Clear Sky Science · it
Una nuova ottimizzazione per la riduzione graduale basata su insiemi di buoni punti nei modelli di machine learning per la previsione delle prestazioni dei nodi fog
Dispositivi più intelligenti richiedono una messa a punto più intelligente
Dai fitness tracker ai termostati smart e alle auto connesse, i dispositivi odierni inviano costantemente dati nel mondo digitale. Gran parte di queste informazioni viene elaborata su computer «fog» vicini, ai margini della rete, anziché in lontani data center. Questa elaborazione locale mantiene le app reattive e riduce la congestione, ma soltanto se i nodi fog vengono utilizzati in modo efficiente. Il lavoro qui riassunto introduce un nuovo modo di ottimizzare i modelli di machine learning in modo che possano prevedere con maggiore precisione le prestazioni dei nodi fog, aiutando i dispositivi connessi di uso quotidiano a funzionare più velocemente, più fluidamente e con meno sprechi energetici.
La sfida dei computer edge affollati
Con miliardi di dispositivi Internet of Things connessi, la rete viene sommersa da richieste: letture di sensori da analizzare, flussi video da filtrare e segnali di controllo da decidere in tempo reale. Il fog computing affronta questo spostando il calcolo più vicino alla fonte, su macchine sparse in case, auto, fabbriche e strade cittadine. Per mantenere basse le latenze, uno scheduler deve decidere quale nodo fog debba gestire ogni attività, e tale decisione dipende fortemente da quanto è occupato il processore di ciascun nodo e da quanto rapidamente può completare un compito. Gli autori si concentrano sulla previsione di queste prestazioni dei nodi a partire da indicatori semplici come l'utilizzo della CPU, in modo che i compiti possano essere assegnati in modo intelligente anziché per tentativi.
Perché la messa a punto del machine learning è così costosa
I modelli di machine learning hanno delle manopole, chiamate iperparametri, che devono essere impostate prima dell'addestramento. Esempi includono quanto fortemente un modello penalizza gli errori, quanto velocemente apprende da nuovi dati o quanti elementi interni utilizza. Trovare buone impostazioni spesso conta più della scelta del modello stesso. Oggi questa messa a punto si basa solitamente su metodi che rimescolano ripetutamente i dati (cross‑validation) ed esplorano lo spazio degli iperparametri con una combinazione di tentativi casuali, regole di ricerca intelligenti o strategie evolutive. Pur essendo potenti, questi approcci hanno due grandi svantaggi: introducono casualità che rende i risultati difficili da riprodurre e possono diventare estremamente dispendiosi in termini di tempo, soprattutto per reti neurali profonde con centinaia di parametri.
Un modo di ricerca più ordinato
Gli autori propongono una strategia diversa chiamata Good Point Set Stepwise Shrinkage, o GPSS. Invece di campionare casualmente lo spazio degli iperparametri, utilizzano insiemi di punti costruiti con cura che si distribuiscono in modo uniforme, un concetto sviluppato originariamente nella teoria dei numeri. In ogni fase, GPSS valuta un lotto di questi candidati ben distanziati e misura quanto bene il modello corrispondente predice le prestazioni della CPU. Quindi restringe la finestra di ricerca attorno alla regione con le migliori prestazioni, riduce i confini di una proporzione fissa e genera un nuovo lotto, più denso, di punti ben distribuiti all'interno di quest'area più piccola. Ripetendo questo processo «dal grosso al fine», si individua gradualmente combinazioni promettenti di iperparametri senza la necessità di rimescolare casualmente i dati più volte.
