Clear Sky Science · fr
Un modèle de langage pour tenseurs permet une planification générative pour une compilation de tenseurs efficace
Pourquoi des outils d’IA plus rapides comptent
À mesure que l’intelligence artificielle gagne en puissance, l’entraînement et l’exécution de grands réseaux neuronaux exigent d’énormes quantités de temps de calcul et d’énergie. En coulisses, des programmes spécialisés appelés compilateurs transforment des modèles d’IA de haut niveau en instructions de bas niveau pour des puces comme les CPU et GPU. Cet article introduit une nouvelle façon d’accélérer fortement cette traduction tout en restant presque aussi efficace que les meilleures méthodes ajustées manuellement, en empruntant des idées aux modèles de langage modernes.
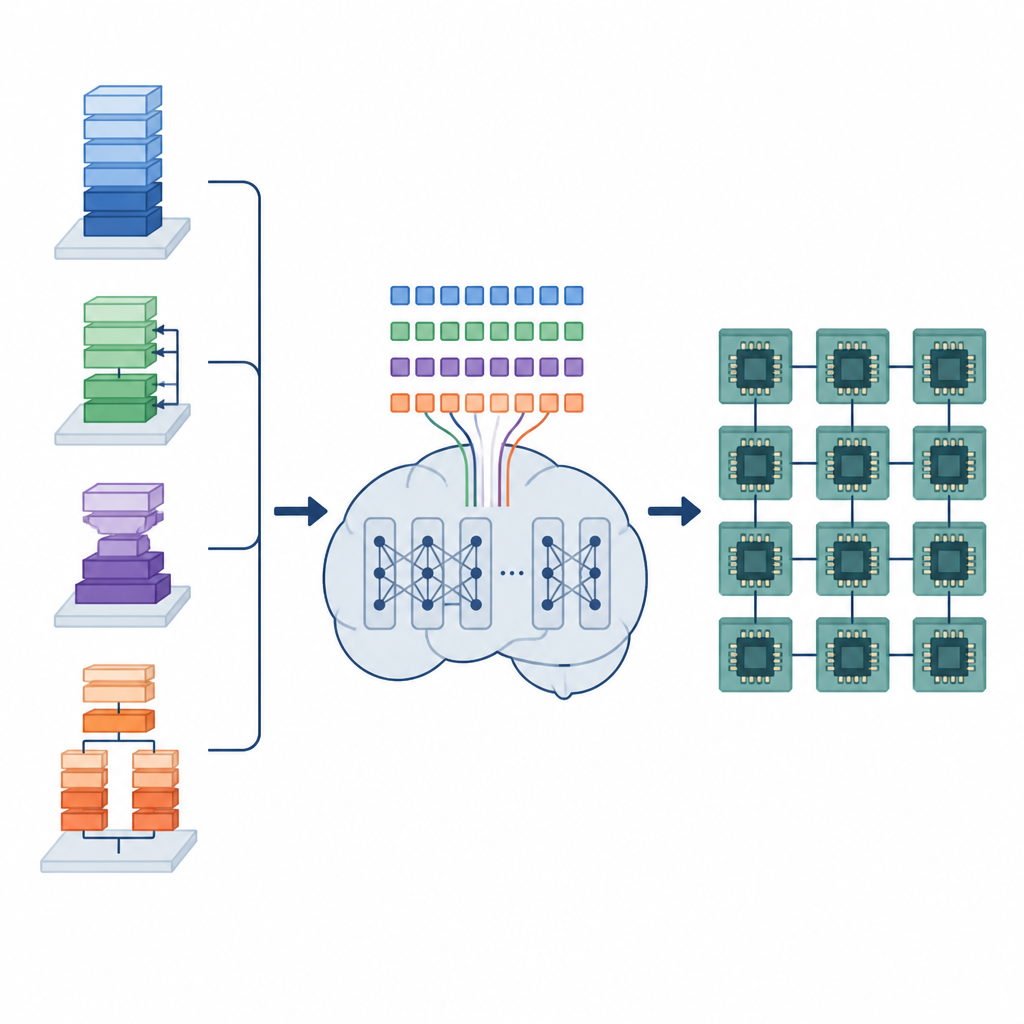
Le travail caché des compilateurs d’IA
Les modèles d’apprentissage profond reposent sur de nombreuses opérations de données répétées, comme la multiplication de grandes matrices ou le glissement de filtres sur des images. Ces opérations sont implémentées sous forme de petits programmes de bas niveau appelés programmes de tenseurs. Pour bien s’exécuter sur différents matériels, chaque programme de tenseur doit être soigneusement arrangé : les boucles doivent être tuilées, le travail réparti entre les cœurs, et les données disposées en mémoire pour des accès rapides. Les outils automatiques existants parcourent soit un vaste espace de possibilités, ce qui peut prendre des heures ou des jours, soit s’appuient sur des règles fixes qui compilent rapidement mais peuvent laisser beaucoup de performances sur la table.
