема загруженных пограничных компьютеров
По мере того как в сеть выходит миллиард устройств Интернета вещей, поток запросов увеличивается: данные с датчиков нужно анализировать, видеопотоки фильтровать, а управляющие сигналы — принимать в реальном времени. Fog‑компьютинг решает это, перенося вычисления ближе к источнику — на машины, разбросанные по домам, автомобилям, заводам и улицам городов. Чтобы задержки оставались низкими, планировщик должен решить, какой fog‑узел обработает каждую задачу, и это решение во многом зависит от загрузки процессора узла и того, как быстро он завершит задачу. Авторы сосредоточены на прогнозировании этой производительности узла по простым индикаторам, таким как использование CPU, чтобы задания распределялись осознанно, а не методом проб и ошибок.
Почему настройка машинного обучения так дорога
У моделей машинного обучения есть «регуляторы» — гиперпараметры, которые нужно задать до обучения. Примеры — насколько строго модель штрафует ошибку, с какой скоростью она учится с новых данных или сколько внутренних единиц используется. Поиск хороших значений часто важнее выбора самой модели. Сегодня настройка обычно опирается на методы, многократно перемешивающие данные (кросс‑валидация) и исследующие пространство гиперпараметров с помощью случайных проб, эвристических правил или эволюционных стратегий. Хотя эти подходы мощные, у них два серьёзных недостатка: они вводят случайность, что затрудняет воспроизводимость результатов, и могут требовать огромных затрат времени, особенно для глубоких нейронных сетей с сотнями параметров.
Более упорядоченный способ поиска
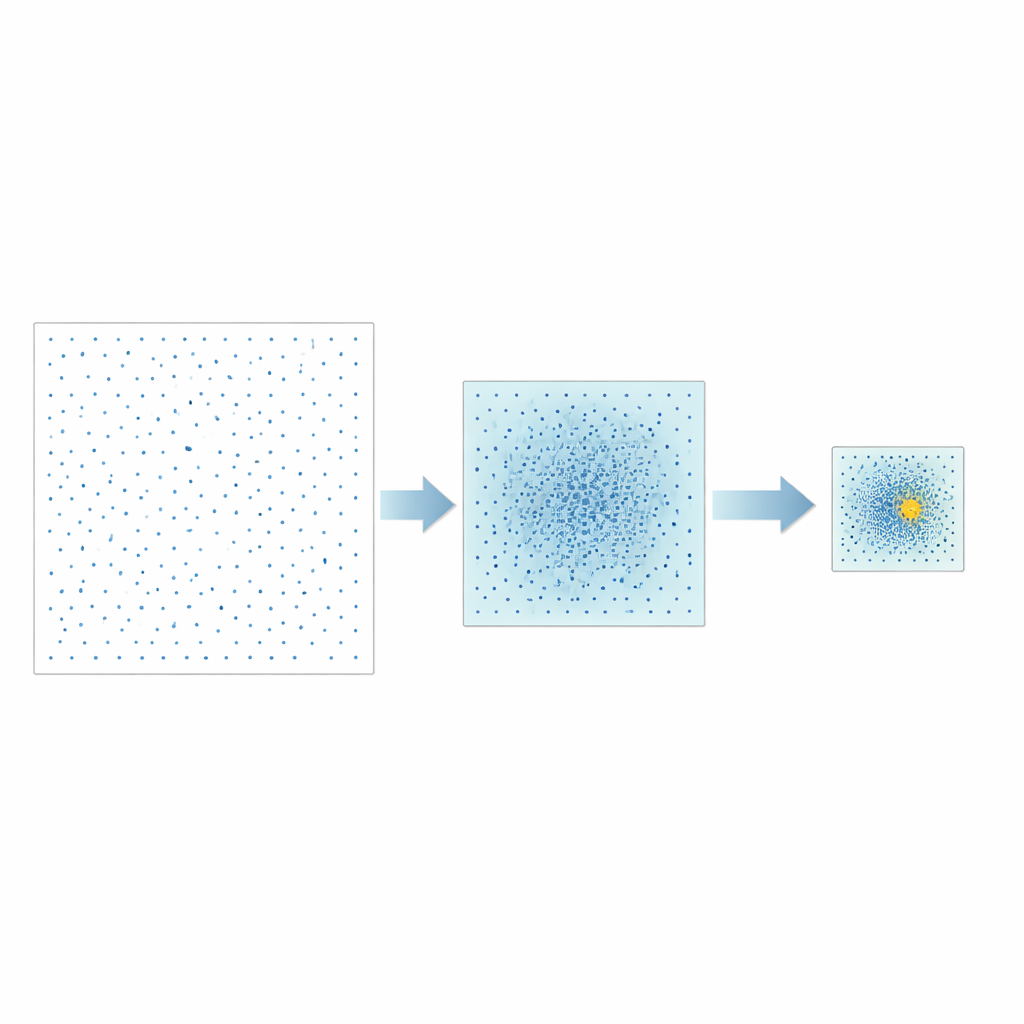
Авторы предлагают иную стратегию, названную Good Point Set Stepwise Shrinkage (GPSS). Вместо случайного выборочного исследования пространства гиперпараметров они используют тщательно сконструированные наборы точек, равномерно распределённые — концепция, изначально разработанная в теории чисел. На каждом этапе GPSS оценивает пакет таких хорошо разнесённых кандидатов и измеряет, насколько хорошо соответствующая модель предсказывает производительность CPU. Затем он сужает область поиска вокруг наилучшей области, уменьшает границы на фиксированную долю и генерирует новый, более плотный пакет равномерно распределённых точек внутри этой меньшей области. Повторяя этот «грубое‑к‑тонкому» процесс, метод постепенно находит перспективные комбинации гиперпараметров без необходимости многократного случайного перемешивания данных.
Тестирование на разных типах моделей
