Clear Sky Science · ja
解釈可能な特徴選択を備えた深層学習フレームワークによる高精度なSUMO化部位予測
健康と医療にとっての重要性
タンパク質は細胞内のほぼすべてのプロセスを担い、翻訳後に付加される小さな化学的タグがその機能を一変させることがあります。そのうちの一つであるSUMOは、がんやアルツハイマー病など深刻な疾患と関連しています。数千種類のタンパク質に対して実験的に正確なSUMO付着部位を突き止めるのは時間と費用がかかります。本論文はHybrid-Sumoという強力な計算モデルを紹介しており、高い精度でSUMO付着の可能性が高い部位を特定できるため、基礎研究や将来の創薬の効率化に寄与する可能性があります。
細胞がタンパク質の振る舞いを切り替える仕組み
細胞は翻訳後修飾として知られる「産後の編集」を用いてタンパク質の働きを微調整します。SUMO化は標的タンパク質のリジン残基に小さな修飾タンパク質が結合する一例です。この小さな変化により、タンパク質の折りたたみ、細胞内での局在、寿命、結合相手が変わり得ます。SUMO化は遺伝子制御、DNA修復、タンパク質の分解経路に影響を与えるため、細胞恒常性の維持に深く関わります。SUMO化が異常になると神経変性疾患やがんに寄与することがあり、正確なSUMO部位のマップ作成は生物学者にとって重要な課題です。
なぜSUMOタグの探索にコンピュータが必要か
従来の実験手法はSUMO化を確認できますが、人間や他の生物に存在する膨大な数のタンパク質に対してはスケールしにくいです。これまでの計算ツールは短い配列パターンの検出や決定木、サポートベクターマシンのような古典的機械学習を用いてSUMO部位を予測してきました。これらは有用ではあるものの、タンパク質の立体構造や進化的履歴といった文脈全体を扱えないことが多く、既知のSUMO部位が非SUMO部位に比べて少ないというデータの不均衡に弱い傾向がありました。その結果、予測が偏ったり新しいタンパク質へ一般化できない問題が生じました。
各タンパク質部位のハイブリッドな見方
著者らはHybrid-Sumoを、各潜在的SUMO部位を同時に3つの補完的な視点で評価するよう設計しました。第一に、残基がタンパク質表面でどれだけ埋まっているか露出しているかを推定する半球露出量(half-sphere exposure)という構造的指標を用い、SUMOが物理的に到達可能かを評価します。第二に、関連タンパク質間でその位置がどのように保守されてきたかを表す進化的プロファイルを計算し、これをウェーブレット法で圧縮して重要なパターンを強調しつつノイズを低減します。第三に、アミノ酸配列を文に見立てて学習するトランスフォーマー言語モデルを借用し、各位置が近傍とどう関係するかを表す豊かな文脈埋め込み(embedding)を取得します。これら三種類の特徴を統合して各部位の詳細な記述を生成します。