Transformer l’ordonnancement en tâche linguistique
Les auteurs proposent un cadre appelé Tensor Language Model (TLM) qui considère le problème d’arrangement de ces programmes de tenseurs comme s’il s’agissait d’écrire une phrase. Ils conçoivent un « langage de tenseur » compact où chaque jeton encode des informations sur l’opération, le matériel et un choix d’ordonnancement. Un modèle de type GPT-2 est entraîné sur des millions de ces « phrases de tenseurs », apprenant des motifs qui lient certains opérateurs et configurations matérielles à des ordonnancements efficaces. Plutôt que d’explorer de nombreuses options au moment de la compilation, TLM génère en une seule passe un ordonnancement de qualité, de la même façon qu’on prédit le mot suivant dans une phrase.
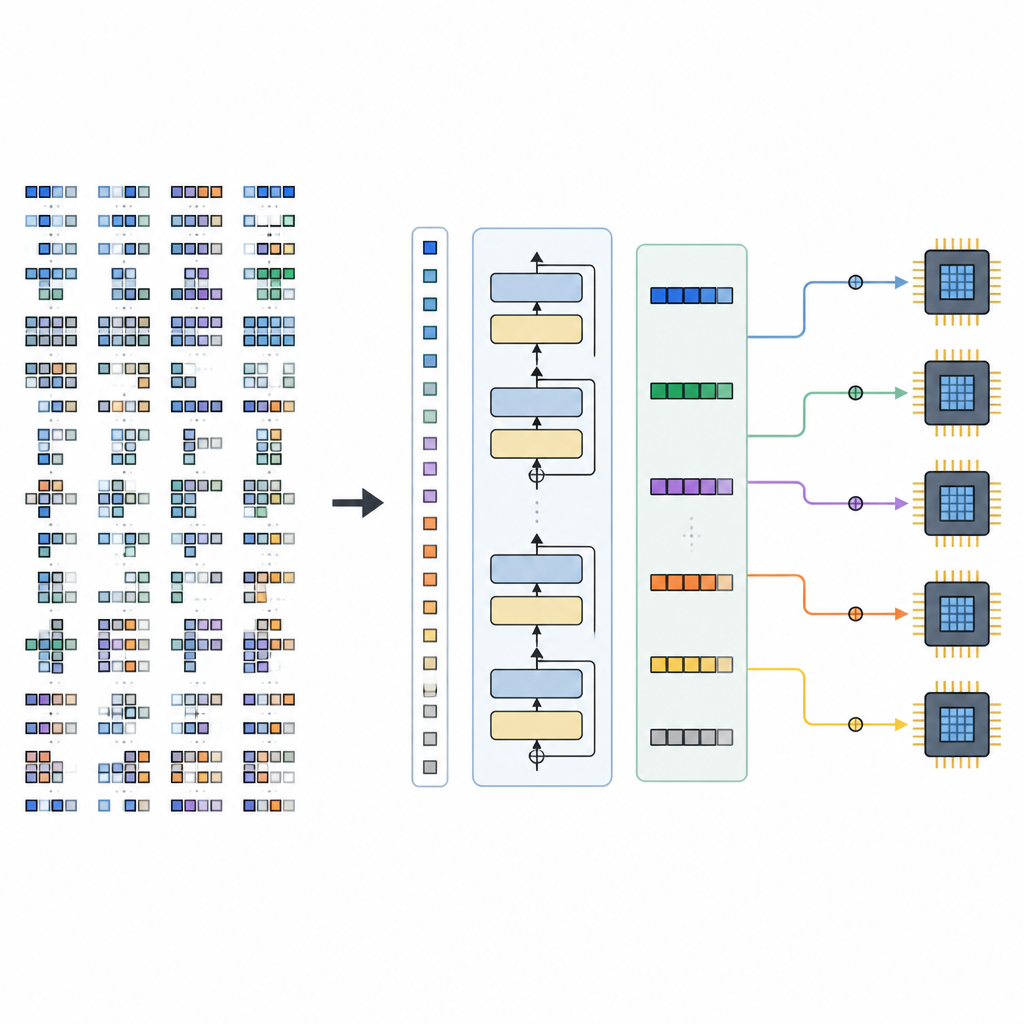
Comment le nouveau système est construit
Le cadre comporte deux parties principales. Un Space Builder examine un modèle d’IA, le découpe en sous-graphes plus petits et construit l’ensemble des options d’ordonnancement légales pour chaque fragment, sans éliminer les choix prometteurs. Cet espace est ensuite encodé en phrases de tenseurs. Un Generator, propulsé par le TLM entraîné, lit ces phrases avec des indices matériels et produit une séquence complète de décisions d’ordonnancement. Parce que le langage de tenseur est soigneusement conçu, chaque séquence générée correspond à un programme de bas niveau valide qui peut être transformé en code exécutable par un backend de compilateur existant.
Ce que montrent les expériences
Les chercheurs ont entraîné TLM sur des programmes de tenseurs issus de modèles de vision et de langage populaires, notamment ResNet-50, MobileNetV2, EfficientNet, BERT, GPT-2 et LLAMA-7B. Ils l’ont ensuite comparé à des compilateurs basés sur la recherche leader comme Ansor et MetaSchedule, ainsi qu’à un système heuristique rapide appelé Roller. Sur de nombreux jeux de tests, TLM a produit des programmes