Чтобы оценить эффективность GPSS на практике, команда применяла его к трем популярным моделям машинного обучения: машинам опорных векторов, классической неглубокой нейронной сети с обратным распространением и более глубокой свёрточной нейронной сети. Все три обучались предсказывать производительность CPU fog‑узлов по данным об использовании, собранным в предыдущих работах. GPSS сравнивали с несколькими устоявшимися методами оптимизации, включая последовательные равномерные дизайны, генетические алгоритмы и технику на основе роя агентов. Исследователи измеряли как точность предсказаний (среднеквадратичная ошибка), так и время, необходимое для настройки. Во всех случаях GPSS сравним или превосходил конкурентов по точности при значительном снижении вычислительных затрат, и он оказался единственным практичным методом в высокоразмерном случае свёрточной сети.
Повышение стабильности и воспроизводимости результатов
Помимо точности, авторы подчёркивают важность стабильности. Поскольку GPSS заменяет случайную выборку детерминированными наборами точек и использует структурированную альтернативу традиционной кросс‑валидации, результаты метода гораздо менее вариативны от запуска к запуску. В симуляциях предсказания моделей, настроенных с помощью GPSS, плотно концентрировались вокруг истинной производительности CPU, а повторные эксперименты давали почти идентичные результаты. Метод также показал сильные глобальные поисковые способности на стандартных математических тестовых задачах, что указывает на малую вероятность «застревания» в локальных оптимумах при исследовании сложных пространств гиперпараметров.
Что это значит для повседневной подключённой техники
Проще говоря, эта работа посвящена более упорядоченному и эффективному способу настройки регуляторов алгоритмов обучения. Заменяя случайный перебор равномерно распределёнными точками поиска и постепенным сужением области, GPSS находит надёжные настройки, позволяющие моделям предсказывать загрузку fog‑узлов. Лучшие предсказания означают более разумное планирование задач, меньшие задержки для приложений и потенциально более низкое энергопотребление в сетях пользовательских устройств. Хотя авторы отмечают ограничения — например, сложности с некоторыми типами дискретных настроек и необходимость более широкого тестирования — их подход предлагает перспективную методику для поддержания эффективной работы всё растущей сети умных устройств будущего.
Цитирование: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Ключевые слова: fog‑компьютинг, оптимизация гиперпараметров, edge‑машинное обучение, Интернет вещей, прогнозирование производительности