Clear Sky Science · ru
Глубокая обучающая система с интерпретируемым отбором признаков для точного предсказания сайтов SUMOилирования
Почему это важно для здоровья и медицины
Белки управляют почти всеми процессами в наших клетках, и крошечные химические метки, добавляемые после синтеза белка, могут полностью изменить его функцию. Одна из таких меток, называемая SUMO, связана с раком, болезнью Альцгеймера и другими серьёзными состояниями. Экспериментальное определение точных сайтов присоединения SUMO на тысячах белков медленно и дорого. В этой статье представлен Hybrid-Sumo — мощная компьютерная модель, способная с высокой точностью указать вероятные сайты присоединения SUMO, что может ускорить фундаментальные исследования и будущую разработку лекарств.
Как клетки переключают поведение белков
Клетки тонко настраивают поведение белков с помощью «послесинтетических» правок, известных как посттрансляционные модификации. SUMOилирование — одна из таких правок, при которой маленький модификаторный белок присоединяется к лизину в целевом белке. Это небольшое изменение может повлиять на свёртывание белка, его локализацию в клетке, стабильность и с какими партнёрами он взаимодействует. Поскольку SUMOилирование влияет на регуляцию генов, репарацию ДНК и утилизацию белков, оно глубоко вовлечено в поддержание клеточного гомеостаза. При нарушениях SUMOилирования это может способствовать нейродегенеративным заболеваниям и раку, поэтому точные карты сайтов SUMO являются важной задачей для биологов.
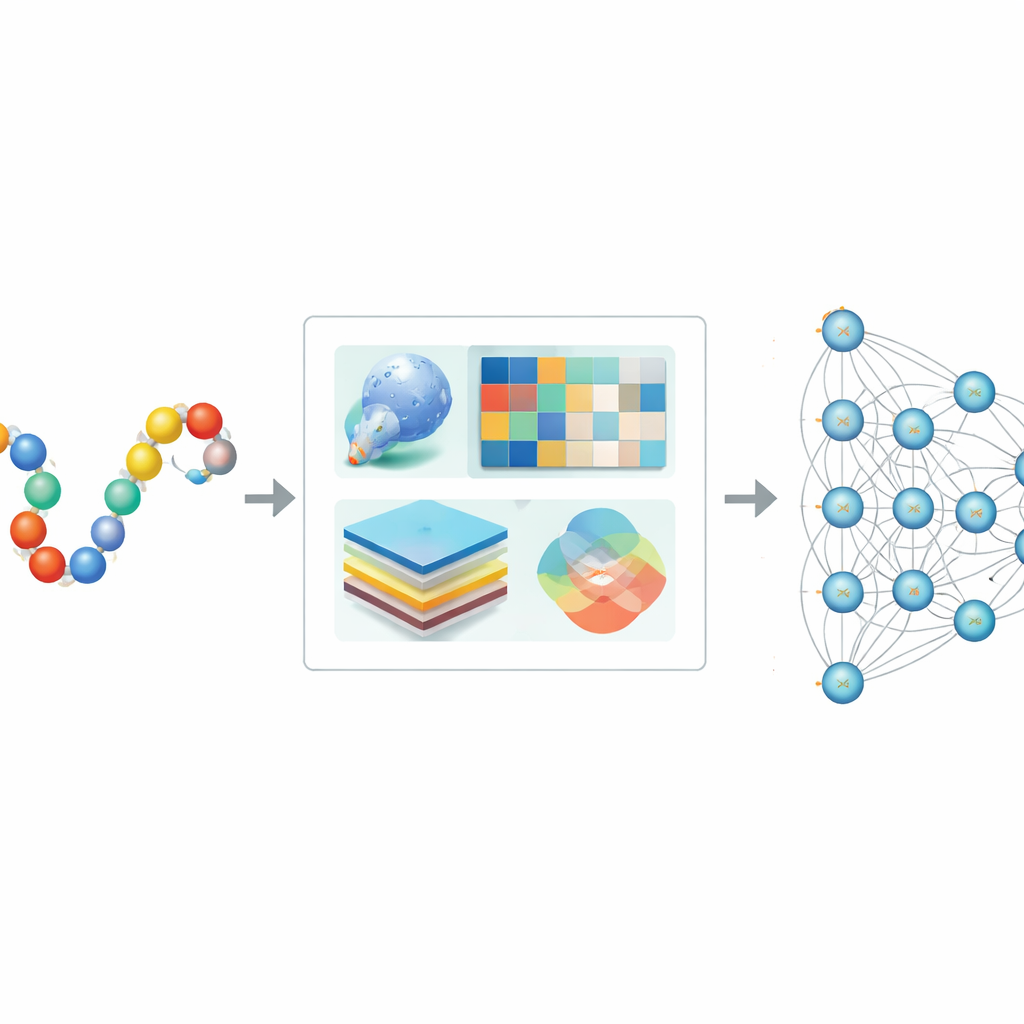
Почему для поиска меток SUMO нужны компьютеры
Традиционные лабораторные методы могут подтвердить SUMOилирование, но они плохо масштабируются на огромное количество белков у человека и других организмов. Ранние компьютерные инструменты пытались обнаруживать сайты SUMO по коротким последовательностным мотивам или с помощью классических методов машинного обучения, таких как деревья решений или опорные векторы. Хотя это было полезно, такие подходы часто игнорировали полный контекст белка, включая его трёхмерную структуру и эволюционную историю, и испытывали трудности при несбалансированных данных, когда известных сайтов SUMO намного меньше, чем несумо сайтов. В результате предсказания могли быть смещены или не переноситься на новые белки.
