Clear Sky Science · fr
Une nouvelle optimisation par rétrécissement progressif d'ensembles de bons points pour la prédiction des performances de nœuds fog dans les modèles d'apprentissage automatique
Les appareils plus intelligents exigent un réglage plus fin
Des traqueurs d'activité aux thermostats connectés en passant par les voitures reliées, les appareils d'aujourd'hui envoient en permanence des données dans l'éther numérique. Une grande partie de ces informations est traitée sur des ordinateurs « fog » proches, à la périphérie du réseau, plutôt que dans des centres de données lointains. Ce traitement local maintient la réactivité des applications et réduit la congestion, mais seulement si ces nœuds fog sont utilisés efficacement. L'article résumé ici propose une nouvelle méthode pour régler les modèles d'apprentissage automatique afin qu'ils prédisent plus précisément les performances des nœuds fog, permettant aux appareils connectés du quotidien de fonctionner plus rapidement, plus harmonieusement et avec moins d'énergie gaspillée.
Le défi des ordinateurs en périphérie très sollicités
À mesure que des milliards d'appareils de l'Internet des objets se connectent, ils inondent le réseau de requêtes : relevés de capteurs à analyser, flux vidéo à filtrer et signaux de commande à décider en temps réel. L'informatique fog répond à cela en rapprochant le calcul de la source, sur des machines disséminées dans les maisons, les voitures, les usines et les rues. Pour maintenir des délais faibles, un ordonnanceur doit décider quel nœud fog doit traiter chaque tâche, et cette décision dépend fortement de la charge processeur de chaque nœud et de la rapidité avec laquelle il peut terminer une tâche. Les auteurs se concentrent sur la prédiction de ces performances à partir d'indicateurs simples tels que l'utilisation CPU, afin que les tâches soient affectées intelligemment plutôt que par tâtonnements.
Pourquoi le réglage des modèles est si coûteux
Les modèles d'apprentissage automatique disposent de cadrans, appelés hyperparamètres, qui doivent être définis avant l'entraînement. On pense par exemple à la force de la pénalisation des erreurs, à la vitesse d'apprentissage ou au nombre d'unités internes. Trouver de bons réglages importe souvent plus que le choix même du modèle. Aujourd'hui, ce réglage repose généralement sur des méthodes qui remélangent les données à plusieurs reprises (validation croisée) et explorent l'espace des hyperparamètres par une combinaison d'essais aléatoires, de règles de recherche astucieuses ou de stratégies évolutives. Bien que puissantes, ces approches ont deux inconvénients majeurs : elles introduisent de l'aléa qui rend les résultats difficiles à reproduire, et elles peuvent devenir extrêmement chronophages, en particulier pour les réseaux neuronaux profonds comportant des centaines de paramètres.
Une façon plus ordonnée de chercher
Les auteurs proposent une stratégie différente appelée Good Point Set Stepwise Shrinkage, ou GPSS. Plutôt que d'échantillonner aléatoirement l'espace des hyperparamètres, ils utilisent des ensembles de points soigneusement construits qui se répartissent de façon homogène, un concept initialement développé en théorie des nombres. À chaque étape, GPSS évalue un lot de ces candidats bien espacés et mesure la qualité prédictive du modèle correspondant sur la performance CPU. Il resserre ensuite la fenêtre de recherche autour de la région la mieux performante, réduit les bornes d'une proportion fixe et génère un nouveau lot, plus dense, de points bien répartis à l'intérieur de cette zone plus petite. En répétant ce processus « grossier‑vers‑fin » on converge progressivement vers des combinaisons d'hyperparamètres prometteuses sans avoir besoin de remélanger aléatoirement les données à chaque itération.
