Clear Sky Science · sv
Tensormodellspråk möjliggör generativ schemaläggning för effektiv tensorkompilering
Varför snabbare AI‑verktyg spelar roll
När artificiell intelligens blir allt kraftfullare kan träning och körning av stora neurala nätverk kräva enorma mängder beräkningstid och energi. I bakgrunden översätter särskilda program, så kallade kompilatorer, hög‑nivå AI‑modeller till lågnivåinstruktioner för kretsar som CPU:er och GPU:er. Denna artikel introducerar ett nytt sätt att göra den översättningen mycket snabbare och nästan lika effektiv som dagens bästa handjusterade metoder, med idéer hämtade från moderna språkmodeller.
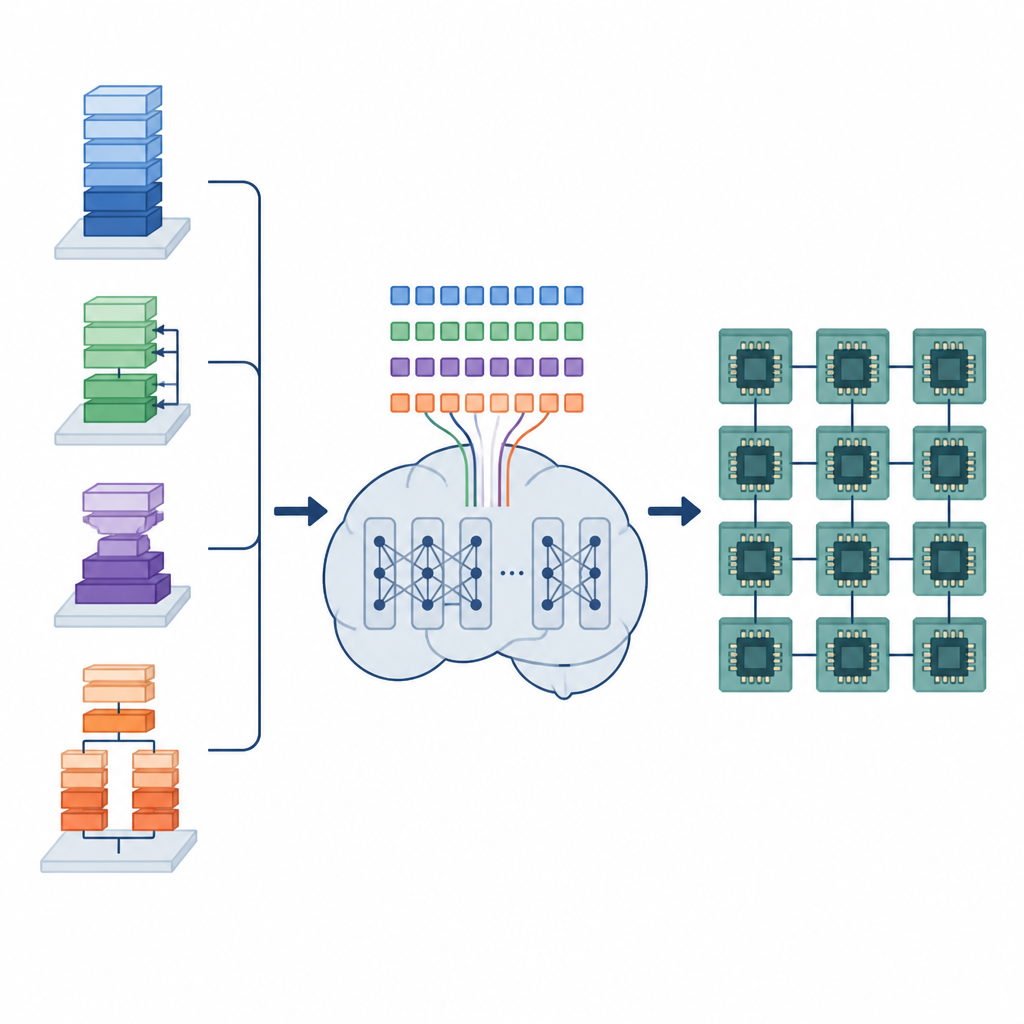
AI‑kompilatorernas dolda arbete
Modeller för djupinlärning förlitar sig på många upprepade dataoperationer, såsom multiplikation av stora matriser eller att skjutande filter över bilder. Dessa operationer implementeras som små lågnivåprogram kallade tensorprogram. För att fungera väl på olika hårdvaror måste varje tensorprogram arrangeras noggrant: slingor (loops) måste delas upp i plattor (tiling), arbete fördelas över kärnor och data läggs ut i minnet så att det kan hämtas snabbt. Befintliga automatiska verktyg antingen söker igenom ett enormt antal möjligheter, vilket kan ta timmar eller dagar, eller förlitar sig på fasta regler som kompilerar snabbt men som kan lämna mycket prestanda outnyttjad.
