Clear Sky Science · zh
张量语言模型使生成式调度成为可能,从而实现高效张量编译
为什么更快的 AI 工具很重要
随着人工智能能力的增强,训练和运行大型神经网络需要大量计算时间和能量。在背后,称为编译器的专用程序把高级的 AI 模型转换为供 CPU、GPU 等芯片执行的低级指令。本文介绍了一种新方法,借用现代语言模型的思想,使这种转换快得多,且效率几乎可与当今最佳的手工调优方法相媲美。
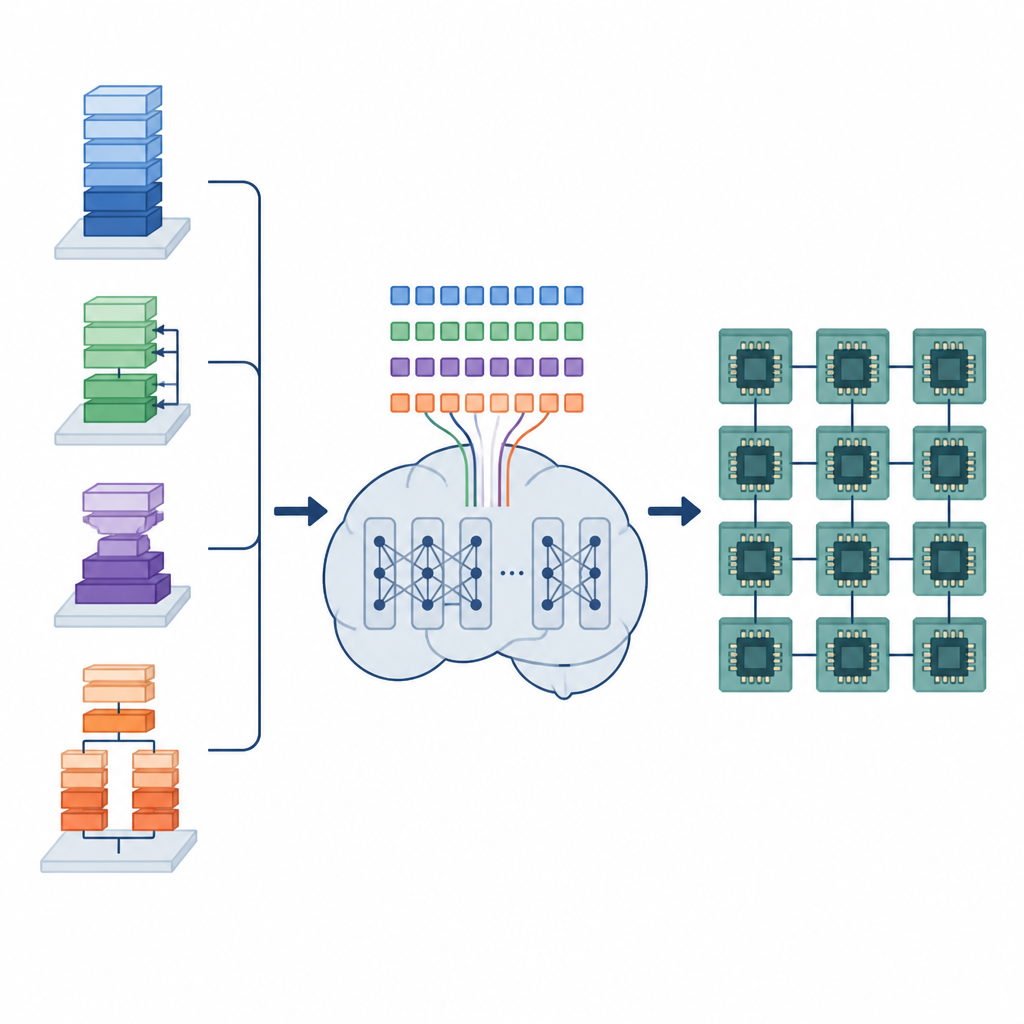
AI 编译器的幕后工作
深度学习模型依赖许多重复的数据操作,例如对大矩阵相乘或在图像上滑动滤波器。这些操作以称为张量程序的小型低级程序实现。为了在不同硬件上高效运行,每个张量程序必须被精心安排:循环需要切分成分块,工作需要在内核间分配,数据在内存中的布局要便于快速访问。现有的自动工具要么在海量可能性中搜索,这可能耗时数小时或数天,要么依赖固定规则,虽然编译速度快但可能牺牲大量性能。
将调度问题转为语言任务
作者提出了一个名为张量语言模型(TLM)的框架,将安排这些张量程序的问题视作写句子。他们设计了一种紧凑的“张量语言”,每个标记编码关于操作、硬件和调度选择的信息。一个类 GPT-2 的模型在数百万条这样的张量句子上训练,学习将特定算子与硬件设置映射到高效调度的模式。TLM 不再在编译时穷尽多种选项,而是像预测句子中的下一个词一样,单次生成一个良好的调度。
新系统的构成
该框架由两个主要部分组成。空间构建器(Space Builder)检查 AI 模型,将其拆分为较小的子图,并为每个子图构建完整的合法调度选项空间,同时不丢弃有希望的选择。然后将这个空间编码为张量句子。生成器(Generator)由训练好的 TLM 提供动力,读取这些句子及硬件提示并输出完整的调度决策序列。由于张量语言经过精心设计,每个生成的序列都对应一个有效的低级程序,可由现有的编译后端转换为可执行代码。
