Clear Sky Science · sv
En ny Good Point Set-stepvis krympningsoptimering i maskininlärningsmodell för prestandaförutsägelse av fog-noder
Smartare enheter behöver smartare justering
Från aktivitetsarmband till smarta termostater och uppkopplade bilar skickar dagens prylar ständigt data ut i den digitala etern. Mycket av den informationen bearbetas på närliggande "fog"‑datorer i nätverkets kant i stället för i avlägsna datacenter. Denna lokala bearbetning håller appar snabba och minskar trängsel, men bara om fog‑noderna används effektivt. Artikeln som sammanfattas här introducerar ett nytt sätt att finjustera maskininlärningsmodeller så att de bättre kan förutsäga hur väl fog‑noder presterar, vilket hjälper vardagliga uppkopplade enheter att bli snabbare, mjukare och mindre energislösande.
Utmaningen med upptagna kantdatorer
När miljarder sakernas internet‑enheter kopplas upp översvämmas nätverket av förfrågningar: sensormätningar att analysera, videoströmmar att filtrera och styrsignaler att fatta beslut om i realtid. Fog computing hanterar detta genom att flytta beräkning närmare källan, på maskiner utspridda i hem, bilar, fabriker och på gatorna. För att hålla fördröjningar låga måste en schemaläggare avgöra vilken fog‑nod som ska hantera varje jobb, och det valet beror starkt på hur belastad varje nods processor är och hur snabbt den kan slutföra en uppgift. Författarna fokuserar på att förutsäga nodernas prestanda från enkla indikatorer som CPU‑användning, så att uppgifter kan tilldelas intelligent i stället för på måfå.
Varför justering av maskininlärning är så kostsamt
Maskininlärningsmodeller har rattar, så kallade hyperparametrar, som måste ställas in före träning. Exempel är hur starkt en modell straffar fel, hur snabbt den lär sig från ny data eller hur många interna enheter den använder. Att hitta bra inställningar för dessa rattar spelar ofta större roll än själva modellvalet. I dag förlitar sig denna justering vanligtvis på metoder som blandar om data upprepade gånger (cross‑validation) och utforskar hyperparameterlandskapet med en kombination av slumpmässiga gissningar, smarta sökregler eller evolutionära strategier. Trots sin styrka har dessa tillvägagångssätt två stora nackdelar: de inför slumpmässighet som gör resultat svåra att reproducera, och de kan bli extremt tidskrävande, särskilt för djupa neurala nätverk med hundratals inställningar.
Ett mer ordnat sätt att söka
Författarna föreslår en annan strategi kallad Good Point Set Stepwise Shrinkage, eller GPSS. I stället för att slumpmässigt provta utrymmet av möjliga hyperparametrar använder de omsorgsfullt konstruerade punktmängder som sprider sig jämnt, ett begrepp som ursprungligen utvecklades inom talteori. I varje steg utvärderar GPSS en sats av dessa välavståndade kandidater och mäter hur bra motsvarande modell förutsäger CPU‑prestanda. Metoden smalnar sedan av sökfönstret runt den bäst presterande regionen, krymper gränserna med en fast proportion och genererar en ny, tätare uppsättning välspridda punkter inom detta mindre område. Genom att upprepa denna "grovt‑till‑fint"‑process inriktar man sig gradvis på lovande hyperparameterkombinationer utan behov av upprepad slumpmässig omblandning av data.
