Clear Sky Science · nl
Tensor-taalmodel maakt generatieve planning mogelijk voor efficiënte tensorcompilatie
Waarom snellere AI-tools ertoe doen
Naarmate kunstmatige intelligentie krachtiger wordt, vergen het trainen en uitvoeren van grote neurale netwerken enorme hoeveelheden rekentijd en energie. Achter de schermen zetten speciale programma’s, compilers genoemd, AI-modellen van hoge naar lage niveaus om in instructies voor chips zoals CPU’s en GPU’s. Dit artikel introduceert een nieuwe manier om die vertaling veel sneller en bijna net zo efficiënt te maken als de beste hand-afgestemde methoden van vandaag, door ideeën uit moderne taalmodellen te gebruiken.
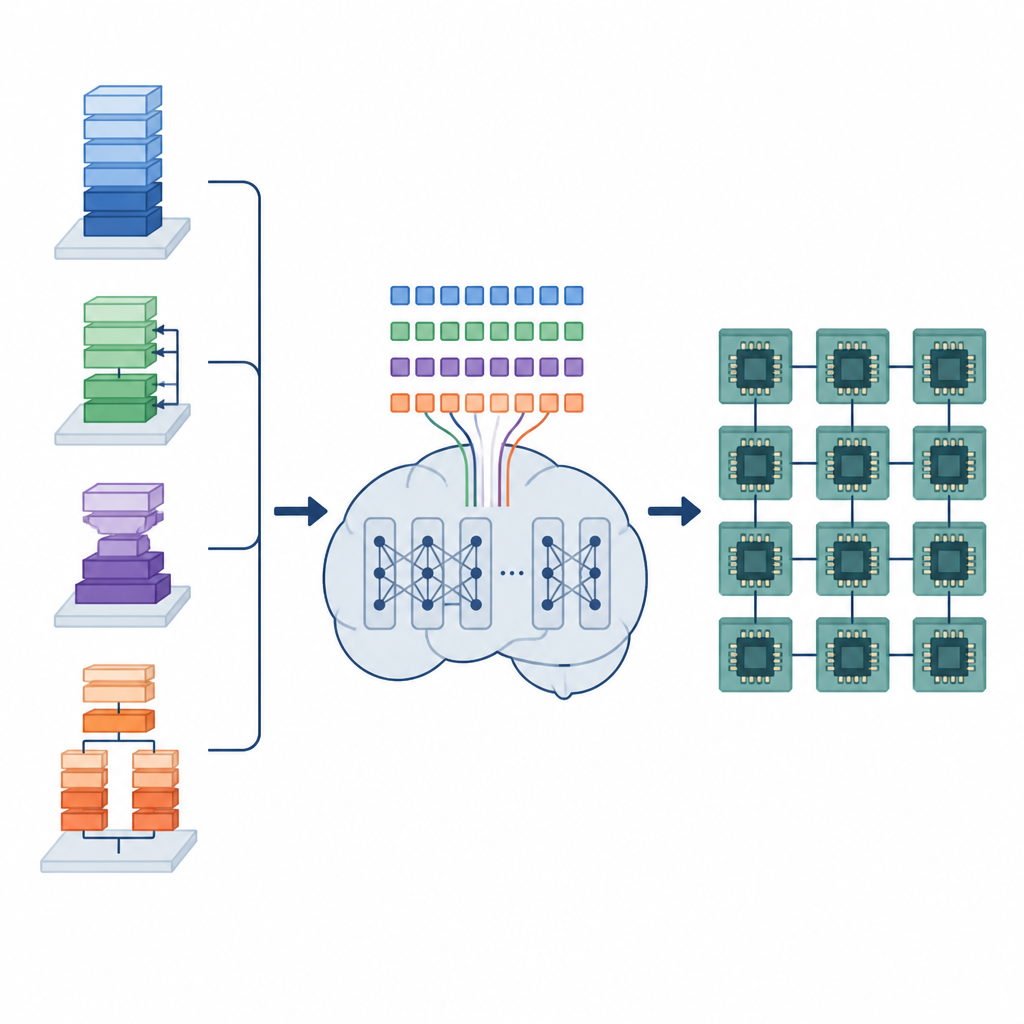
Het verborgen werk van AI-compilers
Deep-learningmodellen vertrouwen op veel herhaalde data-operaties, zoals het vermenigvuldigen van grote matrices of het schuiven van filters over beelden. Deze operaties worden uitgevoerd als kleine laag-niveau programma’s, tensorprogramma’s genoemd. Om goed te presteren op verschillende hardware moet elk tensorprogramma zorgvuldig worden ingericht: lussen moeten in tegels worden verdeeld, werk verdeeld over cores en data in het geheugen zo geplaatst dat het snel opgehaald kan worden. Bestaande automatische tools doorzoeken ofwel een enorme ruimte aan mogelijkheden, wat uren of dagen kan duren, of vertrouwen op vaste regels die snel compileren maar vaak veel prestatiepotentieel laten liggen.
