Clear Sky Science · de
Tensor-Sprachmodell ermöglicht generative Zeitplanung für effiziente Tensor-Kompilierung
Warum schnellere KI-Werkzeuge wichtig sind
Mit der zunehmenden Leistungsfähigkeit künstlicher Intelligenz können das Training und das Ausführen großer neuronaler Netze enorme Rechenzeit und Energie erfordern. Im Hintergrund übersetzen spezielle Programme, sogenannte Compiler, hochrangige KI-Modelle in niedrigstufige Anweisungen für Chips wie CPUs und GPUs. Dieses Papier stellt eine neue Methode vor, diese Übersetzung deutlich schneller und nahezu so effizient wie heutige handoptimierte Verfahren zu machen – mithilfe von Ideen aus modernen Sprachmodellen.
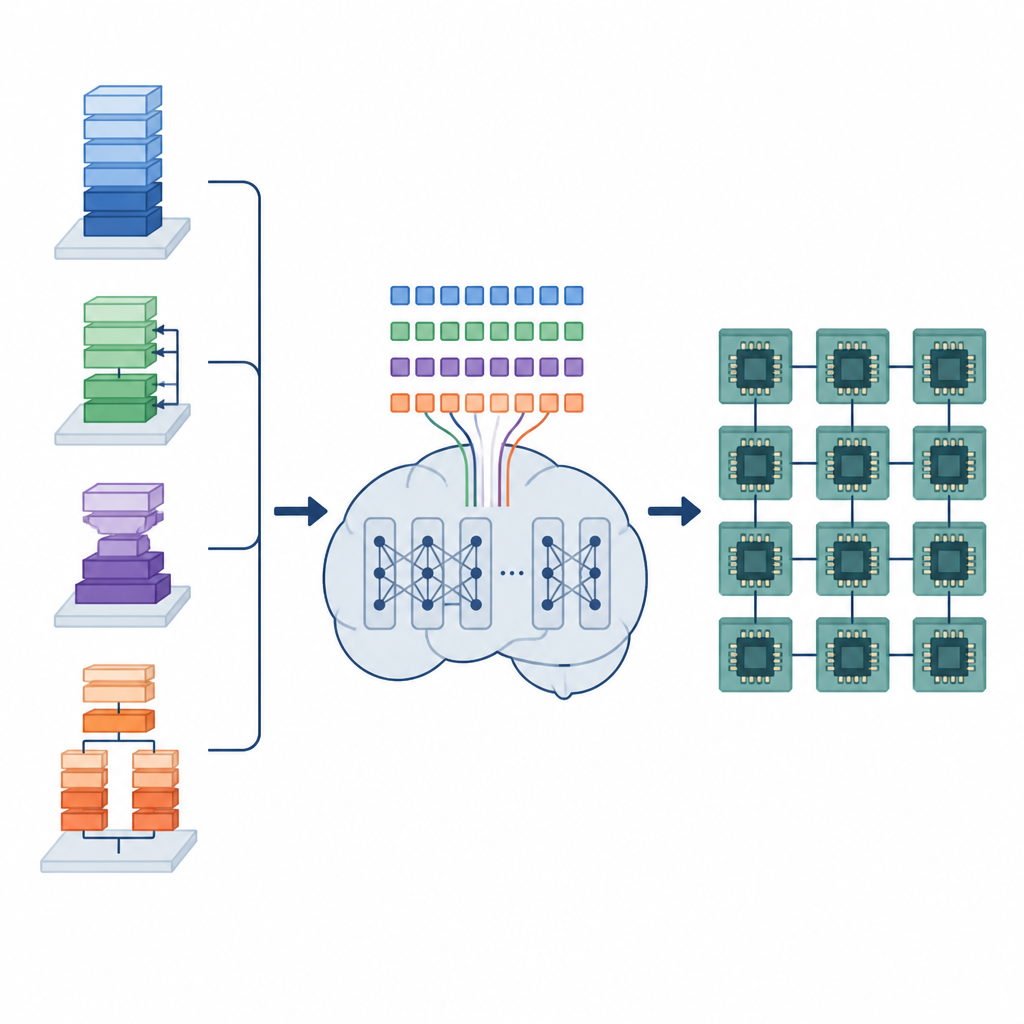
Die verborgene Arbeit von KI-Compilern
Deep-Learning-Modelle basieren auf vielen sich wiederholenden Datenoperationen, etwa dem Multiplizieren großer Zahlenfelder oder dem Anwenden von Filtern auf Bilder. Diese Operationen werden als kleine, niedrigstufige Programme implementiert, die Tensorprogramme heißen. Damit sie auf unterschiedlicher Hardware gut laufen, muss jedes Tensorprogramm sorgfältig angeordnet werden: Schleifen werden in Kacheln gebrochen, Arbeiten auf Kerne verteilt und Daten so im Speicher angeordnet, dass sie schnell geladen werden können. Bestehende automatische Werkzeuge durchsuchen entweder eine riesige Menge von Möglichkeiten, was Stunden oder Tage dauern kann, oder stützen sich auf feste Regeln, die schnell kompilieren, aber oft Leistung ungenutzt lassen.
