Clear Sky Science · de
Ein neuer Good-Point-Set-Stepwise-Shrinkage-Optimierungsansatz im maschinellen Lernen zur Leistungsprognose von Fog-Knoten
Schlauere Geräte brauchen schlauere Abstimmung
Von Fitness-Trackern über smarte Thermostate bis zu vernetzten Autos senden heutige Geräte ständig Daten in die digitale Sphäre. Ein Großteil dieser Informationen wird nicht in weit entfernten Rechenzentren, sondern auf nahegelegenen „Fog“-Rechnern am Rand des Netzwerks verarbeitet. Diese lokale Verarbeitung hält Apps reaktionsschnell und reduziert Staus, aber nur, wenn die Fog-Knoten effizient genutzt werden. Die hier zusammengefasste Arbeit stellt eine neue Methode vor, um maschinelle Lernmodelle so zu optimieren, dass sie die Leistung von Fog-Knoten genauer vorhersagen können — damit gängige vernetzte Geräte schneller, flüssiger und mit weniger Energieverschwendung laufen.
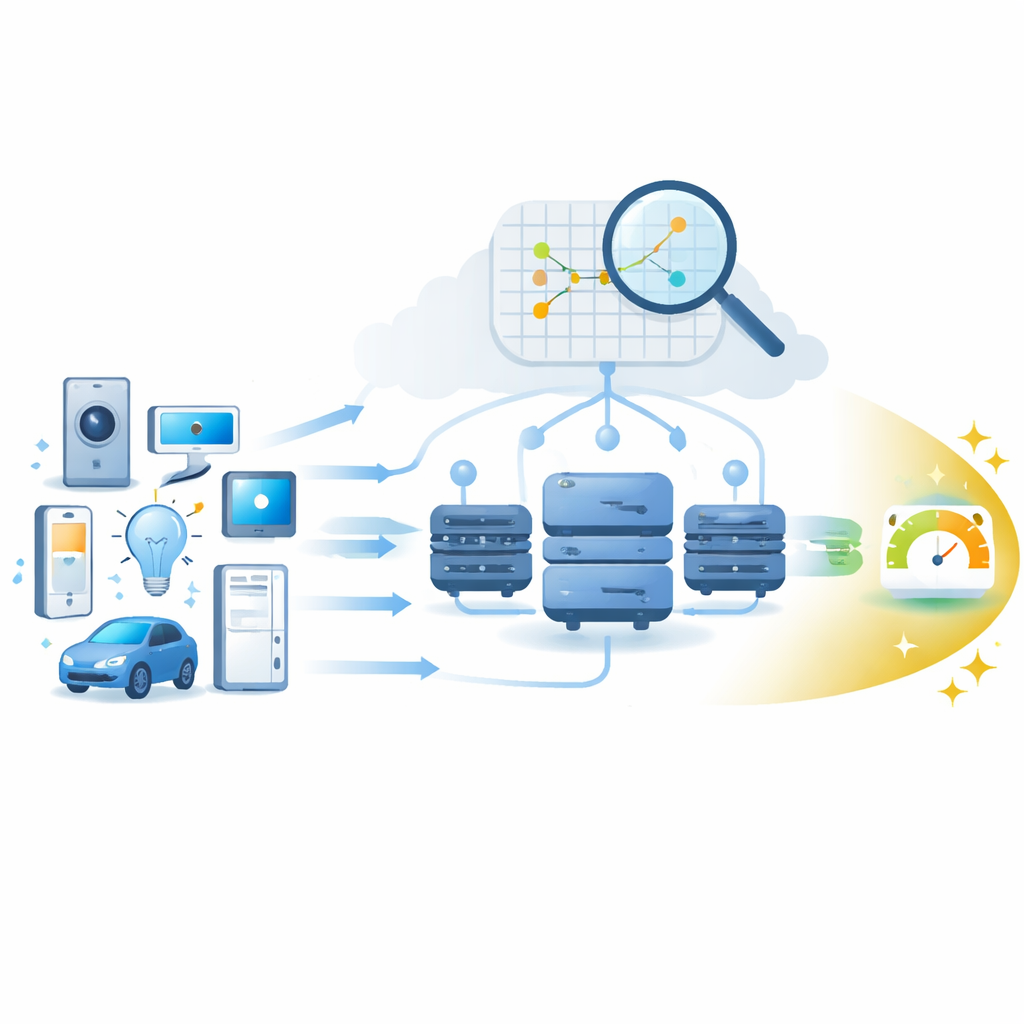
Die Herausforderung bei ausgelasteten Edge-Computern
Mit dem Anschluss von Milliarden IoT-Geräten überschwemmen sie das Netzwerk mit Anfragen: Sensordaten zur Analyse, Videoströme zur Filterung und Steuerbefehle, die in Echtzeit entschieden werden müssen. Fog Computing begegnet dem, indem es Berechnungen näher an die Quelle verlagert — auf Maschinen, die in Häusern, Autos, Fabriken und an Straßenrändern verteilt sind. Um Verzögerungen gering zu halten, muss ein Scheduler entscheiden, welcher Fog-Knoten welche Aufgabe übernimmt; diese Entscheidung hängt stark davon ab, wie ausgelastet die Prozessoren der Knoten sind und wie schnell sie eine Aufgabe abarbeiten können. Die Autoren konzentrieren sich darauf, diese Knotenauslastung aus einfachen Indikatoren wie CPU-Auslastung vorherzusagen, damit Aufgaben intelligent statt nach Bauchgefühl zugewiesen werden.