Planning veranderen in een taaltaak
De auteurs stellen een raamwerk voor dat ze het Tensor Language Model (TLM) noemen en dat het probleem van het inrichten van deze tensorprogramma’s behandelt alsof het een zin schrijven is. Ze ontwerpen een compacte “tensor-taal” waarin elk token informatie codeert over de operatie, de hardware en een planningskeuze. Een GPT-2-achtig model wordt getraind op miljoenen van deze tensor-zinnen en leert patronen die bepaalde operators en hardwareconfiguraties koppelen aan efficiënte schemas. In plaats van veel opties te verkennen tijdens compilatie, genereert TLM in één enkele doorgang één goed schema, vergelijkbaar met het voorspellen van het volgende woord in een zin.
Hoe het nieuwe systeem is opgebouwd
Het raamwerk heeft twee hoofdonderdelen. Een Space Builder bekijkt een AI-model, splitst het in kleinere subgrafen en construeert het volledige bereik aan toegestane planningsopties voor elk deel, zonder veelbelovende keuzes weg te gooien. Deze ruimte wordt vervolgens gecodeerd in tensor-zinnen. Een Generator, aangedreven door het getrainde TLM, leest deze zinnen samen met hardware aanwijzingen en geeft een complete reeks planningsbeslissingen uit. Omdat de tensor-taal zorgvuldig is ontworpen, correspondeert elke gegenereerde reeks met een geldig laag-niveau programma dat door een bestaande compiler-backend in uitvoerbare code kan worden omgezet.
Wat de experimenten aantonen
De onderzoekers trainden TLM op tensorprogramma’s afkomstig uit populaire visuele en taalmodellen, waaronder ResNet-50, MobileNetV2, EfficientNet, BERT, GPT-2 en LLAMA-7B. Ze vergeleken het vervolgens met toonaangevende zoekgebaseerde compilers zoals Ansor en MetaSchedule, en met een snelle heuristische aanpak genaamd Roller. Over veel test-workloads produceerde TLM programma’s waarvan de uitvoeringstijd gelijk was aan of iets beter dan die van de zoekgebaseerde tools, terwijl het compileren tot ongeveer 61 keer sneller ging. In vergelijking met Roller compileerde het in vergelijkbare of kortere tijd maar draaiden de modellen tot ongeveer 1,5 keer sneller. Deze winst strekte zich uit van kleine subgrafen tot volledige end-to-end modellen, en TLM leverde deterministische resultaten van run tot run.
