Clear Sky Science · en
Tensor language model enables generative scheduling for efficient tensor compilation
Why faster AI tools matter
As artificial intelligence grows more powerful, training and running large neural networks can take huge amounts of computing time and energy. Behind the scenes, special programs called compilers turn high-level AI models into low-level instructions for chips like CPUs and GPUs. This paper introduces a new way to make that translation much faster and almost as efficient as today’s best hand-tuned methods, using ideas borrowed from modern language models.
The hidden work of AI compilers
Deep learning models rely on many repeated data operations, such as multiplying big grids of numbers or sliding filters over images. These operations are implemented as tiny low-level programs called tensor programs. To run well on different hardware, each tensor program must be arranged carefully: loops must be broken into tiles, work spread across cores, and data laid out in memory so it can be fetched quickly. Existing automatic tools either search through a vast number of possibilities, which can take hours or days, or rely on fixed rules that compile quickly but may leave a lot of performance on the table.
Turning scheduling into a language task
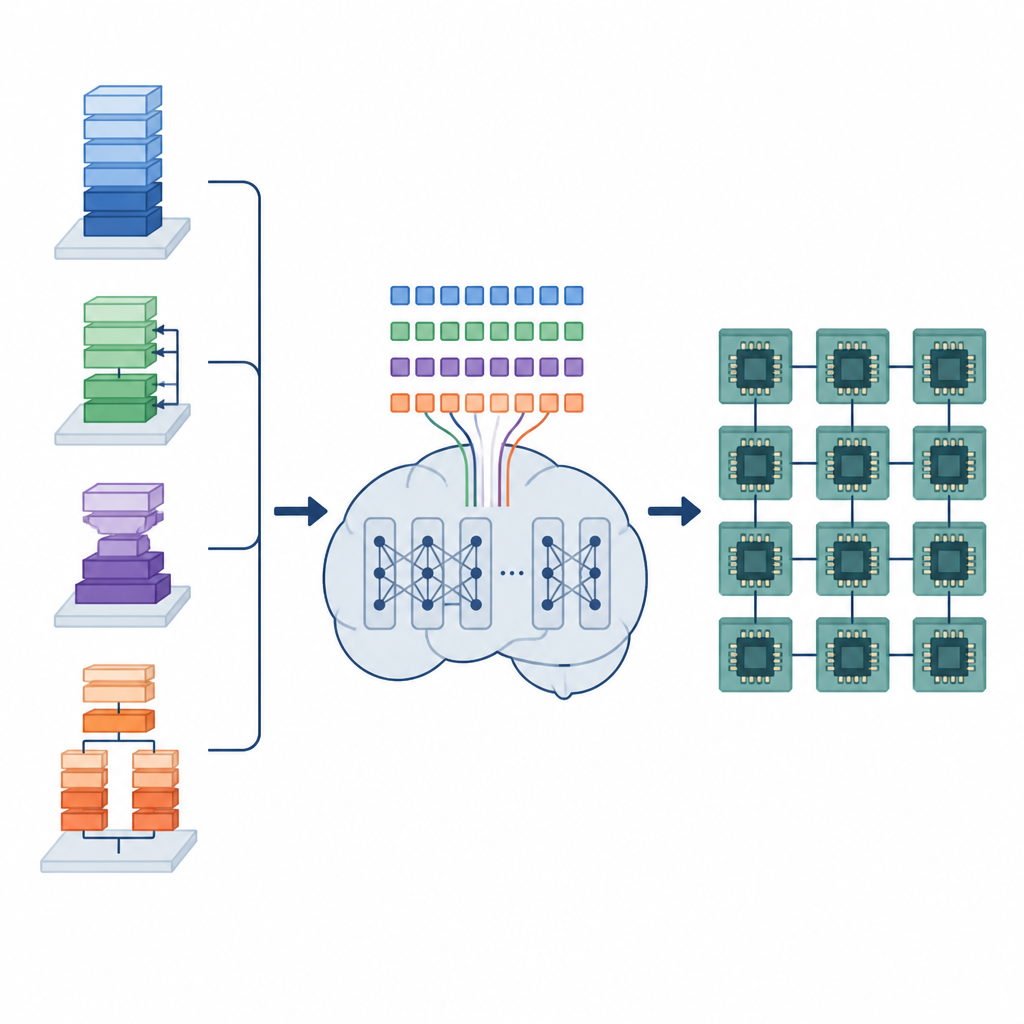
The authors propose a framework called the Tensor Language Model (TLM) that treats the problem of arranging these tensor programs as if it were writing a sentence. They design a compact “tensor language” where each token encodes information about the operation, the hardware, and a scheduling choice. A GPT-2 style model is trained on millions of these tensor sentences, learning patterns that link certain operators and hardware setups to efficient schedules. Instead of exploring many options at compile time, TLM generates one good schedule in a single pass, much like predicting the next word in a sentence.