Гибридный взгляд на каждый сайт белка
Авторы разработали Hybrid-Sumo так, чтобы он одновременно рассматривал каждый потенциальный сайт SUMO с трёх взаимодополняющих точек зрения. Во-первых, они используют структурную меру, называемую полусферной экспозицией (half-sphere exposure), чтобы оценить, насколько остаток погружён или открыт на поверхности белка, что влияет на физическую доступность SUMO. Во-вторых, вычисляются эволюционные профили, отражающие, как позиция изменялась в родственных белках, затем эти профили сжимаются с помощью вейвлет-методов, чтобы выделить важные паттерны и уменьшить шум. В-третьих, они заимствуют трансформерную модель, изначально созданную для языка, рассматривая аминокислотные последовательности как предложения, чтобы сеть могла научиться богатым контекстным «встраиваниям», описывающим, как каждая позиция связана с соседями вдоль цепочки. Эти три набора признаков объединяются в единое подробное описание каждого сайта.
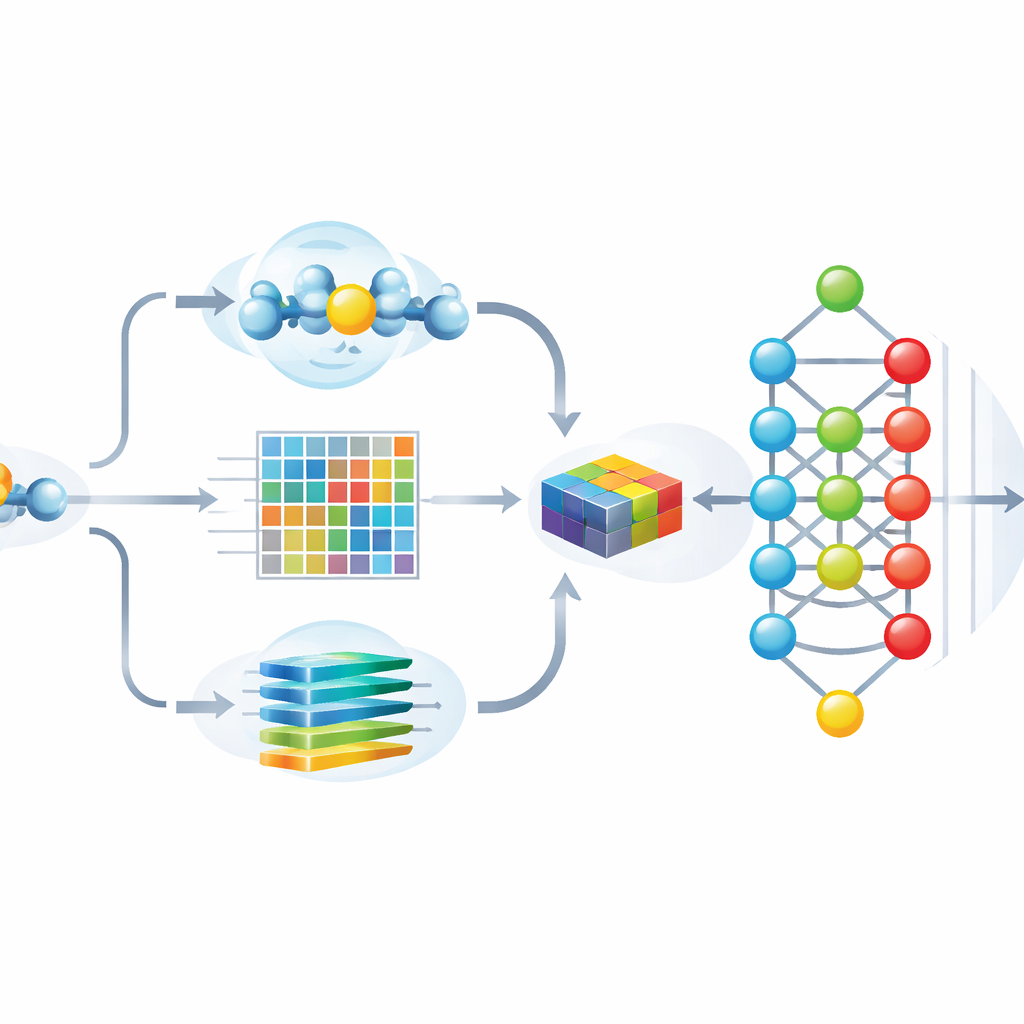
Как сделать модель одновременно точной и объяснимой
Подача в глубокую нейронную сеть более тысячи признаков может повысить точность, но также увеличивает риск переобучения и затрудняет понимание, на какие характеристики модель действительно опирается. Чтобы решить эту проблему, команда использует технику, основанную на теории игр, называемую SHAP, которая оценивает вклад каждого признака в правильные предсказания. Затем оставляют только наиболее информативные 243 признака, значительно сократив избыточность при сохранении производительности. Визуальные анализы показывают, что после этого отбора SUMO- и не-SUMO-сайты образуют чётко разделённые кластеры, а самые важные признаки соответствуют интуитивно понятным свойствам, таким как экспозиция на поверхности, локальный заряд и характерные последовательностные паттерны вокруг модифицируемого лизина.