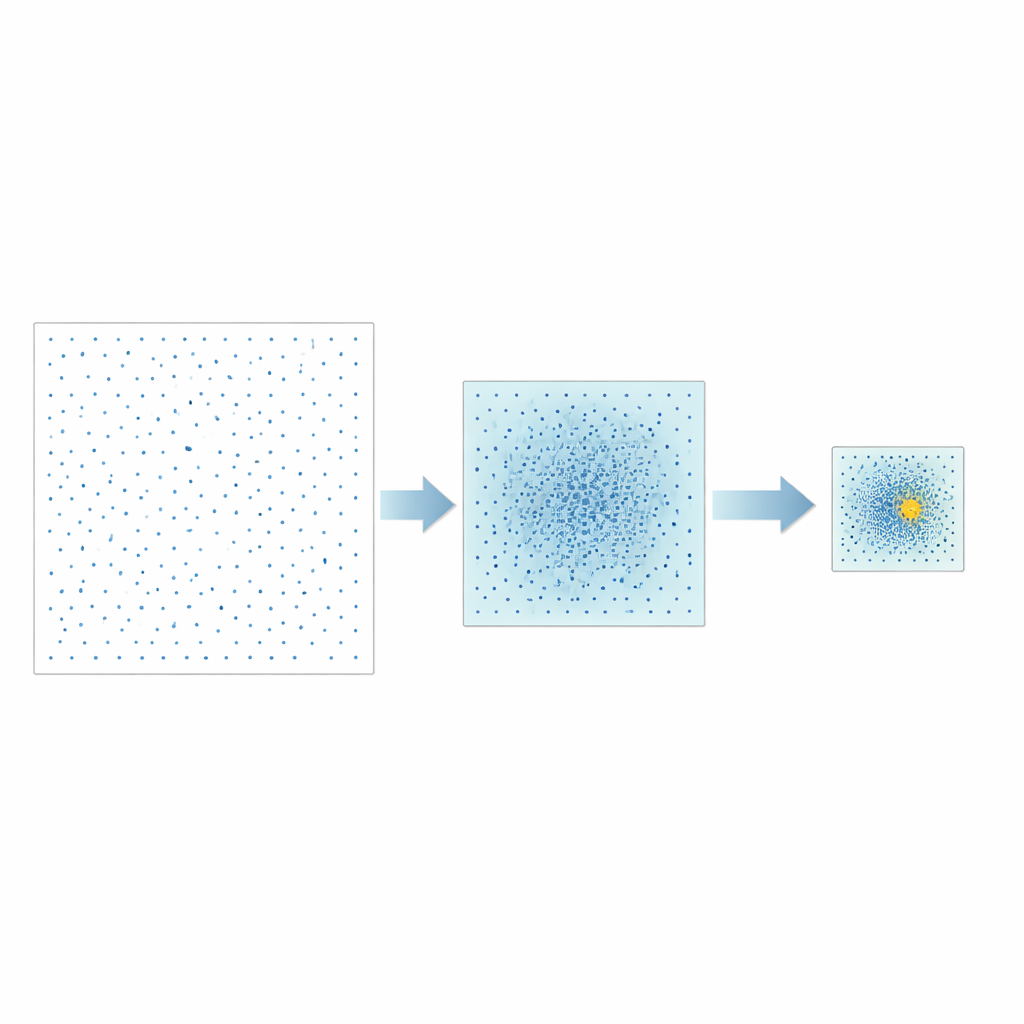
Test su diversi tipi di modelli
Per verificare l'efficacia di GPSS nella pratica, il team lo ha applicato a tre modelli di machine learning popolari: macchine a vettori di supporto (SVM), una classica rete neurale poco profonda chiamata backpropagation e una rete neurale convoluzionale più profonda. Tutti e tre sono stati addestrati a prevedere le prestazioni della CPU dei nodi fog a partire da dati di utilizzo raccolti in lavori precedenti. GPSS è stato confrontato con diversi metodi di ottimizzazione consolidati, inclusi disegni sequenziali uniformi, algoritmi genetici e una tecnica basata su sciami. I ricercatori hanno misurato sia l'accuratezza delle previsioni, usando l'errore quadratico medio, sia il tempo necessario per la messa a punto. In tutti i casi, GPSS ha eguagliato o superato i metodi concorrenti in termini di accuratezza riducendo al contempo il costo computazionale, ed è stato l'unico metodo praticabile per il caso ad altissima dimensionalità della rete convoluzionale.
Rendere i risultati più stabili e riproducibili
Oltre all'accuratezza pura, gli autori sottolineano la stabilità. Poiché GPSS sostituisce il campionamento casuale con insiemi di punti deterministici e usa un'alternativa strutturata alla tradizionale cross‑validation, i suoi risultati variano molto meno da esecuzione a esecuzione. Nelle simulazioni, le previsioni dei modelli ottimizzati con GPSS si sono raggruppate strettamente attorno alle prestazioni reali della CPU e esperimenti ripetuti hanno fornito risultati quasi identici. Il metodo ha anche mostrato una forte capacità di ricerca globale su problemi matematici di test standard, indicando che è improbabile che rimanga bloccato in minimi locali quando esplora spazi di iperparametri complessi.
Cosa significa per la tecnologia connessa di tutti i giorni
In termini semplici, questo lavoro riguarda la regolazione delle manopole degli algoritmi di apprendimento in modo più ordinato ed efficiente. Sostituendo la casualità del tentativi‑ed‑errore con punti di ricerca uniformemente distribuiti e un progressivo restringimento del campo, GPSS trova impostazioni affidabili che permettono ai modelli di prevedere quanto saranno occupati i nodi fog. Previsioni migliori significano schedulazione dei compiti più intelligente, tempi di attesa più brevi per le app e potenzialmente un uso energetico inferiore nelle reti di dispositivi consumer. Pur riconoscendo limiti — come difficoltà con alcuni tipi di impostazioni discrete e la necessità di test più ampi — l'approccio proposto offre un promettente progetto per mantenere fluido il funzionamento della sempre crescente rete di dispositivi intelligenti di domani.
Citazione: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Parole chiave: fog computing, ottimizzazione degli iperparametri, machine learning per l'edge, Internet of Things, previsione delle prestazioni