Warum das Tuning von ML so kostenintensiv ist
Maschinelle Lernmodelle haben Stellschrauben, sogenannte Hyperparameter, die vor dem Training festgelegt werden müssen. Beispiele sind, wie stark ein Modell Fehler bestraft, wie schnell es aus neuen Daten lernt oder wie viele interne Einheiten es verwendet. Gute Einstellungen dieser Stellschrauben sind oft wichtiger als die Wahl des Modells selbst. Heute basiert dieses Tuning meist auf Methoden, die die Daten wiederholt durchmischen (Cross‑Validation) und die Hyperparameter-Landschaft mit einer Mischung aus Zufallsversuchen, geschickten Suchregeln oder evolutionären Strategien erkunden. Zwar leistungsfähig, haben diese Ansätze zwei wesentliche Nachteile: Sie führen Zufälligkeit ein, die Ergebnisse schwer reproduzierbar macht, und sie können extrem zeitaufwendig werden, besonders bei tiefen neuronalen Netzen mit Hunderten von Einstellungen.
Eine geordneterer Suchweg
Die Autoren schlagen eine andere Strategie vor, genannt Good Point Set Stepwise Shrinkage, kurz GPSS. Statt den Raum möglicher Hyperparameter zufällig zu beproben, verwenden sie sorgfältig konstruierte Punktmengen, die sich gleichmäßig verteilen — ein Konzept, das ursprünglich in der Zahlentheorie entwickelt wurde. In jeder Stufe bewertet GPSS eine Charge dieser gut verteilten Kandidaten und misst, wie gut das entsprechende Modell die CPU-Leistung vorhersagt. Anschließend verengt es das Suchfenster um die leistungsstärkste Region, verkleinert die Grenzen um einen festen Anteil und generiert innerhalb dieses kleineren Bereichs eine neue, dichtere Charge gleichmäßig verteilter Punkte. Durch Wiederholung dieses „grob-zu-fein“-Prozesses nähert sich die Suche schrittweise vielversprechenden Hyperparameter-Kombinationen an, ohne wiederholtes zufälliges Neuaufrollen der Daten zu benötigen.
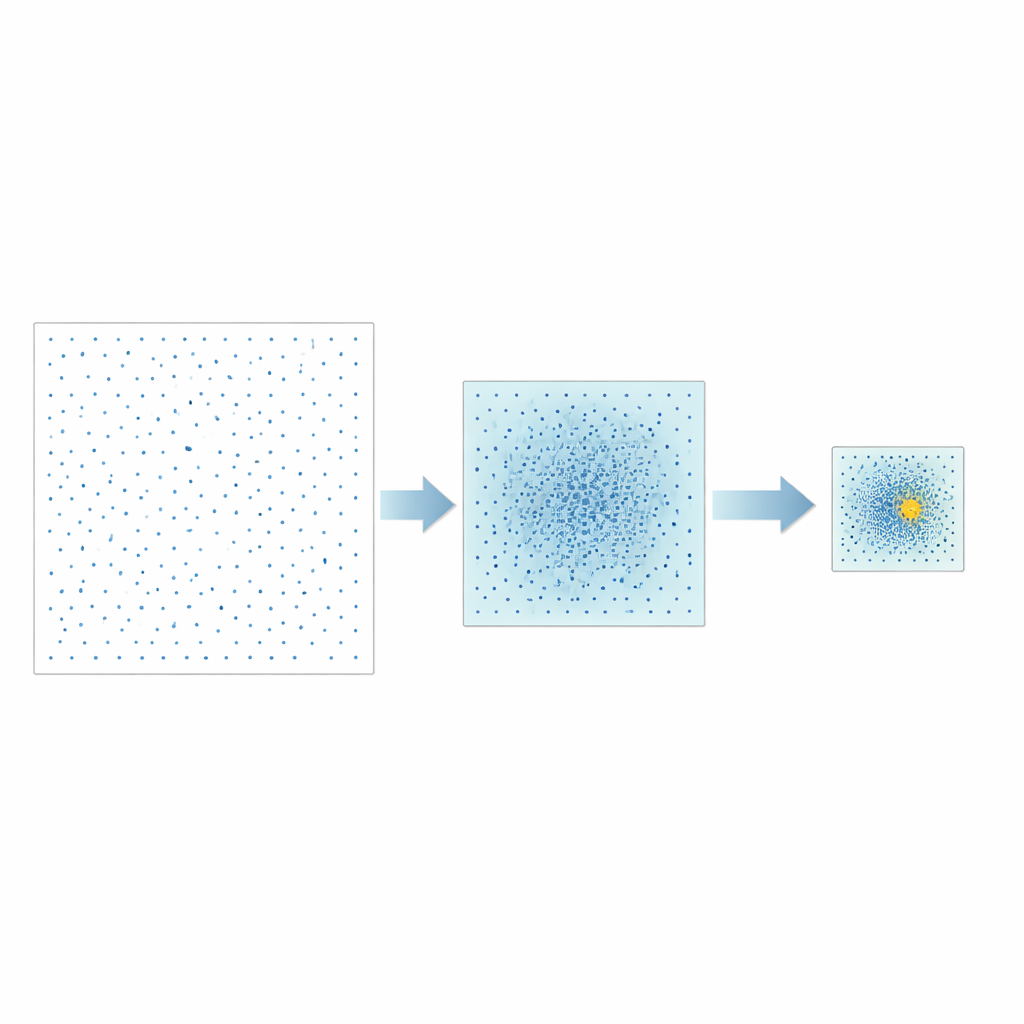
Test an verschiedenen Modelltypen
Um die Praxistauglichkeit von GPSS zu prüfen, wandte das Team es auf drei verbreitete Modelle des maschinellen Lernens an: Support-Vektor-Maschinen, ein klassisches flaches neuronales Netz mit Rückpropagation und ein tieferes konvolutionales neuronales Netz. Alle drei wurden darauf trainiert, die CPU-Leistung von Fog-Knoten aus zuvor erhobenen Nutzungsdaten vorherzusagen. GPSS wurde mit mehreren etablierten Optimierungsmethoden