dont le temps d’exécution égalait ou surpassait légèrement les outils basés sur la recherche, tout en compilant jusqu’à environ 61 fois plus rapidement. Par rapport à Roller, il compilait en un temps similaire ou inférieur tout en exécutant les modèles jusqu’à environ 1,5 fois plus vite. Ces gains se sont maintenus des petits sous-graphes aux modèles complets de bout en bout, et TLM produisait des résultats déterministes d’une exécution à l’autre.
Limites et pistes futures
Les bénéfices de TLM dépendent de la couverture par ses données d’entraînement des charges de travail et matériels futurs. Si un type d’opérateur ou de puce totalement nouveau apparaît et n’était pas représenté dans l’ensemble d’entraînement, les ordonnancements générés pourraient être moins efficaces jusqu’à l’ajout d’exemples et le réglage du modèle. L’entraînement de TLM lui-même est aussi gourmand en ressources, puisqu’il nécessite des millions d’exemples de programmes de tenseurs. Les auteurs suggèrent d’étendre l’approche à des modèles de langage plus grands, à un ensemble d’opérateurs plus vaste et à d’autres plateformes matérielles, éventuellement avec des méthodes d’adaptation légères.
Ce que cela signifie pour l’usage courant de l’IA
Concrètement, ce travail montre que le compromis coûteux entre compilation rapide et exécution rapide n’est pas immuable. En apprenant de l’expérience d’optimisation passée, un compilateur basé sur un modèle de langage peut générer presque instantanément du code bas niveau efficace. Pour les entreprises et les chercheurs qui déploient ou mettent à jour fréquemment de grands modèles d’IA, un tel système pourrait réduire fortement les délais tout en maintenant des performances proches des meilleurs outils actuels.
Citation: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Mots-clés: compilation de tenseurs, compilateurs pour apprentissage profond, modèles de langage, optimisation GPU, ordonnancement de modèles