Att göra schemaläggning till en språkuppgift
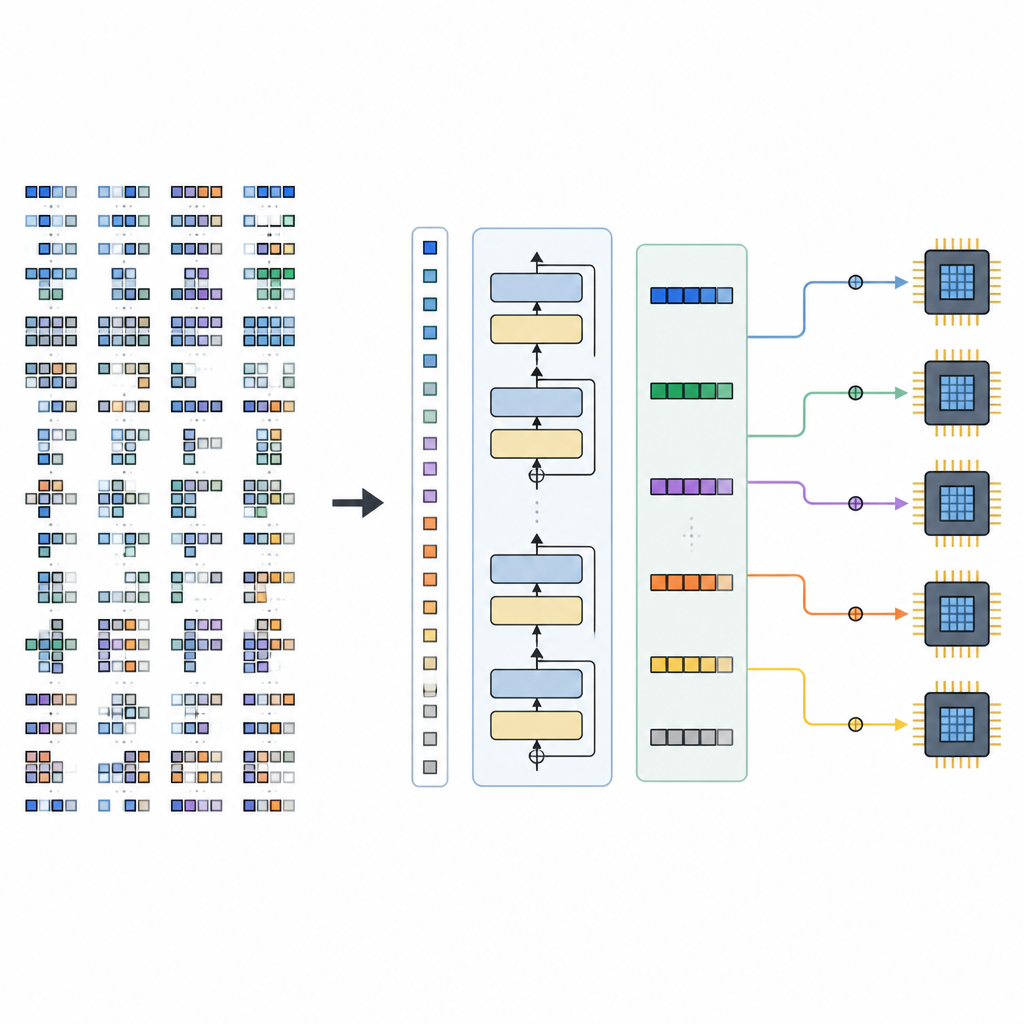
Författarna föreslår ett ramverk kallat Tensor Language Model (TLM) som behandlar problemet att arrangera dessa tensorprogram som om det vore att skriva en mening. De utformar ett kompakt ”tensor‑språk” där varje token kodar information om operationen, hårdvaran och ett schemaläggningsval. En GPT‑2‑liknande modell tränas på miljontals sådana tensormeningar och lär sig mönster som kopplar vissa operatorer och hårdvarukonfigurationer till effektiva scheman. Istället för att utforska många alternativ vid kompilering genererar TLM i ett enda svep ett bra schema, ungefär som att förutsäga nästa ord i en mening.
