Clear Sky Science · nl
Deep learning-framework met interpreteerbare featureselectie voor nauwkeurige voorspelling van SUMOylatieplaatsen
Waarom dit belangrijk is voor gezondheid en geneeskunde
Eiwitten sturen vrijwel elk proces in onze cellen, en kleine chemische labels die na de aanmaak aan een eiwit worden toegevoegd, kunnen volledig veranderen wat het eiwit doet. Een van deze labels, SUMO genoemd, is in verband gebracht met kanker, de ziekte van Alzheimer en andere ernstige aandoeningen. Experimenteel bepalen waar SUMO precies hecht op duizenden eiwitten is traag en kostbaar. Dit artikel introduceert Hybrid-Sumo, een krachtig computermodel dat waarschijnlijk SUMO-hechtplaatsen met opvallende nauwkeurigheid kan aanwijzen, wat fundamenteel onderzoek en toekomstige medicijnontdekking kan versnellen.
Hoe cellen het gedrag van eiwitten schakelen
Onze cellen verfijnen het gedrag van eiwitten met behulp van ‘na-productie’-bewerkingen, bekend als post-translationele modificaties. SUMOylatie is zo’n bewerking waarbij een kleine modifier-eiwit aan een lysine-aminozuur in het doelwit-eiwit wordt bevestigd. Deze kleine wijziging kan beïnvloeden hoe dat eiwit vouwt, waar het in de cel naartoe gaat, hoe lang het blijft bestaan en met welke partners het bindt. Omdat SUMOylatie genregulatie, DNA-reparatie en eiwitrecycling beïnvloedt, speelt het een belangrijke rol in het behouden van cellulaire balans. Wanneer SUMOylatie ontspoort, kan dat bijdragen aan neurodegeneratieve ziekten en kanker, waardoor nauwkeurige kaarten van SUMO-plaatsen een hoge prioriteit hebben voor biologen.
Waarom computers nodig zijn om SUMO-labels te vinden
Traditionele laboratoriummethoden kunnen SUMOylatie bevestigen, maar ze schalen niet goed naar het enorme aantal eiwitten bij mensen en andere organismen. Eerdere computertools probeerden SUMO-plaatsen te herkennen door korte sequentiepatronen te zoeken of door klassieke machine-learningmethoden te gebruiken, zoals decision trees of support vector machines. Hoewel nuttig, negeerden deze benaderingen vaak de volledige context van een eiwit, inclusief zijn driedimensionale vorm en evolutionaire geschiedenis, en hadden ze moeite met onevenwichtige data, met veel minder bekende SUMO-plaatsen dan niet-SUMO-plaatsen. Als gevolg daarvan konden voorspellingen bevooroordeeld zijn of niet generaliseren naar nieuwe eiwitten.
Een hybride blik op elke eiwitplaats
De auteurs ontwierpen Hybrid-Sumo om elk potentieel SUMO-plaatsje tegelijkertijd vanuit drie aanvullende invalshoeken te bekijken. Ten eerste gebruiken ze een structurele maat genaamd half-sphere exposure om te schatten hoe begraven of blootgesteld een residu op het eiwitooppervlak is, wat bepaalt of SUMO het fysiek kan bereiken. Ten tweede berekenen ze evolutionaire profielen die vastleggen hoe een positie is veranderd over verwante eiwitten, en comprimeren deze profielen vervolgens met wavelet-methoden om belangrijke patronen te accentueren en ruis te verminderen. Ten derde lenen ze een transformer-model dat oorspronkelijk voor taal is gebouwd, waarbij aminozuursequenties als zinnen worden behandeld zodat het netwerk rijke contextuele ‘embeddings’ kan leren die beschrijven hoe elke positie zich verhoudt tot zijn buren langs de keten. Deze drie sets getallen worden samengevoegd tot een enkele, gedetailleerde beschrijving van elke plaats.
