Clear Sky Science · he
נקודת טובת חדשה ואופטימיזציית הצמצום ההדרגית בהדרגה עבור חיזוי ביצועי צמתים בערפל במודלי למידת מכונה
מכשירים חכמים צריכים כיוונון חכם יותר
משעונים כושר ועד תרמוסטטים חכמים ורכבים מחוברים — הגאדג'טים של היום שולחים נתונים אל הערפול הדיגיטלי באופן רציף. חלק גדול מהמידע מעובד על מחשבי "ערפל" מקומיים בקצה הרשת, במקום במרכזי נתונים מרוחקים. עיבוד מקומי זה שומר על תגובה מהירה של אפליקציות ומפחית עומסים, אך רק אם צמתים אלה מנוצלים ביעילות. המאמר המסוכם כאן מציג שיטה חדשה לכוונון מודלי למידת מכונה כך שיוכלו לנבא בדיוק רב יותר את ביצועי צמתים בערפל, ועוזרים למכשירים מחוברים יומיומיים לפעול מהר יותר, חלק יותר ובצריכת אנרגיה פחותה יותר.
האתגר של מחשבי קצה עמוסים
כשמיליארדי התקני אינטרנט של הדברים מתחברים, הם מוצפים את הרשת בבקשות: קריאות חיישנים לניתוח, זרמי וידאו לסינון ואותות בקרה להחלטה בזמן אמת. חישוב ערפל מטפל בכך על‑ידי העברת המחשוב קרוב יותר למקור, על מכונות פרוסות בבתים, ברכבים, במפעלים וברחובות העיר. כדי לשמור על השהיות נמוכות, מתזמן חייב להחליט איזה צומת ערפל יטפל בכל משימה, וההחלטה הזו תלויה במידה רבה כמה עסוק המעבד של כל צומת וכמה מהר הוא מסוגל להשלים משימה. המחברים מתמקדים בחיזוי ביצועי צומת זה מתוך מצביעים פשוטים כמו שימוש ב‑CPU, כך שניתן להקצות משימות בחוכמה במקום בניחוש.
למה כוונון למידת מכונה יקר כל כך
למודלי למידת מכונה יש חוגות כיוונון, שנקראות היפר‑פרמטרים, שיש לקבוע לפני האימון. דוגמאות כוללות עד כמה המודל מעניש שגיאות, כמה מהר הוא לומד מנתונים חדשים, או כמה יחידות פנימיות הוא משתמש. מציאת הגדרות חוגה טובות לעתים קרובות חשובה יותר מבחירת המודל עצמו. כיום הכיוונון מסתמך לרוב על שיטות שמשלבות ערבוב חוזר של הנתונים (חציית אימות) וחיפוש בנוף ההיפר‑פרמטרים באמצעות ניחושים אקראיים, כללים חכמים לחיפוש או אסטרטגיות אבולוציוניות. למרות עוצמתן, לשיטות אלה שני חסרונות מרכזיים: הן מוסיפות אקראיות שקשה לשחזר, והן עלולות להיות גוזלות זמן רב מאוד, במיוחד ברשתות עצביות עמוקות עם מאות פרמטרים.
דרך מסודרת יותר לחיפוש
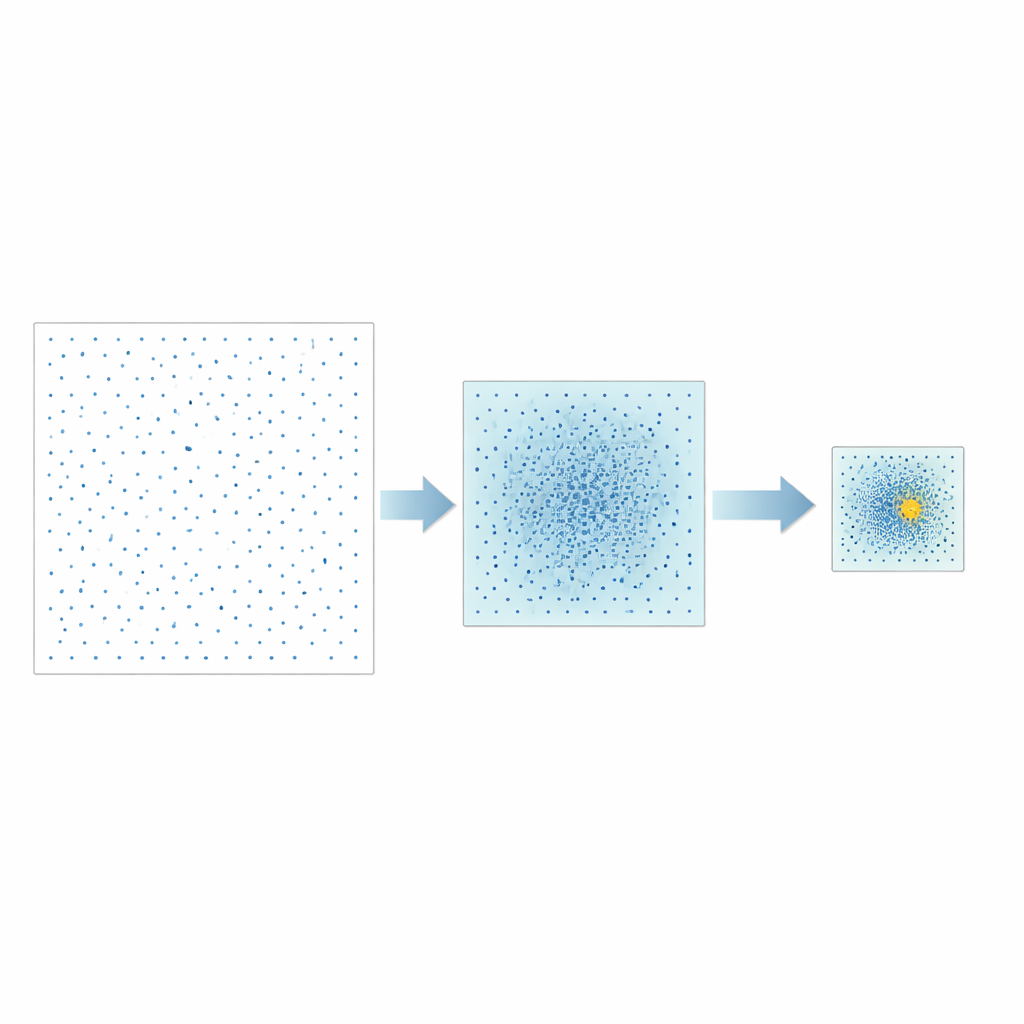
המחברים מציעים אסטרטגיה שונה שנקראת Good Point Set Stepwise Shrinkage, או GPSS. במקום לדגום באופן אקראי את מרחב ההיפר‑פרמטרים, הם משתמשים במערכי נקודות בנויים בקפידה שמתפשטים באופן אחיד — רעיון שפותח במקור בתורת המספרים. בכל שלב, GPSS מעריך אצווה של מועמדים מפוזרים אלה ומודד עד כמה המודל המתאים חוזה היטב את ביצועי ה‑CPU. לאחר מכן הוא מצמצם את חלון החיפוש סביב האזור עם הביצועים הטובים ביותר, מקטין את הגבולות ביחס קבוע ויוצר אצווה חדשה, צפופה יותר של נקודות מפוזרות בתוך האזור הקטן הזה. חזרה על תהליך "גס‑למדויק" זה מתקרבת בהדרגה לשילובים מבטיחים של היפר‑פרמטרים בלי הצורך לערבוב אקראי חוזר של הנתונים.