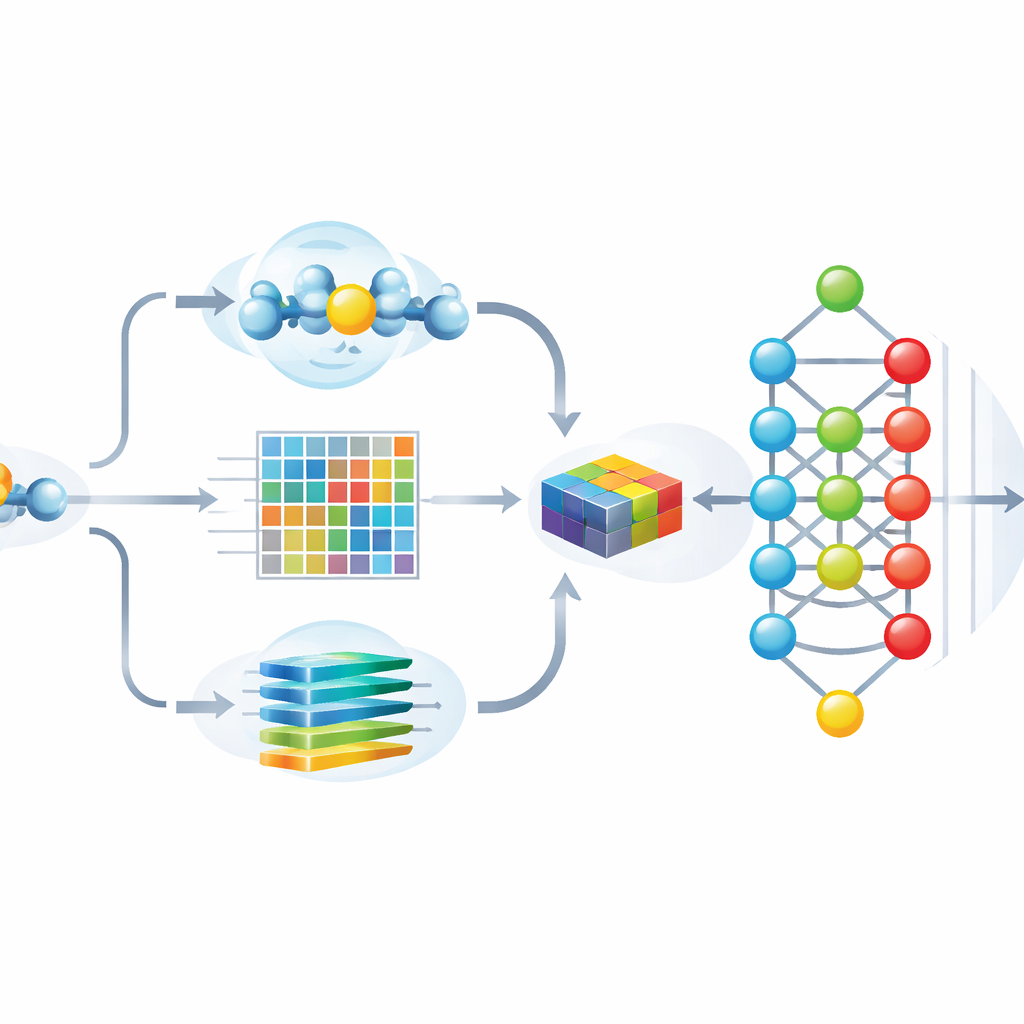
精度と可解釈性を両立させる工夫
千以上の特徴量を深層ニューラルネットワークに投入すれば精度は向上し得ますが、過学習のリスクやモデルが実際に頼っている手がかりの把握を難しくします。そこで研究チームはゲーム理論に着想を得たSHAPという手法を用い、各特徴が正しい予測にどれだけ寄与しているかをスコア化しました。そのうえで、情報量の高い243個の特徴に絞り込み、冗長性を大幅に削減しつつ性能を維持しました。可視化解析により、この選択後にはSUMO部位と非SUMO部位が明確に分離したクラスタを形成し、最も重要な特徴は表面露出、局所的な電荷、修飾リジン周辺の特徴的な配列パターンなど直感的な性質と一致することが示されました。
Hybrid-Sumoの検証
誤解を招く結果を避けるために、研究者らは厳密にキュレーションされたタンパク質修飾データベースからバランスの取れたデータセットと不均衡データセットを構築し、ほぼ重複する配列を除去したうえで、繰り返し交差検証と独立した完全なテストセットでHybrid-Sumoを評価しました。最終モデルは訓練データで約99.7%の精度、未知のタンパク質に対して約96%の精度を達成し、同タスク向けに構築された複数の強力な深層学習およびアンサンブル法に対して一貫してやや上回る性能を示しました。SHAPに基づく特徴選択による改善は偶然によるものではないことが統計的検定で確認され、他の一般的なアルゴリズムとの比較からも、有利さは単に深層ネットワークを選んだからではなく、ハイブリッド特徴と綿密な最適化に起因することが示されました。
今後の意義
非専門家向けの要点は、Hybrid-Sumoが3次元構造・進化的シグナル・最新の配列「言語」モデルを組み合わせることで、SUMOタグがどこに付くかをより信頼して予測できる手段を提供するということです。これにより実験の試行錯誤を減らし、研究者が実験を優先順位付けしやすくなり、SUMO化が疾患にどう寄与するかの解明や、やがてはこの微妙なスイッチを標的や活用する治療法の開発に寄与します。同じ設計原理――分子の多様な見方を組み合わせ、解釈可能な特徴選択を行うこと――は、健康と疾患の根底にある他の多くのタンパク質修飾の予測にも応用できるでしょう。
引用: Alyahya, A.N., Khan, S., Dilshad, N. et al. Deep learning framework with interpretable feature selection for accurate SUMOylation site prediction. Sci Rep 16, 10419 (2026). https://doi.org/10.1038/s41598-026-41489-0
キーワード: SUMO化, タンパク質修飾, 深層学習, 特徴選択, バイオインフォマティクス