Clear Sky Science · zh
具有可解释特征选择的深度学习框架,用于准确预测SUMO化位点
这对健康与医学为何重要
蛋白质几乎驱动细胞内的所有过程,蛋白质合成后添加的微小化学标签可以彻底改变其功能。其中一种称为SUMO的标签与癌症、阿尔茨海默病及其他严重疾病有关。在数千种蛋白质上通过实验准确定位SUMO附着位点既耗时又昂贵。本文介绍了Hybrid-Sumo——一种强大的计算模型,能够以显著的准确度识别可能的SUMO附着位点,有望加速基础研究和未来药物发现。
细胞如何切换蛋白质行为
我们的细胞通过被称为翻译后修饰的“生产后”编辑来微调蛋白质行为。SUMO化就是这种修饰之一,涉及将一个小的修饰蛋白连接到目标蛋白的赖氨酸残基上。这个微小变化可以改变蛋白质的折叠方式、在细胞内的定位、生存时间以及与哪些伙伴结合。由于SUMO化影响基因调控、DNA修复和蛋白质回收,它在维持细胞稳态方面扮演重要角色。当SUMO化失衡时,可能促成神经退行性疾病和癌症,因此绘制准确的SUMO位点图谱是生物学家的重要任务。
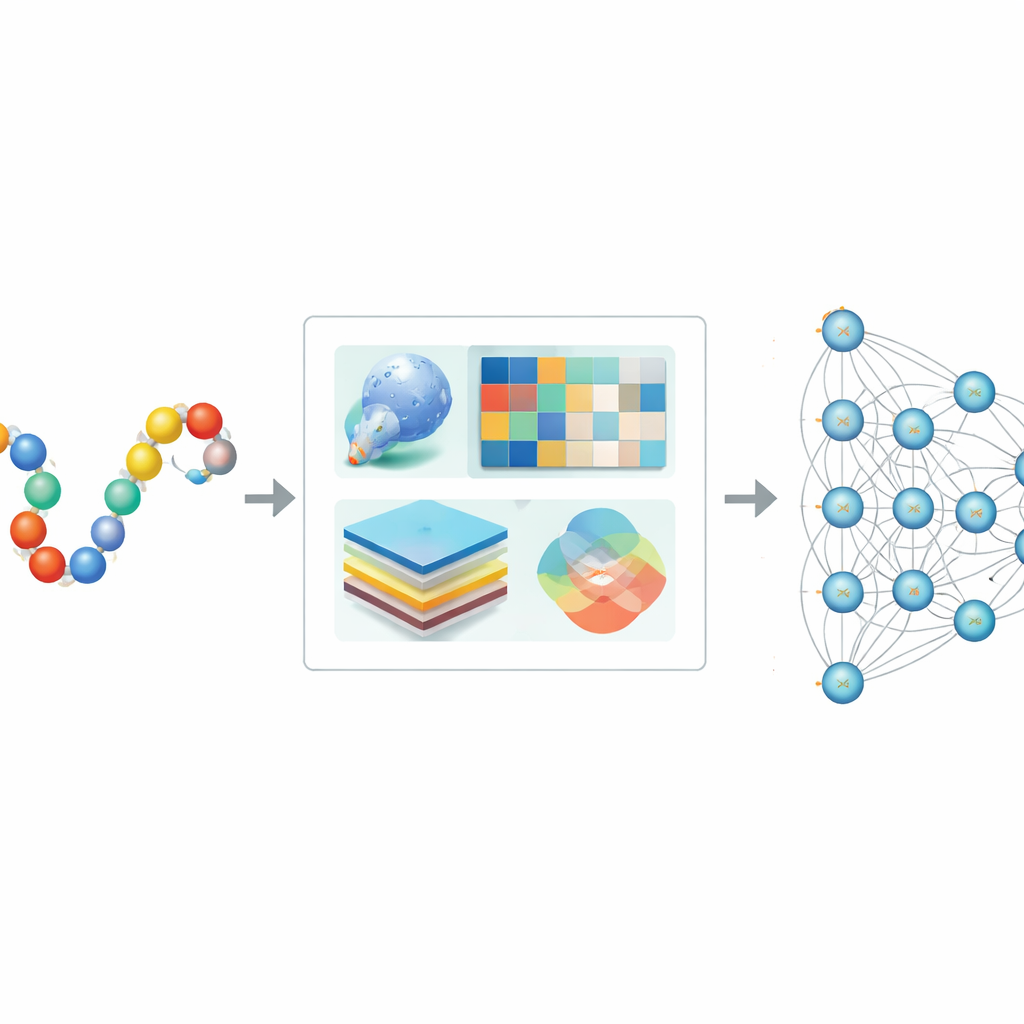
为什么需要计算方法来寻找SUMO标签
传统的实验室方法可用于验证SUMO化,但难以扩展到人类及其他生物体中大量的蛋白质。早期的计算工具通过识别短序列模式或使用经典机器学习方法(如决策树或支持向量机)来尝试检测SUMO位点。虽然有一定帮助,但这些方法常常忽略蛋白质的完整背景,包括其三维结构和进化史,并且在数据不平衡(已知SUMO位点远少于非SUMO位点)时容易表现欠佳。因此,预测可能存在偏差,且难以推广到新的蛋白质。
对每个蛋白位点的混合视角
作者设计Hybrid-Sumo以三种互补角度同时查看每个潜在的SUMO位点。首先,他们使用一种称为半球暴露度的结构度量来估计残基在蛋白表面的埋藏或暴露程度,这影响SUMO是否能物理接近该位点。其次,他们计算反映位置在相关蛋白中如何变化的进化轮廓,并用小波方法压缩这些轮廓以突出重要模式并减少噪声。第三,他们借用最初为语言构建的Transformer模型,将氨基酸序列视作句子,使网络能够学习描述每个位置与其邻近残基关系的丰富上下文“嵌入”。这三组数值被融合为对每个位点的单一、详尽描述。