בדיקה על סוגים שונים של מודלים
כדי לבחון כמה GPSS יעיל בפועל, הצוות יישם אותו על שלושה מודלים פופולריים של למידת מכונה: מכונות וקטור תמיכה, רשת עצבית רדודה קלאסית שנקראת backpropagation, ורשת עצבית קונבולוציונית עמוקה יותר. שלושתם אומנו לחזות ביצועי CPU של צמתים בערפל מתוך נתוני שימוש שנאספו בעבודה קודמת. GPSS הושווה לכמה שיטות אופטימיזציה מבוססות, כולל עיצובים סידוריים אחידים, אלגוריתמים גנטיים וטכניקה מבוססת מושבות. החוקרים מדדו הן את דיוק החיזוי, באמצעות שגיאת ריבוע ממוצעת, והן את הזמן הנדרש לכיוונון. בכל המקרים, GPSS השווה או התעלה על שיטות מתחרות בדיוק תוך קיצוץ בעלות החישובית, והיא הייתה השיטה היחידה מעשית במקרה של רשת קונבולוציונית בעלת מימדיות גבוהה מאוד.
להפוך תוצאות ליציבות וניתנות לשחזור
מעבר לדיוק גולמי, המחברים מדגישים את היציבות. מאחר ש‑GPSS מחליף דגימה אקראית במערכי נקודות דטרמיניסטיים ומשתמש בחלופה מובנית לחציית אימות המסורתית, התוצאות שלו נוטות להשתנות פחות מריצה לריצה. בסימולציות, התחזיות של מודלים שכוונו עם GPSS התרסקו סביב ביצועי ה‑CPU האמיתיים, וניסויים חוזרים הניבו תוצאות כמעט זהות. השיטה גם הראתה יכולת חיפוש גלובלית חזקה על בעיות מבחן מתמטיות סטנדרטיות, מה שמרמז שסביר שלא תיתקע במלכודות מקומיות כשחוקרת מרחבי היפר‑פרמטרים מורכבים.
מה זה אומר לטכנולוגיה המחוברת היומיומית
במילים פשוטות, עבודה זו עוסקת בכיוון הכפתורים של אלגוריתמי הלמידה באופן מסודר ויעיל יותר. על‑ידי החלפה של ניסוי וטעייה אקראי בנקודות חיפוש מפוזרות שווה ובצמצום ממוקד ועקבי, GPSS מוצא הגדרות אמינות שמאפשרות למודלים לחזות כמה עסוקות צמתים בערפל יהיו. חיזויים טובים יותר משמעותם תזמון משימות חכם יותר, זמני המתנה קצרים יותר לאפליקציות ואפשרות לצמצום צריכת האנרגיה ברשתות של מכשירי צריכה. בעוד שהמחברים מציינים מגבלות — כגון קשיים עם סוגים מסוימים של הגדרות בדידות והצורך בבדיקות רחבות יותר — הגישה שלהם מציעה דפוס מבטיח לשמירה על רשת הולכת וגדלה של גאדג'טים חכמים שפועלת חלק.
ציטוט: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
מילות מפתח: חישוב ערפל, אופטימיזציית היפר‑פרמטרים, למידת מכונה בקצה, אינטרנט של הדברים, חיזוי ביצועים