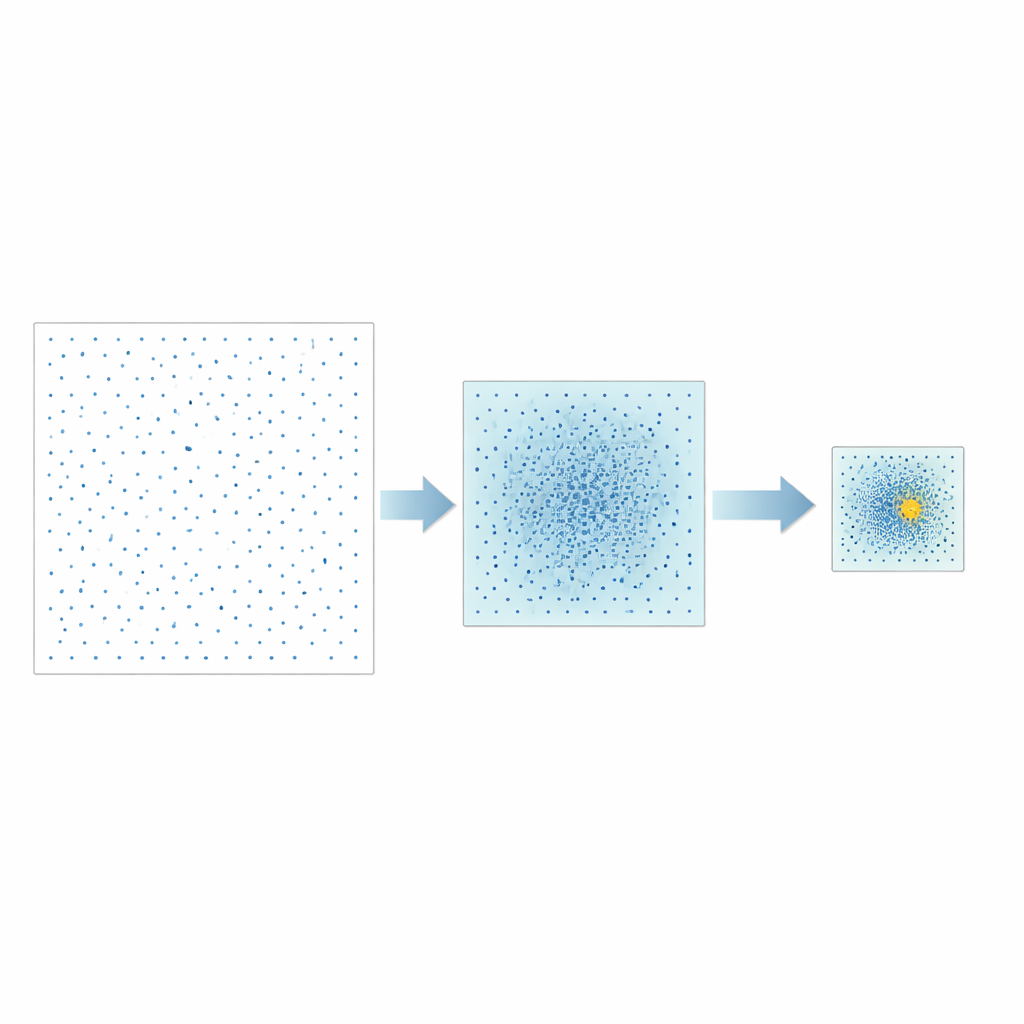
Testning på olika modelltyper
För att se hur väl GPSS fungerar i praktiken använde teamet metoden på tre populära maskininlärningsmodeller: support vector machines, ett klassiskt grunt neuralt nätverk kallat backpropagation, och ett djupare konvolutionellt neuralt nätverk. Alla tre tränades för att förutsäga fog‑noders CPU‑prestanda från användningsdata insamlade i tidigare arbete. GPSS jämfördes med flera etablerade optimeringsmetoder, inklusive sekventiella uniforma designer, genetiska algoritmer och en svärmbaserad teknik. Forskarna mätte både förutsägelseprecision, med hjälp av medelkvadratfelet, och den tid som krävdes för justering. Överlag matchade eller överträffade GPSS konkurrerande metoder i noggrannhet samtidigt som den minskade beräkningskostnaden, och den var den enda metoden som var praktisk för det mycket högdimensionella fallet med det konvolutionella nätverket.
Göra resultaten mer stabila och reproducerbara
Bortom ren noggrannhet betonar författarna stabilitet. Eftersom GPSS ersätter slumpmässig provtagning med deterministiska punktmängder och använder ett strukturerat alternativ till traditionell cross‑validation varierar dess resultat mycket mindre mellan körningar. I simuleringar klustrade förutsägelser gjorda av modeller justerade med GPSS sig tätt kring den verkliga CPU‑prestandan, och upprepade experiment gav nästan identiska utfall. Metoden visade också stark förmåga att söka globalt på standardiserade matematiska testproblem, vilket tyder på att den inte lätt fastnar i lokala dödpunkter när den utforskar komplexa hyperparameterutrymmen.
Vad detta betyder för vardaglig uppkopplad teknik
Enkelt uttryckt handlar detta arbete om att vrida på justeringsknapparna på inlärningsalgoritmer på ett mer ordnat och effektivt sätt. Genom att ersätta försök‑och‑fel‑slump med jämt utspridda sökpunkter och en stadig insmaltning av fokus hittar GPSS pålitliga inställningar som gör att modeller kan förutsäga hur upptagna fog‑noder kommer att vara. Bättre förutsägelser innebär smartare uppgiftsschemaläggning, kortare väntetider för appar och potentiellt lägre energianvändning i nätverk av konsumtionsenheter. Medan författarna noterar begränsningar — såsom svårigheter med vissa typer av diskreta inställningar och behovet av bredare testning — erbjuder deras angreppssätt en lovande mall för att hålla morgondagens ständigt växande nät av smarta prylar fungerande smidigt.
Citering: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Nyckelord: fog computing, hyperparameteroptimering, edge machine learning, Internet of Things, prestandaförutsägelse