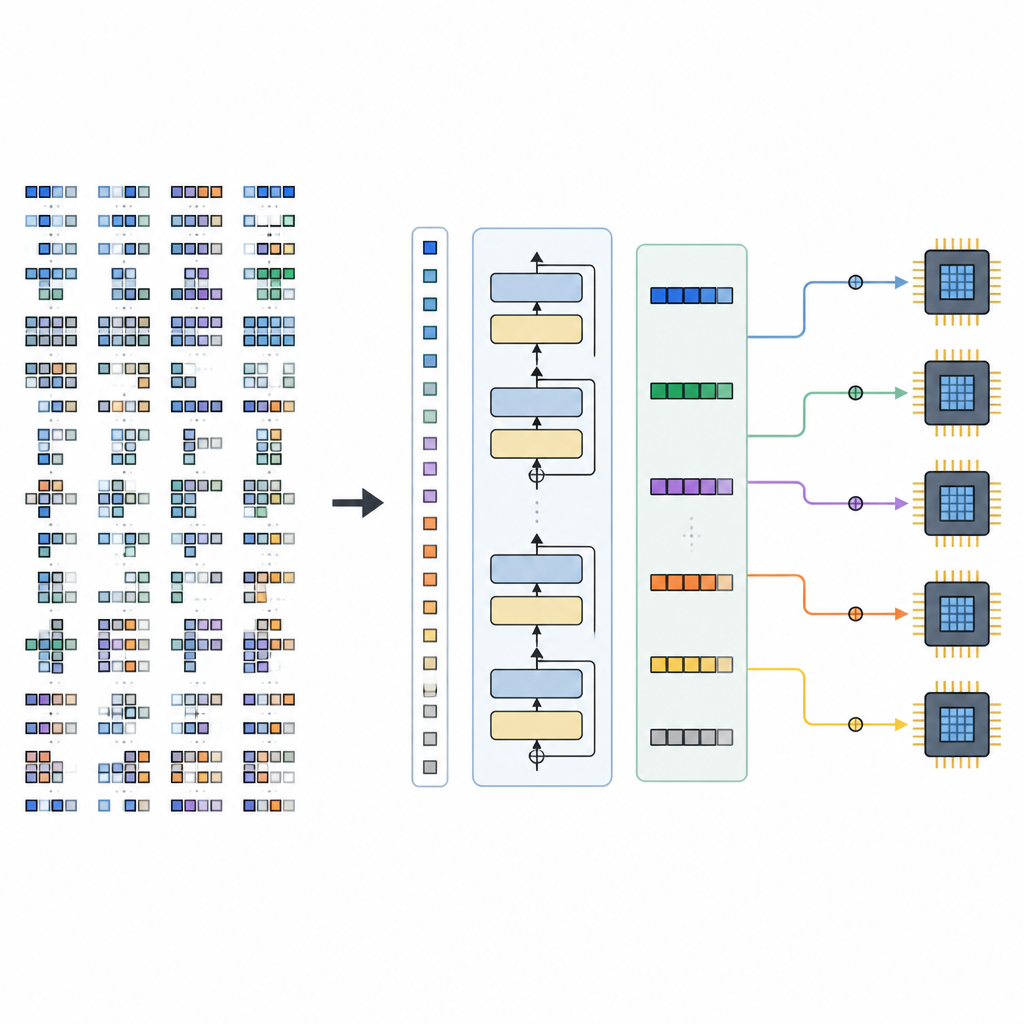
Beperkingen en toekomstige richtingen
De voordelen van TLM hangen af van hoe goed de trainingsdata toekomstige workloads en hardware dekt. Als er een gloednieuw type operator of chip verschijnt dat niet in de trainingsset vertegenwoordigd was, kunnen de gegenereerde schemas minder efficiënt zijn totdat er meer voorbeelden worden toegevoegd en het model wordt bijgestuurd. Het trainen van TLM zelf is ook resources-intensief, omdat het miljoenen voorbeeld-tensorprogramma’s vereist. De auteurs suggereren de aanpak uit te breiden naar grotere taalmodellen, bredere sets van operators en extra hardwareplatforms, mogelijk met lichte aanpassingsmethoden.
Wat dit betekent voor alledaags AI-gebruik
Praktisch gezien toont dit werk aan dat de kostbare afweging tussen snelle compilatie en snelle uitvoering geen onveranderlijke beperking hoeft te zijn. Door te leren van eerdere optimalisatie-ervaring kan een compiler gebaseerd op een taalmodel bijna direct efficiënte laag-niveau code genereren. Voor bedrijven en onderzoekers die vaak grote AI-modellen uitrollen of bijwerken, kan zo’n systeem de doorlooptijden aanzienlijk verkorten terwijl de prestaties dicht bij het beste blijven dat huidige tools kunnen bereiken.
Bronvermelding: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Trefwoorden: tensorcompilatie, compilers voor deep learning, taalmodellen, GPU-optimalisatie, modelplanning