Clear Sky Science · pt
Uma nova otimização por contração escalonada de conjunto de bons pontos em modelos de aprendizado de máquina para previsão de desempenho de nós de fog
Dispositivos mais inteligentes precisam de ajuste mais inteligente
De rastreadores de atividade a termostatos inteligentes e carros conectados, os aparelhos de hoje enviam dados constantemente para o éter digital. Grande parte dessa informação é processada em computadores "fog" próximos, na borda da rede, em vez de em centros de dados distantes. Esse processamento local mantém os aplicativos responsivos e reduz a congestão, mas somente se esses nós de fog forem usados com eficiência. O artigo resumido aqui apresenta uma nova forma de ajustar modelos de aprendizado de máquina para que possam prever com mais precisão o desempenho dos nós de fog, ajudando dispositivos conectados do dia a dia a rodar mais rápido, mais suave e com menos desperdício de energia.
O desafio dos computadores de borda sobrecarregados
À medida que bilhões de dispositivos da Internet das Coisas entram em operação, eles inundam a rede com solicitações: leituras de sensores para analisar, fluxos de vídeo para filtrar e sinais de controle para decidir em tempo real. A computação em fog enfrenta isso levando o processamento para mais perto da fonte, em máquinas espalhadas por casas, carros, fábricas e vias públicas. Para manter os atrasos baixos, um escalonador precisa decidir qual nó de fog deve tratar cada tarefa, e essa decisão depende muito de quão ocupada está a CPU de cada nó e de quão rápido ele pode concluir um trabalho. Os autores concentram‑se em prever esse desempenho do nó a partir de indicadores simples, como uso de CPU, para que as tarefas possam ser atribuídas de forma inteligente em vez de por tentativa e erro.
Por que ajustar aprendizado de máquina é tão custoso
Modelos de aprendizado de máquina têm botões, chamados hiperparâmetros, que devem ser definidos antes do treinamento. Exemplos incluem o quanto um modelo penaliza erros, quão rapidamente ele aprende com novos dados ou quantas unidades internas utiliza. Encontrar boas configurações desses botões frequentemente é mais importante do que a escolha do próprio modelo. Hoje, esse ajuste geralmente depende de métodos que embaralham os dados repetidamente (validação cruzada) e exploram o espaço de hiperparâmetros com uma mistura de palpites aleatórios, regras de busca inteligentes ou estratégias evolutivas. Embora poderosas, essas abordagens têm duas desvantagens principais: introduzem aleatoriedade que torna os resultados difíceis de reproduzir e podem se tornar extremamente demoradas, especialmente para redes neurais profundas com centenas de parâmetros.
Uma forma mais ordenada de buscar
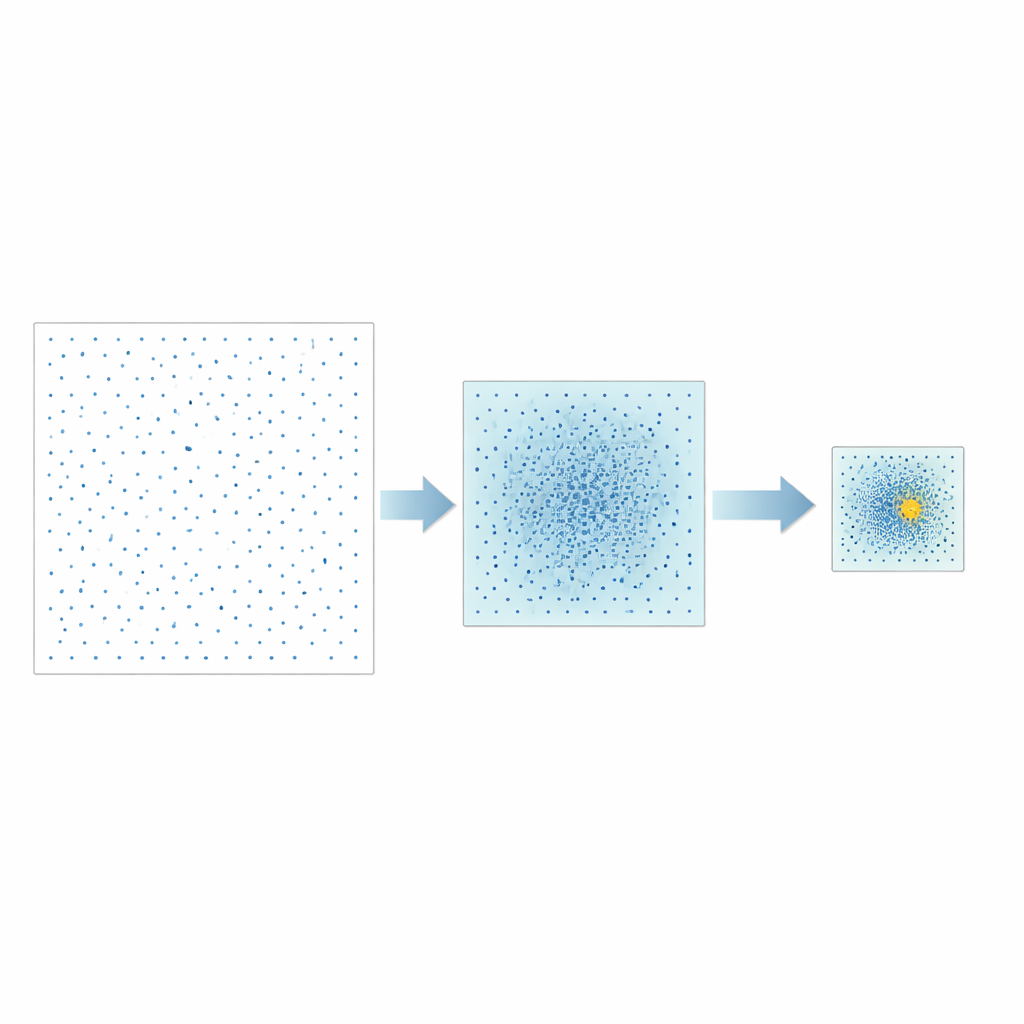