Hur det nya systemet är uppbyggt
Ramverket har två huvuddelar. En Space Builder undersöker en AI‑modell, bryter ner den i mindre delgrafer och konstruerar hela utbudet av lagliga schemaläggningsalternativ för varje del, utan att kasserar lovande val. Detta utrymme kodas sedan till tensormeningar. En Generator, driven av den tränade TLM, läser dessa meningar tillsammans med hårdvaruhintar och returnerar en komplett sekvens av schemaläggningsbeslut. Eftersom tensorspråket är omsorgsfullt designat motsvarar varje genererad sekvens ett giltigt lågnivåprogram som kan omvandlas till körbar kod av en befintlig kompilatorbackend.
Vad experimenten visar
Forskarna tränade TLM på tensorprogram hämtade från populära bild‑ och språkmodeller, inklusive ResNet‑50, MobileNetV2, EfficientNet, BERT, GPT‑2 och LLAMA‑7B. De jämförde den sedan med ledande sökbaserade kompilatorer som Ansor och MetaSchedule, samt med ett snabbt heuristiskt system kallat Roller. Över många testarbetslaster producerade TLM program vars körtid matchade eller marginellt överträffade de sökbaserade verktygen, samtidigt som kompileringstiden var upp till cirka 61 gånger kortare. Jämfört med Roller kompilerade den i liknande eller kortare tid men körde modeller upp till ungefär 1,5 gånger snabbare. Dessa vinster höll i sig från små delgrafer till fullständiga end‑to‑end‑modeller, och TLM gav deterministiska resultat från körning till körning.
Begränsningar och framtida riktningar
Fördelarna med TLM beror på hur väl dess träningsdata täcker framtida arbetslaster och hårdvara. Om en helt ny typ av operator eller krets dyker upp som inte fanns med i träningssetet kan de genererade schemana vara mindre effektiva tills fler exempel läggs till och modellen finjusteras. Att träna TLM är också resurskrävande eftersom det kräver miljontals exempel på tensorprogram. Författarna föreslår att tillämpa metoden på större språkmodeller, bredare uppsättningar operatorer och fler hårdvaruplattformar, eventuellt med lätta anpassningsmetoder.
Vad det innebär för vardaglig AI‑användning
I praktiska termer visar detta arbete att den kostsamma avvägningen mellan snabb kompilering och snabb exekvering inte är oföränderlig. Genom att lära av tidigare optimeringserfarenhet kan en språkmodell‑baserad kompilator generera effektiv lågnivåkod nästan omedelbart. För företag och forskare som ofta driftsätter eller uppdaterar stora AI‑modeller kan ett sådant system kraftigt förkorta ledtiderna samtidigt som prestandan hålls nära det bästa som nuvarande verktyg kan uppnå.
Citering: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Nyckelord: tensorkompilering, kompilatorer för djupinlärning, språkmodeller, GPU‑optimering, modell‑schemaläggning