How the new system is put together
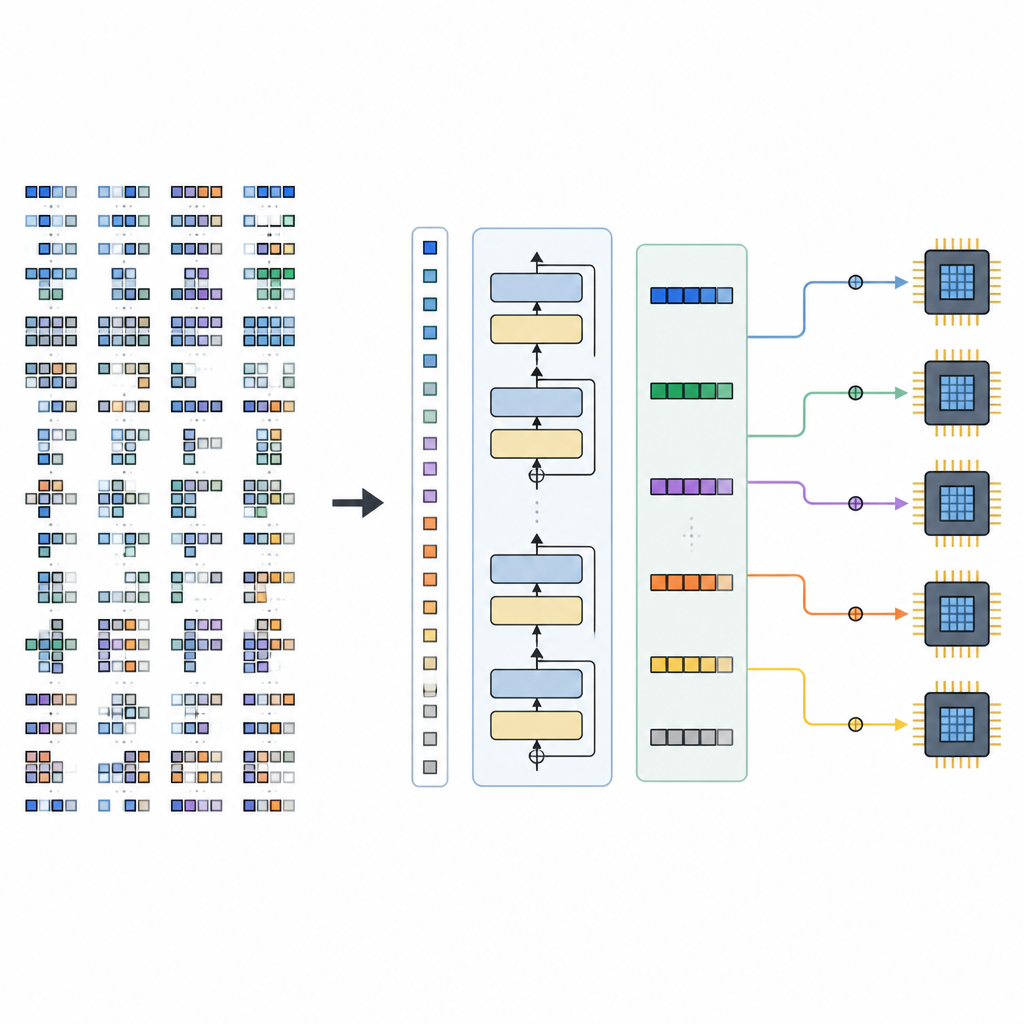
The framework has two main parts. A Space Builder examines an AI model, breaks it into smaller subgraphs, and constructs the full range of legal scheduling options for each piece, without throwing away promising choices. This space is then encoded into tensor sentences. A Generator, powered by the trained TLM, reads these sentences together with hardware hints and outputs a complete sequence of scheduling decisions. Because the tensor language is carefully designed, every generated sequence corresponds to a valid low-level program that can be turned into executable code by an existing compiler backend.
What the experiments show
The researchers trained TLM on tensor programs drawn from popular vision and language models, including ResNet-50, MobileNetV2, EfficientNet, BERT, GPT-2, and LLAMA-7B. They then compared it against leading search-based compilers like Ansor and MetaSchedule, and against a fast heuristic system called Roller. Across many test workloads, TLM produced programs whose running time matched or slightly beat the search-based tools, while compiling up to about 61 times faster. Compared to Roller, it compiled in similar or less time but ran models up to roughly 1.5 times faster. These gains carried over from small subgraphs to full end-to-end models, and TLM produced deterministic results from run to run.
Limits and future directions
The benefits of TLM depend on how well its training data covers future workloads and hardware. If a brand-new type of operator or chip appears that was not represented in the training set, the generated schedules may be less efficient until more examples are added and the model is fine-tuned. Training TLM itself is also resource-intensive, since it requires millions of example tensor programs. The authors suggest extending the approach to larger language models, broader operator sets, and additional hardware platforms, possibly with lightweight adaptation methods.
What this means for everyday AI use
In practical terms, this work shows that the costly trade-off between fast compilation and fast execution is not fixed. By learning from past optimization experience, a language-model-based compiler can generate efficient low-level code almost instantly. For companies and researchers who frequently deploy or update large AI models, such a system could greatly shorten turnaround times while keeping performance close to the best that current tools can achieve.
Citation: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Keywords: tensor compilation, deep learning compilers, language models, GPU optimisation, model scheduling