Os autores propõem uma estratégia diferente chamada Conjunto de Bons Pontos com Contração Escalonada, ou GPSS (Good Point Set Stepwise Shrinkage). Em vez de amostrar aleatoriamente o espaço de hiperparâmetros, eles usam conjuntos de pontos cuidadosamente construídos que se espalham de forma uniforme, um conceito originalmente desenvolvido na teoria dos números. Em cada etapa, o GPSS avalia um lote desses candidatos bem espaçados e mede quão bem o modelo correspondente prevê o desempenho da CPU. Em seguida, estreita a janela de busca ao redor da região de melhor desempenho, reduz as fronteiras por uma proporção fixa e gera um novo lote, mais denso, de pontos bem distribuídos dentro dessa área menor. Repetir esse processo "do grosso ao fino" aproxima gradualmente combinações promissoras de hiperparâmetros sem a necessidade de reembaralhamentos aleatórios repetidos dos dados.
Testando em diferentes tipos de modelos
Para avaliar como o GPSS funciona na prática, a equipe o aplicou a três modelos populares de aprendizado de máquina: máquinas de vetor de suporte, uma rede neural rasa clássica chamada retropropagação e uma rede neural convolucional mais profunda. Todos os três foram treinados para prever o desempenho da CPU de nós de fog a partir de dados de uso coletados em trabalhos anteriores. O GPSS foi comparado com vários métodos de otimização estabelecidos, incluindo desenhos uniformes sequenciais, algoritmos genéticos e uma técnica baseada em enxame. Os pesquisadores mediram tanto a precisão da previsão, usando erro quadrático médio, quanto o tempo necessário para o ajuste. No conjunto dos testes, o GPSS igualou ou superou métodos concorrentes em precisão enquanto reduziu o custo computacional, e foi o único método prático para o caso da rede convolucional de dimensão muito alta.
Tornando os resultados mais estáveis e reprodutíveis
Além da precisão bruta, os autores enfatizam a estabilidade. Como o GPSS substitui a amostragem aleatória por conjuntos determinísticos de pontos e usa uma alternativa estruturada à validação cruzada tradicional, seus resultados variam muito menos de uma execução para outra. Em simulações, as previsões feitas por modelos ajustados com GPSS se agruparam de forma estreita em torno do desempenho real da CPU, e experimentos repetidos produziram resultados quase idênticos. O método também mostrou forte capacidade de busca global em problemas matemáticos de teste padrão, indicando que é pouco provável que fique preso em mínimos locais ao explorar espaços complexos de hiperparâmetros.
O que isso significa para a tecnologia conectada do dia a dia
Em termos simples, este trabalho trata de girar os botões de ajuste em algoritmos de aprendizado de forma mais ordenada e eficiente. Ao substituir o acaso de tentativa e erro por pontos de busca distribuídos uniformemente e um estreitamento contínuo do foco, o GPSS encontra configurações confiáveis que permitem aos modelos prever quão ocupados os nós de fog estarão. Previsões melhores significam escalonamento de tarefas mais inteligente, tempos de espera menores para aplicativos e potencialmente menor consumo de energia em redes de dispositivos de consumo. Embora os autores observem limitações — como dificuldades com certos tipos de parâmetros discretos e a necessidade de testes mais amplos — a abordagem oferece um plano promissor para manter a crescente teia de gadgets inteligentes de amanhã funcionando sem problemas.
Citação: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Palavras-chave: computação em fog, otimização de hiperparâmetros, aprendizado de máquina na borda, Internet das Coisas, previsão de desempenho