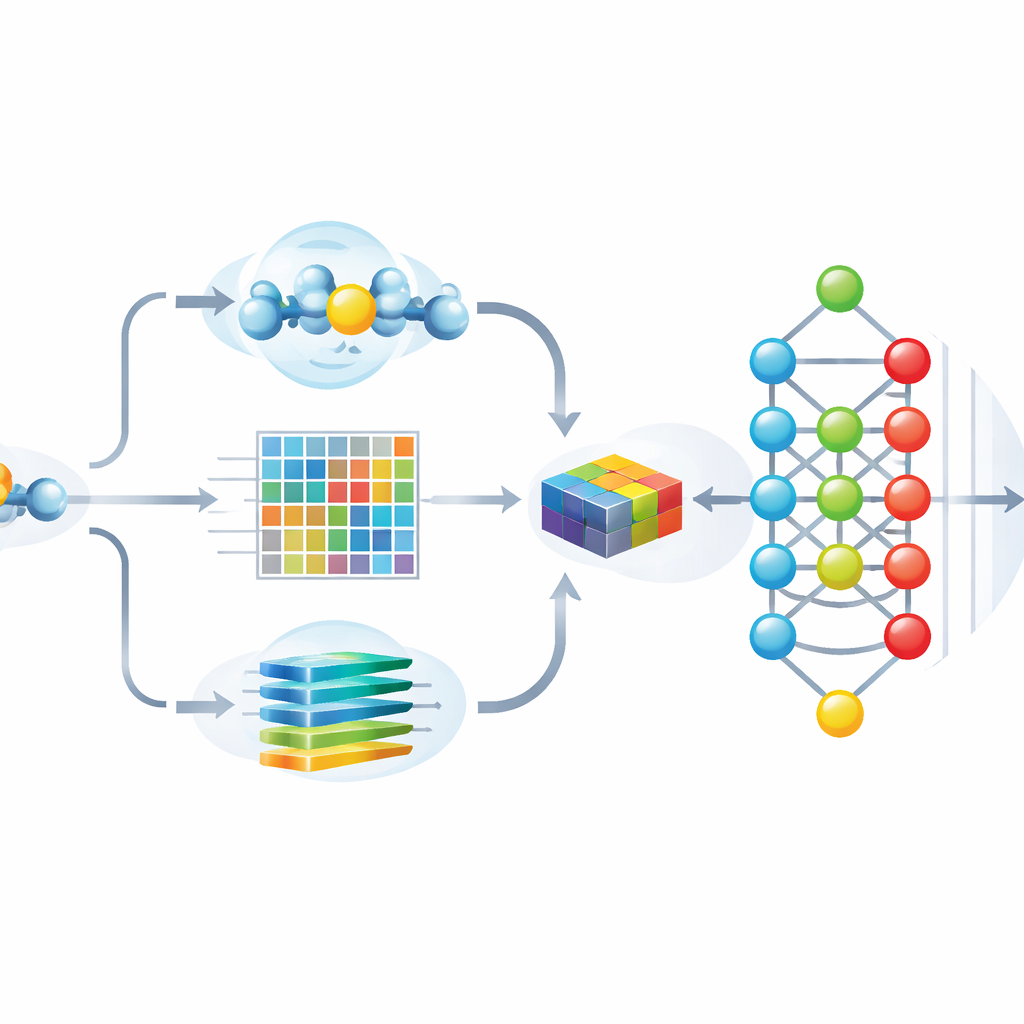
使模型既准确又可解释
将超过一千个特征输入深度神经网络可以提升准确性,但也增加过拟合风险,并使人难以辨识模型实际依赖的线索。为了解决这一问题,团队使用一种源自博弈论的技术SHAP来评估每个特征对正确预测的贡献程度。然后他们仅保留最有信息量的243个特征,大幅削减冗余同时保留性能。可视化分析显示,经过此选择后,SUMO与非SUMO位点形成了良好分离的簇,且最重要的特征与直观属性一致,例如表面暴露度、局部电荷以及围绕被修饰赖氨酸的特征性序列模式。
对Hybrid-Sumo的检验
为了避免误导性结果,研究者从经整理的蛋白修饰数据库构建了平衡与不平衡的数据集,移除近重复序列,并使用重复交叉验证以及完全独立的测试集评估Hybrid-Sumo。最终模型在训练数据上的准确率约为99.7%,在未见过的蛋白上约为96%,比若干为相同任务专门构建的强大深度学习和集成方法略有但稳定地优越。统计检验确认基于SHAP的特征选择带来的增益是真实的,而与其他常见算法的比较显示,这一优势来自混合特征和细致的优化,而不仅仅是选择了深度网络。
未来的意义
对非专业读者来说,关键结论是Hybrid-Sumo提供了一种更可靠的方法去预测SUMO标签在蛋白质上的着落,结合了3D结构、进化信号与现代序列“语言”模型。通过减少实验室中的试错次数,它能帮助科学家优先安排实验、探索SUMO化如何促成疾病,并最终指导针对或利用这一微妙蛋白开关的治疗策略。同样的设计原则——结合分子多视角并使用可解释的特征选择——也可被改编用于预测其他多种与健康和疾病相关的蛋白质修饰。
引用: Alyahya, A.N., Khan, S., Dilshad, N. et al. Deep learning framework with interpretable feature selection for accurate SUMOylation site prediction. Sci Rep 16, 10419 (2026). https://doi.org/10.1038/s41598-026-41489-0
关键词: SUMO化, 蛋白质修饰, 深度学习, 特征选择, 生物信息学