Clear Sky Science · nl
Een nieuwe Good Point Set stepwise shrinkage‑optimalisatie in machine learning‑modellen voor prestatievoorspelling van fog‑nodes
Slimmere apparaten hebben slimmere afstemming nodig
Van fitnesstrackers tot slimme thermostaten en verbonden auto’s: hedendaagse apparaten zenden continu gegevens de digitale ether in. Een groot deel van die informatie wordt niet in verre datacenters, maar op nabijgelegen "fog"‑computers aan de rand van het netwerk verwerkt. Die lokale verwerking houdt apps responsief en vermindert congestie, maar alleen als die fog‑nodes efficiënt worden benut. Het hier samengevatte artikel introduceert een nieuwe manier om machine‑learningmodellen af te stemmen zodat ze nauwkeuriger kunnen voorspellen hoe goed fog‑nodes presteren, wat alledaagse verbonden apparaten helpt sneller, soepeler en met minder verspilde energie te draaien.
De uitdaging van drukke edge‑computers
Naarmate miljarden IoT‑apparaten online komen, overspoelen ze het netwerk met verzoeken: sensormetingen om te analyseren, videostreams om te filteren en besturingssignalen die in realtime beslissingen vereisen. Fog computing pakt dit aan door berekeningen dichter bij de bron uit te voeren, op machines verspreid door huizen, auto’s, fabrieken en straten. Om vertragingen laag te houden moet een scheduler beslissen welke fog‑node elke taak afhandelt, en die beslissing hangt sterk af van hoe druk de processor van een node is en hoe snel een taak voltooid kan worden. De auteurs richten zich op het voorspellen van deze node‑prestatie op basis van eenvoudige indicatoren zoals CPU‑gebruik, zodat taken intelligent kunnen worden toegewezen in plaats van op gut feeling.
Waarom het afstemmen van machine learning zo kostbaar is
Machine‑learningmodellen hebben draaiknoppen, hyperparameters genoemd, die voor het trainen moeten worden ingesteld. Voorbeelden zijn hoe sterk een model fouten bestraft, hoe snel het leert van nieuwe data, of hoeveel interne eenheden het gebruikt. Goede instellingen vinden is vaak belangrijker dan de keuze van het model zelf. Tegenwoordig vertrouwt deze afstemming meestal op methoden die de data herhaaldelijk herschikken (cross‑validatie) en het hyperparameterruim verkennen met een mix van willekeurige gokken, slimme zoekregels of evolutionaire strategieën. Hoewel krachtig, hebben deze benaderingen twee belangrijke nadelen: ze brengen randomisatie binnen die resultaten moeilijk reproduceerbaar maakt, en ze kunnen extreem tijdrovend worden, vooral voor diepe neurale netwerken met honderden instellingen.
Een meer ordelijke manier van zoeken
De auteurs stellen een andere strategie voor, Good Point Set Stepwise Shrinkage (GPSS). In plaats van het hyperparameterruim willekeurig te bemonsteren, gebruiken ze zorgvuldig geconstrueerde puntensets die gelijkmatig verspreid liggen, een idee dat oorspronkelijk in de getaltheorie is ontwikkeld. In elke fase evalueert GPSS een batch van deze goed gespreide kandidaten en meet hoe goed het bijbehorende model de CPU‑prestatie voorspelt. Vervolgens vernauwt het de zoekwindow rond het best presterende gebied, verkleint de grenzen met een vaste factor en genereert een nieuwe, dichtere batch goed verdeelde punten binnen dit kleinere gebied. Door dit "grof‑naar‑fijn" proces te herhalen, werkt de methode geleidelijk naar veelbelovende hyperparametercombinaties toe zonder dat herhaaldelijk willekeurig herschikken van de data nodig is.