实验结果说明了什么
研究人员在来自流行视觉与语言模型(包括 ResNet-50、MobileNetV2、EfficientNet、BERT、GPT-2 和 LLAMA-7B)的张量程序上训练了 TLM。随后,他们将其与以搜索为基础的领先编译器(如 Ansor 和 MetaSchedule)以及名为 Roller 的快速启发式系统进行了比较。在大量测试工作负载中,TLM 生成的程序运行时间与搜索型工具相当或略优,而编译速度最快可提高约 61 倍。与 Roller 相比,TLM 的编译时间相当或更短,但生成的模型运行速度最多可快约 1.5 倍。这些收益从小子图延展到端到端完整模型,并且 TLM 在多次运行中能产生确定性的结果。
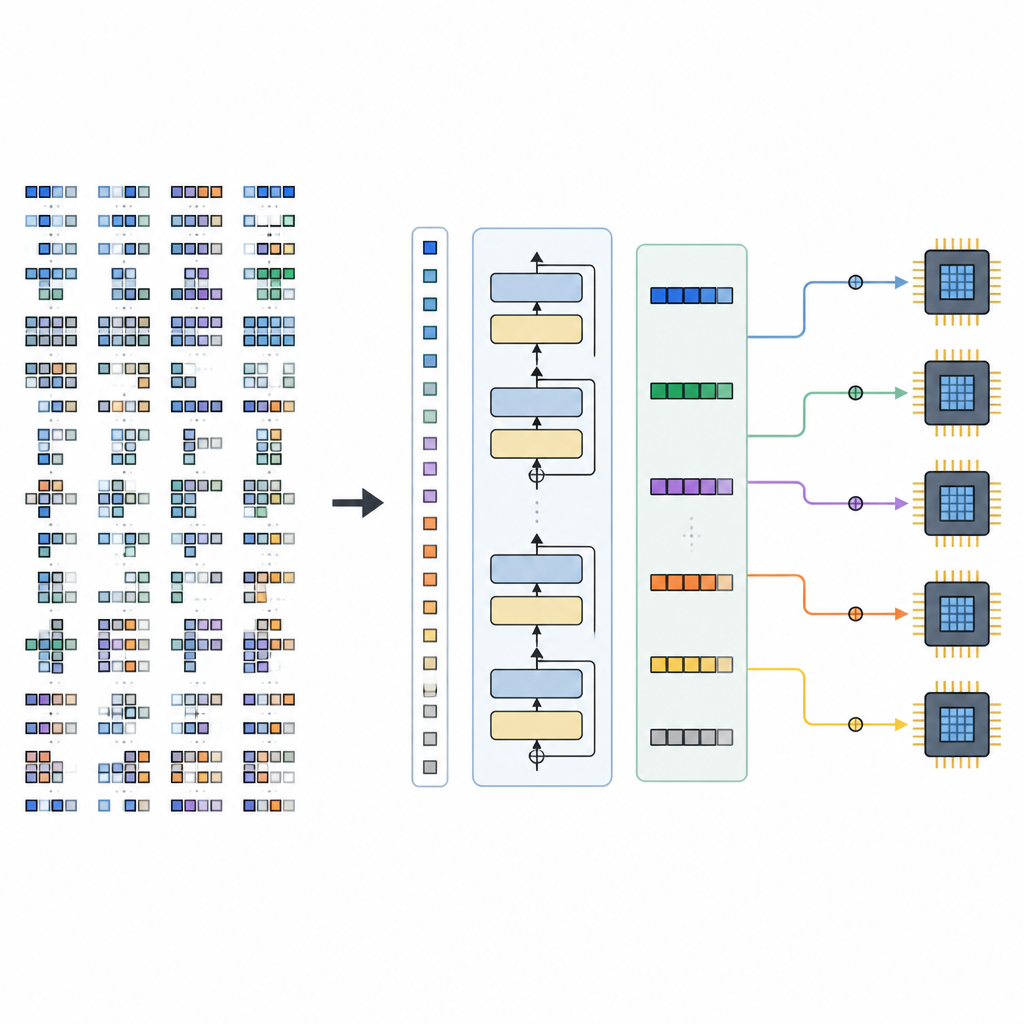
局限与未来方向
TLM 的收益取决于其训练数据对未来工作负载和硬件的覆盖程度。如果出现训练集中未包含的新型算子或芯片,生成的调度在加入更多示例并微调模型之前可能效率较低。训练 TLM 本身也需要大量资源,因为它需要数百万个示例张量程序。作者建议将该方法扩展到更大的语言模型、更广的算子集合和更多硬件平台,并可能采用轻量级的适配方法。
这对日常 AI 使用意味着什么
从实践角度看,这项工作表明快速编译与快速执行之间的昂贵权衡并非一成不变。通过从以往的优化经验中学习,基于语言模型的编译器可以几乎即时生成高效的低级代码。对于经常部署或更新大型 AI 模型的公司和研究人员而言,这样的系统可以显著缩短周转时间,同时将性能保持在当前工具可达到的最佳水平附近。
引用: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
关键词: 张量编译, 深度学习编译器, 语言模型, GPU 优化, 模型调度