Die Zeitplanung als Sprachaufgabe
Die Autoren schlagen ein Framework namens Tensor Language Model (TLM) vor, das das Problem der Anordnung dieser Tensorprogramme so behandelt, als würde man einen Satz schreiben. Sie entwerfen eine kompakte „Tensor-Sprache“, in der jedes Token Informationen über die Operation, die Hardware und eine Zeitplanungsentscheidung kodiert. Ein Modell im Stil von GPT-2 wird mit Millionen solcher Tensor-Sätze trainiert und lernt Muster, die bestimmte Operatoren und Hardwarekonfigurationen mit effizienten Zeitplänen verknüpfen. Anstatt zur Kompilierzeit viele Optionen zu durchsuchen, erzeugt TLM in einem Durchgang einen guten Zeitplan – ähnlich dem Vorhersagen des nächsten Wortes in einem Satz.
Wie das neue System zusammengebaut ist
Das Framework besteht aus zwei Hauptteilen. Ein Space Builder analysiert ein KI-Modell, zerlegt es in kleinere Teilgraphen und konstruiert den vollständigen Bereich an zulässigen Zeitplanungsoptionen für jedes Teil, ohne vielversprechende Alternativen auszuschließen. Dieser Raum wird dann in Tensor-Sätze kodiert. Ein Generator, angetrieben vom trainierten TLM, liest diese Sätze zusammen mit Hardware-Hinweisen und liefert eine vollständige Folge von Zeitplanungsentscheidungen. Da die Tensor-Sprache sorgfältig gestaltet ist, entspricht jede erzeugte Sequenz einem gültigen niedrigstufigen Programm, das von einem vorhandenen Compiler-Backend in ausführbaren Code überführt werden kann.
Was die Experimente zeigen
Die Forscher trainierten TLM mit Tensorprogrammen aus verbreiteten Vision- und Sprachmodellen, darunter ResNet-50, MobileNetV2, EfficientNet, BERT, GPT-2 und LLAMA-7B. Anschließend verglichen sie es mit führenden suchbasierten Compilern wie Ansor und MetaSchedule sowie mit einem schnellen heuristischen System namens Roller. Über viele Testlasten erzeugte TLM Programme, deren Laufzeiten denen der Suchwerkzeuge entsprachen oder diese leicht übertrafen, während die Kompilierung bis zu etwa 61-mal schneller erfolgte. Im Vergleich zu Roller kompilierte es in ähnlicher oder geringerer Zeit, lief aber in einigen Modellen bis zu etwa 1,5-mal schneller. Diese Verbesserungen zeigten sich sowohl bei kleinen Teilgraphen als auch bei vollständigen End-to-End-Modellen, und TLM lieferte deterministische Ergebnisse von Lauf zu Lauf.