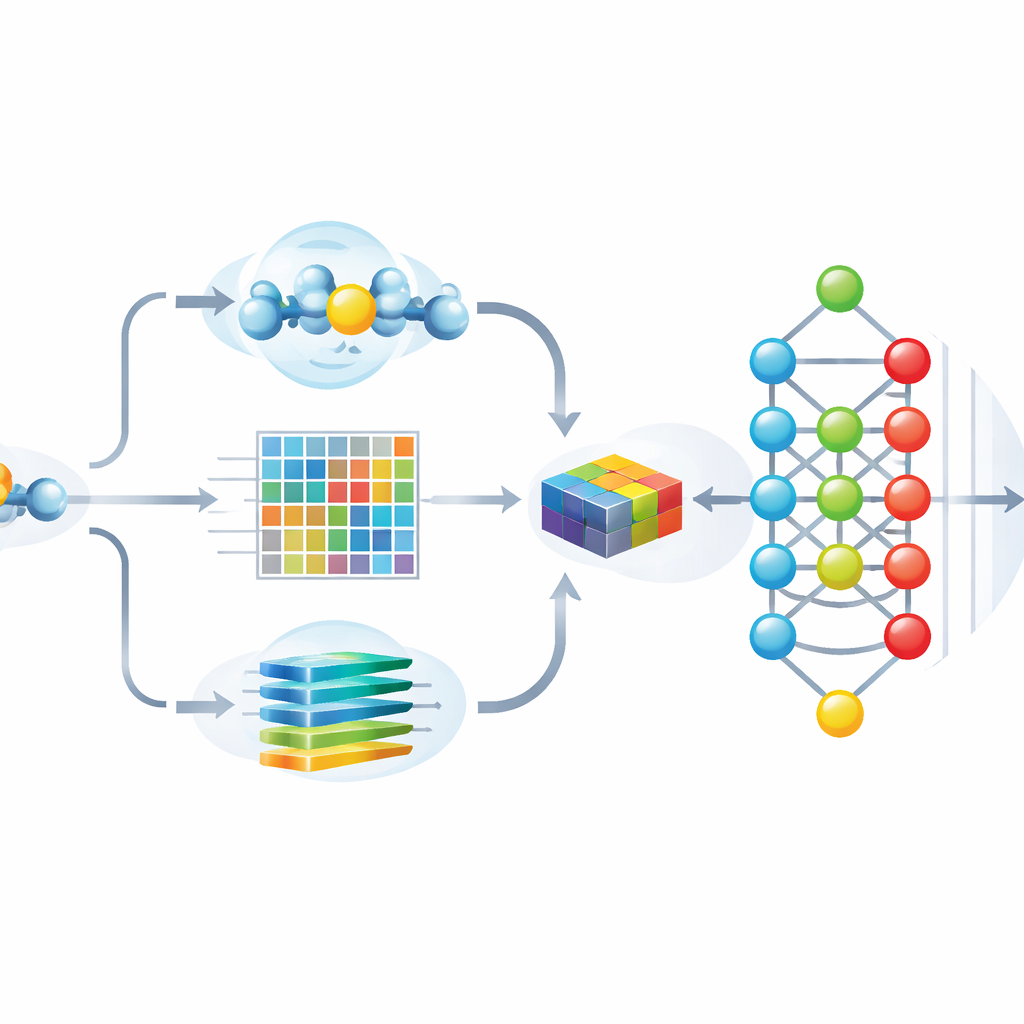
Het model zowel nauwkeurig als verklaarbaar maken
Het invoeren van meer dan duizend features in een diep neuraal netwerk kan de nauwkeurigheid verbeteren, maar vergroot ook het risico op overfitting en maakt het moeilijk om te zien welke aanwijzingen het model echt gebruikt. Om hiermee om te gaan, gebruikt het team een door speltheorie geïnspireerde techniek genaamd SHAP om te scoren hoeveel elke feature bijdraagt aan correcte voorspellingen. Ze behouden vervolgens alleen de meest informatieve 243 features, waardoor redundantie sterk wordt teruggesnoeid terwijl de prestatie behouden blijft. Visuele analyses tonen dat, na deze selectie, SUMO- en niet-SUMO-plaatsen goed gescheiden clusters vormen, en dat de belangrijkste features overeenkomen met intuïtieve eigenschappen zoals oppervlaktexposure, lokale lading en karakteristieke sequentiepatronen rond de gemodificeerde lysine.
Hybrid-Sumo aan de tand gevoeld
Om misleidende resultaten te voorkomen, bouwden de onderzoekers zorgvuldig gebalanceerde en ongebalanceerde datasets uit een gecureerde eiwitmodificatiedatabase, verwijderden bijna-duplicaten sequenties en evalueerden Hybrid-Sumo met herhaalde cross-validatie en volledig onafhankelijke testsets. Het uiteindelijke model bereikte ongeveer 99,7% nauwkeurigheid op trainingsdata en rond 96% nauwkeurigheid op niet-geziene eiwitten, iets maar consistent beter dan meerdere sterke deep learning- en ensemblemethoden die specifiek voor dezelfde taak waren ontwikkeld. Statistische tests bevestigden dat de winst door SHAP-gebaseerde featureselectie echt is en niet op toeval berust, en vergelijkingen met andere gangbare algoritmen toonden aan dat het voordeel voortkomt uit de hybride features en zorgvuldige optimalisatie, niet alleen uit de keuze voor een diep netwerk.
Wat dit voortaan betekent
Voor niet-specialisten is de kernboodschap dat Hybrid-Sumo een betrouwbaardere manier biedt om te voorspellen waar het SUMO-label op een eiwit zal landen, met een mix van 3D-structuur, evolutionaire signalen en moderne sequentie-‘taal’-modellen. Door proef-en-foutwerk in het lab te verminderen, kan het onderzoekers helpen om experimenten te prioriteren, te onderzoeken hoe SUMOylatie bijdraagt aan ziekte en uiteindelijk therapieën te sturen die deze subtiele eiwitschakelaar targeten of benutten. Dezelfde ontwerpprincipes — het combineren van diverse gezichtspunten op een molecuul en vervolgens interpreteerbare featureselectie toepassen — zouden ook aangepast kunnen worden om vele andere soorten eiwitmodificaties te voorspellen die ten grondslag liggen aan gezondheid en ziekte.
Bronvermelding: Alyahya, A.N., Khan, S., Dilshad, N. et al. Deep learning framework with interpretable feature selection for accurate SUMOylation site prediction. Sci Rep 16, 10419 (2026). https://doi.org/10.1038/s41598-026-41489-0
Trefwoorden: SUMOylatie, eiwitmodificatie, deep learning, featureselectie, bio-informatica