verglichen, darunter sequentielle gleichverteilte Designs, genetische Algorithmen und eine schwarmbasierte Technik. Die Forschenden maßen sowohl die Vorhersagegenauigkeit (mittlere quadratische Abweichung) als auch die für das Tuning benötigte Zeit. Insgesamt erreichte GPSS bei der Genauigkeit gleichwertige oder bessere Ergebnisse als konkurrierende Methoden und reduzierte gleichzeitig die Rechenkosten; außerdem war es die einzige praktikable Methode für den sehr hochdimensionalen Fall des konvolutionalen Netzwerks.
Stabilere und besser reproduzierbare Ergebnisse
Über die reine Genauigkeit hinaus betonen die Autoren die Stabilität. Da GPSS das zufällige Sampling durch deterministische Punktmengen ersetzt und eine strukturierte Alternative zur herkömmlichen Cross‑Validation nutzt, schwanken die Ergebnisse deutlich weniger von Lauf zu Lauf. In Simulationen konzentrierten sich die Vorhersagen von mit GPSS getunten Modellen eng um die tatsächliche CPU-Leistung, und wiederholte Experimente ergaben nahezu identische Resultate. Die Methode zeigte außerdem starke globale Sucheigenschaften bei standardisierten mathematischen Testproblemen, was darauf hindeutet, dass sie beim Erkunden komplexer Hyperparameter-Räume vermutlich nicht leicht in lokalen Sackgassen hängenbleibt.
Was das für alltägliche vernetzte Technik bedeutet
Vereinfacht gesagt geht es in dieser Arbeit darum, die Einstellungsregler von Lernalgorithmen geordneter und effizienter zu drehen. Indem Zufall durch gleichmäßig verteilte Suchpunkte und ein stetiges Verengen des Fokus ersetzt wird, findet GPSS zuverlässige Einstellungen, mit denen Modelle vorhersagen können, wie ausgelastet Fog-Knoten sind. Bessere Vorhersagen bedeuten intelligentere Aufgabenplanung, kürzere Wartezeiten für Anwendungen und potenziell geringeren Energieverbrauch in Netzwerken von Alltagsgeräten. Zwar weisen die Autoren auch auf Einschränkungen hin — etwa Schwierigkeiten bei bestimmten Arten diskreter Einstellungen und den Bedarf an breiterer Erprobung —, doch ihr Ansatz bietet einen vielversprechenden Bauplan, damit das künftig immer weiter wachsende Netz smarter Geräte reibungslos läuft.
Zitation: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Schlüsselwörter: Fog-Computing, Hyperparameter-Optimierung, Edge-Machine-Learning, Internet der Dinge, Leistungsprognose