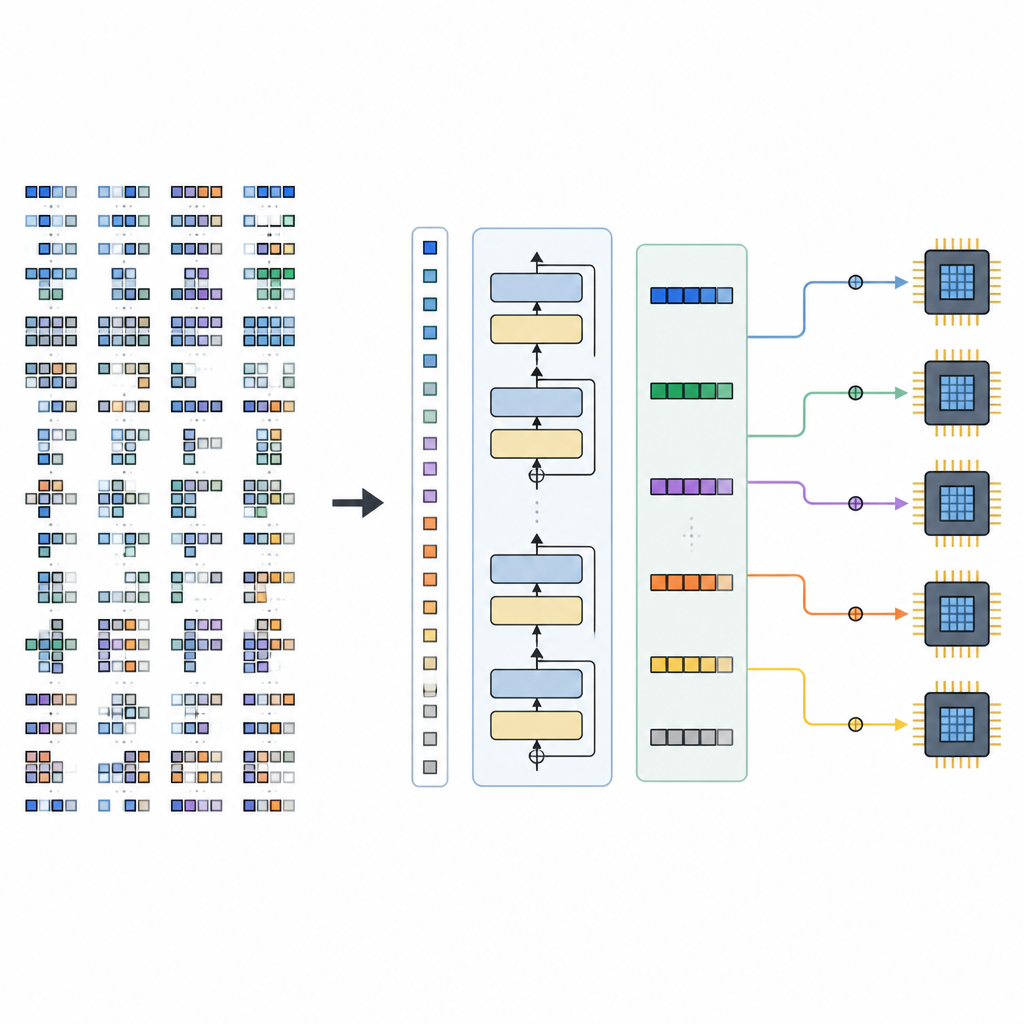
Grenzen und künftige Richtungen
Die Vorteile von TLM hängen davon ab, wie gut die Trainingsdaten zukünftige Arbeitslasten und Hardware abdecken. Taucht ein völlig neuer Operator oder Chip auf, der im Trainingssatz nicht vertreten war, können die erzeugten Zeitpläne weniger effizient sein, bis weitere Beispiele hinzugefügt und das Modell feinabgestimmt wird. Auch das Training von TLM selbst ist ressourcenintensiv, da Millionen von Beispiel-Tensorprogrammen benötigt werden. Die Autoren schlagen vor, den Ansatz auf größere Sprachmodelle, breitere Operatorsätze und zusätzliche Hardwareplattformen auszuweiten, möglicherweise mit leichten Anpassungsmethoden.
Was das für den alltäglichen KI-Einsatz bedeutet
Praktisch zeigt diese Arbeit, dass der kostspielige Kompromiss zwischen schneller Kompilierung und schneller Ausführung nicht in Stein gemeißelt ist. Durch das Lernen aus vergangener Optimierungserfahrung kann ein sprachmodellbasierter Compiler effizienten niedrigstufigen Code nahezu sofort erzeugen. Für Unternehmen und Forschende, die häufig große KI-Modelle bereitstellen oder aktualisieren, könnte ein solches System die Durchlaufzeiten erheblich verkürzen und gleichzeitig die Leistung nahe an die besten verfügbaren Werkzeuge heranführen.
Zitation: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Schlüsselwörter: Tensor-Kompilierung, Deep-Learning-Compiler, Sprachmodelle, GPU-Optimierung, Modellzeitplanung