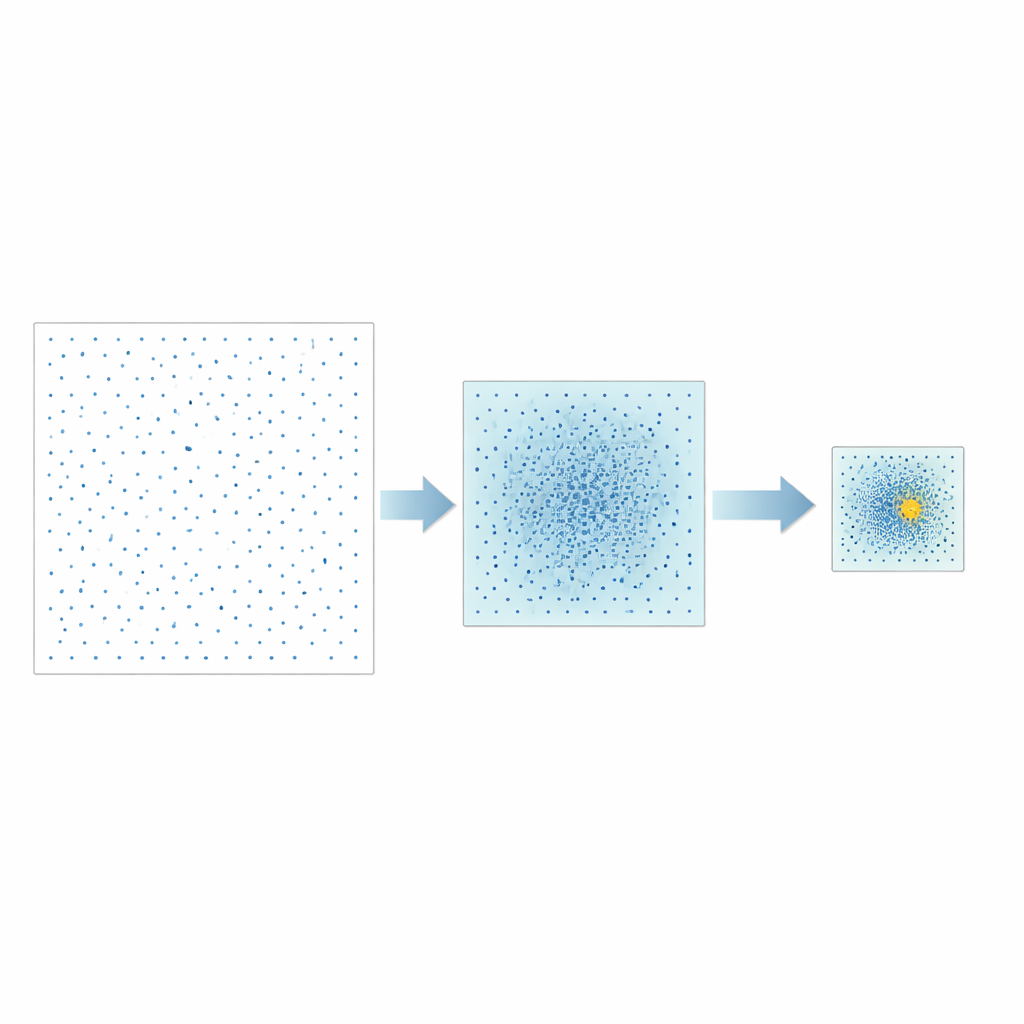
Testen op verschillende modeltypen
Om te zien hoe goed GPSS in de praktijk werkt, paste het team het toe op drie veelgebruikte machine‑learningmodellen: support vector machines, een klassiek ondiep neuronaal netwerk met backpropagation, en een dieper convolutioneel neuraal netwerk. Alle drie werden getraind om de CPU‑prestatie van fog‑nodes te voorspellen aan de hand van gebruiksdata uit eerder werk. GPSS werd vergeleken met verschillende gevestigde optimalisatiemethoden, waaronder sequentiële uniforme ontwerpen, genetische algoritmen en een zwermgebaseerde techniek. De onderzoekers maten zowel voorspellingsnauwkeurigheid (met mean squared error) als de tijd die de afstemming kostte. Over de hele linie evenaarde of overtrof GPSS concurrerende methoden in nauwkeurigheid terwijl het rekenkosten verminderde, en het was de enige praktische methode voor het zeer hoge‑dimensionale geval van het convolutionele netwerk.
Resultaten stabieler en reproduceerbaarder maken
Bovenop ruwe nauwkeurigheid benadrukken de auteurs stabiliteit. Omdat GPSS willekeurige bemonstering vervangt door deterministische puntensets en een gestructureerd alternatief voor traditionele cross‑validatie gebruikt, variëren de resultaten veel minder van run tot run. In simulaties clusterden voorspellingen van met GPSS afgestemde modellen nauw rond de werkelijke CPU‑prestatie, en herhaalde experimenten leverden vrijwel identieke uitkomsten op. De methode toonde ook sterke globale zoekcapaciteiten op standaard wiskundige testproblemen, wat aangeeft dat het onwaarschijnlijk vastloopt in lokale doodlopende valleien bij het verkennen van complexe hyperparameterruimten.
Wat dit betekent voor alledaagse verbonden technologie
In eenvoudige bewoordingen draait dit werk om het ordelijker en efficiënter afstellen van leeralgoritmen. Door trial‑and‑error‑randomness te vervangen door gelijkmatig verdeelde zoekpunten en een geleidelijke versmalling van de focus vindt GPSS betrouwbare instellingen waarmee modellen kunnen voorspellen hoe druk fog‑nodes zullen zijn. Betere voorspellingen betekenen intelligentere taakplanning, kortere wachttijden voor apps en mogelijk lager energieverbruik in netwerken van consumententoestellen. Hoewel de auteurs beperkingen noemen—zoals moeilijkheden met bepaalde soorten discrete instellingen en de noodzaak van bredere tests—biedt hun aanpak een veelbelovend sjabloon om het steeds groter wordende web van slimme gadgets straks soepel te laten draaien.
Bronvermelding: Bo, Z., Hasan, M.K., Sundararajan, E.A. et al. A new good point set stepwise shrinkage optimization in machine learning model for fog node performance prediction. Sci Rep 16, 13956 (2026). https://doi.org/10.1038/s41598-026-41630-z
Trefwoorden: fog computing, hyperparameteroptimalisatie, edge machine learning, Internet of Things, prestatievoorspelling