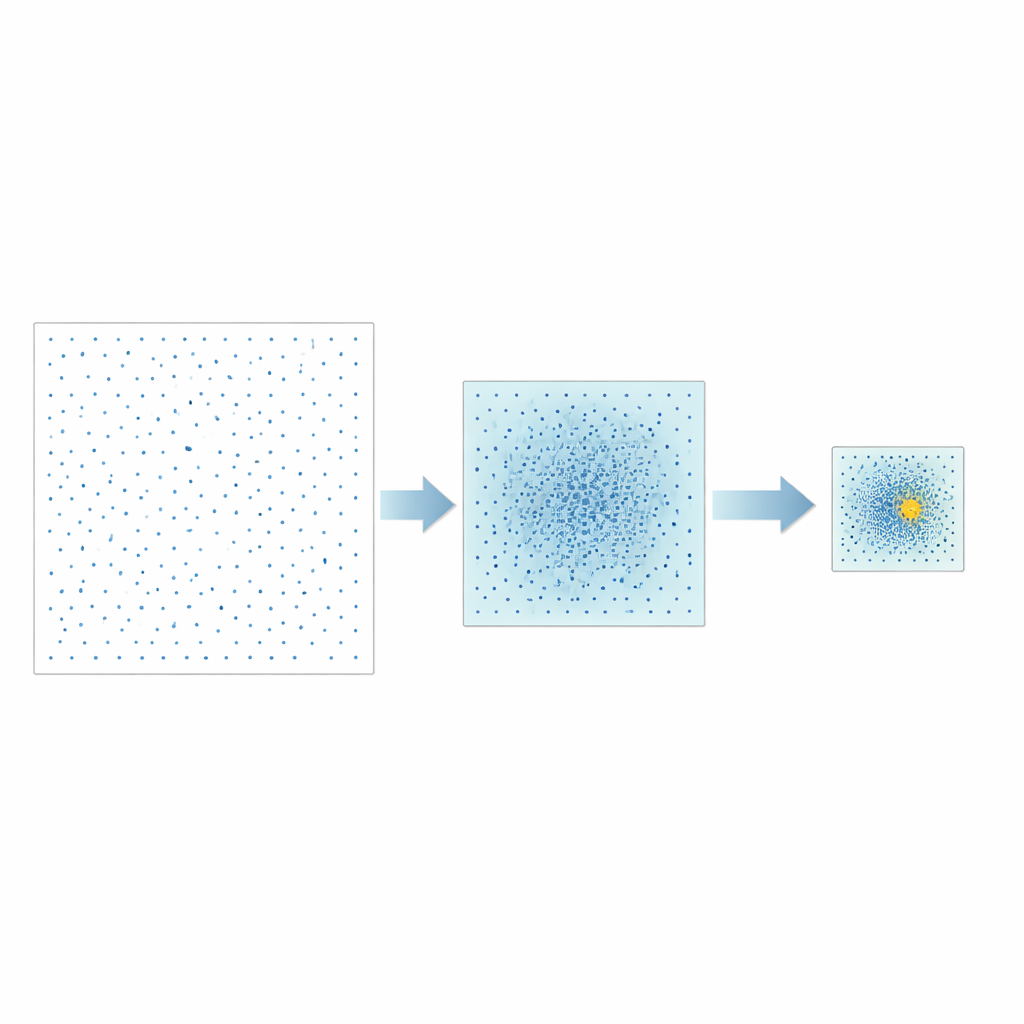
Tests sur différents types de modèles
Pour évaluer GPSS en pratique, l'équipe l'a appliqué à trois modèles d'apprentissage automatique populaires : les machines à vecteurs de support, un réseau neuronal peu profond classique utilisant la rétropropagation, et un réseau neuronal convolutionnel plus profond. Les trois ont été entraînés à prédire la performance CPU des nœuds fog à partir de données d'utilisation recueillies dans des travaux antérieurs. GPSS a été comparé à plusieurs méthodes d'optimisation établies, dont des plans uniformes séquentiels, des algorithmes génétiques et une technique inspirée des essaims. Les chercheurs ont mesuré à la fois la précision de prédiction, via l'erreur quadratique moyenne, et le temps nécessaire au réglage. Dans l'ensemble, GPSS a égalé ou surpassé les méthodes concurrentes en précision tout en réduisant le coût computationnel, et il a été la seule méthode praticable pour le cas très hautement dimensionnel du réseau convolutionnel.
Rendre les résultats plus stables et reproductibles
Au‑delà de la simple précision, les auteurs mettent l'accent sur la stabilité. Parce que GPSS remplace l'échantillonnage aléatoire par des ensembles de points déterministes et utilise une alternative structurée à la validation croisée traditionnelle, ses résultats varient beaucoup moins d'une exécution à l'autre. Dans les simulations, les prédictions faites par des modèles réglés avec GPSS se sont regroupées étroitement autour de la véritable performance CPU, et les expériences répétées ont donné des résultats quasi identiques. La méthode a également montré une forte capacité de recherche globale sur des problèmes mathématiques tests standard, ce qui laisse penser qu'elle a peu de chances de rester bloquée dans des optimums locaux lorsqu'elle explore des espaces d'hyperparamètres complexes.
Ce que cela signifie pour la technologie connectée de tous les jours
En termes simples, ce travail consiste à tourner les réglages des algorithmes d'apprentissage de manière plus ordonnée et efficace. En remplaçant le hasard d'essais‑erreurs par des points de recherche uniformément répartis et un resserrement progressif de la zone d'exploration, GPSS trouve des configurations fiables qui permettent aux modèles de prévoir à quel point les nœuds fog seront chargés. De meilleures prédictions signifient des ordonnancements plus intelligents des tâches, des temps d'attente réduits pour les applications et, potentiellement, une moindre consommation d'énergie dans les réseaux d'appareils grand public. Si les auteurs notent des limites — comme des difficultés avec certains types de réglages discrets et le besoin de tests plus larges — leur approche offre un plan prometteur pour maintenir le maillage croissant d'objets intelligents de demain en bon fonctionnement.
Citation: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Mots-clés: informatique en brouillard, optimisation d'hyperparamètres, apprentissage automatique en périphérie, Internet des objets, prédiction de performance