Тестирование Hybrid-Sumo
Чтобы избежать вводящих в заблуждение результатов, исследователи тщательно сформировали сбалансированные и несбалансированные наборы данных из кураторской базы данных модификаций белков, удалили близкие дубликаты последовательностей и оценивали Hybrid-Sumo с помощью повторной кросс-валидации, а также на полностью независимых тестовых наборах. Финальная модель достигла примерно 99,7% точности на обучающих данных и около 96% точности на невидимых белках, немного, но стабильно превосходя несколько сильных методов глубокого обучения и ансамблевых алгоритмов, созданных специально для этой задачи. Статистические тесты подтвердили, что выигрыши от отбора признаков на основе SHAP реальны, а сравнения с другими распространёнными алгоритмами показали, что преимущество обусловлено гибридными признаками и тщательной оптимизацией, а не только выбором глубокой сети.
Что это означает для будущего
Для неспециалистов главный вывод в том, что Hybrid-Sumo предлагает более надёжный способ предсказать, где помет SUMO прикрепится к белку, используя сочетание 3D-структуры, эволюционных сигналов и современных «языковых» моделей последовательностей. Сокращая метод проб и ошибок в лаборатории, он может помочь учёным приоритизировать эксперименты, исследовать роль SUMOилирования в заболеваниях и в конечном счёте направлять разработку терапий, которые нацелены на эту тонкую переключающую метку белков или используют её. Те же принципы дизайна — комбинирование разных представлений молекулы и последующий интерпретируемый отбор признаков — могут быть адаптированы для предсказания многих других типов модификаций белков, лежащих в основе здоровья и болезней.
Цитирование: Alyahya, A.N., Khan, S., Dilshad, N. et al. Deep learning framework with interpretable feature selection for accurate SUMOylation site prediction. Sci Rep 16, 10419 (2026). https://doi.org/10.1038/s41598-026-41489-0
Ключевые слова: SUMOилирование, модификация белков, глубокое обучение, отбор признаков, биоинформатика