Clear Sky Science · ru
Языковая модель для тензоров позволяет генерировать планирование для эффективной компиляции тензоров
Почему важны более быстрые инструменты для ИИ
По мере роста возможностей искусственного интеллекта обучение и запуск крупных нейронных сетей требуют огромного количества вычислительного времени и энергии. За кулисами специальные программы — компиляторы — переводят модели высокого уровня в низкоуровневые инструкции для процессоров и графических ускорителей. В этой работе предложен новый способ ускорить этот перевод почти до уровня лучших вручную оптимизированных методов, используя идеи из современных языковых моделей.
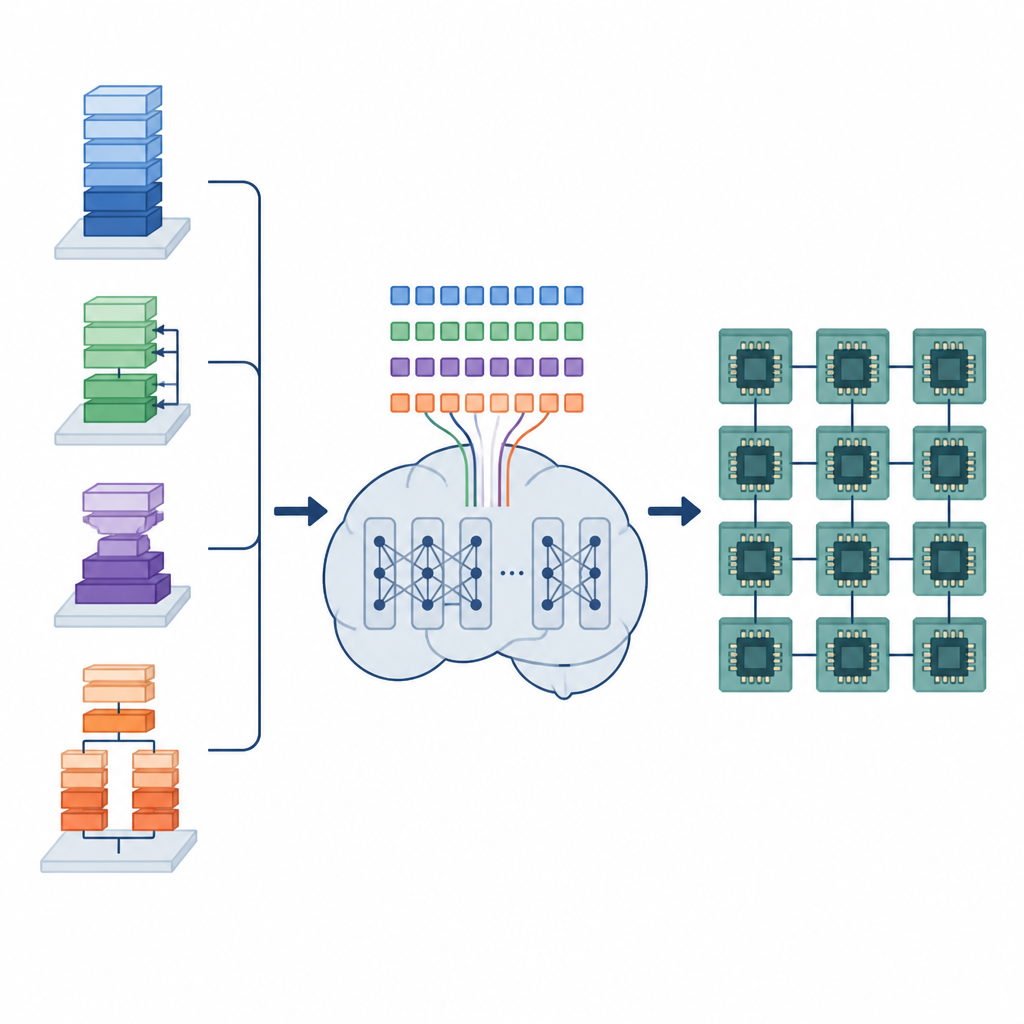
Скрытая работа компиляторов ИИ
Модели глубокого обучения опираются на множество повторяющихся операций с данными, таких как умножение больших матриц или сворачивание фильтров по изображениям. Эти операции реализуются как маленькие низкоуровневые программы, называемые тензорными программами. Чтобы эффективно работать на разном оборудовании, каждую тензорную программу нужно аккуратно организовать: циклы разбивать на плитки, распределять работу по ядрам и размещать данные в памяти так, чтобы их можно было быстро загрузить. Существующие автоматические инструменты либо просматривают огромное число вариантов — что может занимать часы или дни — либо опираются на фиксированные правила, которые компилируют быстро, но могут оставлять значительный запас производительности неиспользованным.
Преобразование планирования в языковую задачу
Авторы предлагают подход под названием Tensor Language Model (TLM), который рассматривает проблему организации тензорных программ как задачу по написанию предложения. Они разрабатывают компактный «тензорный язык», где каждый токен кодирует информацию об операции, оборудовании и выборе расписания. Модель в стиле GPT-2 обучается на миллионах таких тензорных предложений, усваивая закономерности, связывающие конкретные операторы и конфигурации аппаратуры с эффективными расписаниями. Вместо того чтобы исследовать множество вариантов во время компиляции, TLM генерирует одно хорошее расписание за один проход, подобно предсказанию следующего слова в предложении.
Как устроена новая система
Фреймворк состоит из двух основных частей. Space Builder анализирует модель ИИ, разбивает её на более мелкие подграфы и конструирует полный набор допустимых вариантов планирования для каждой части, не отбрасывая перспективные варианты. Это пространство затем кодируется в тензорные предложения. Генератор, основанный на обученном TLM, читает эти предложения вместе с подсказками об оборудовании и выдает полную последовательность решений по расписанию. Благодаря аккуратной конструкции тензорного языка каждая сгенерированная последовательность соответствует корректной низкоуровневой программе, которую существующий бекенд компилятора может превратить в исполняемый код.
Что показывают эксперименты
Исследователи обучили TLM на тензорных программах, взятых из популярных моделей для зрения и языка, включая ResNet-50, MobileNetV2, EfficientNet, BERT, GPT-2 и LLAMA-7B. Затем они сравнили модель с ведущими компиляторами, основанными на поиске, такими как Ansor и MetaSchedule, а также с быстрым эвристическим решением Roller. По многим тестовым нагрузкам TLM генерировал программы с временем выполнения, сопоставимым или немного лучшим, чем у инструментов на базе поиска, при этом компиляция происходила до примерно в 61 раз быстрее. По сравнению с Roller время компиляции было схожим или меньше, а сгенерированные модели работали до примерно в 1,5 раза быстрее. Эти преимущества сохранялись от небольших подграфов до полноценных сквозных моделей, и TLM выдавал детерминированные результаты при повторных запусках.
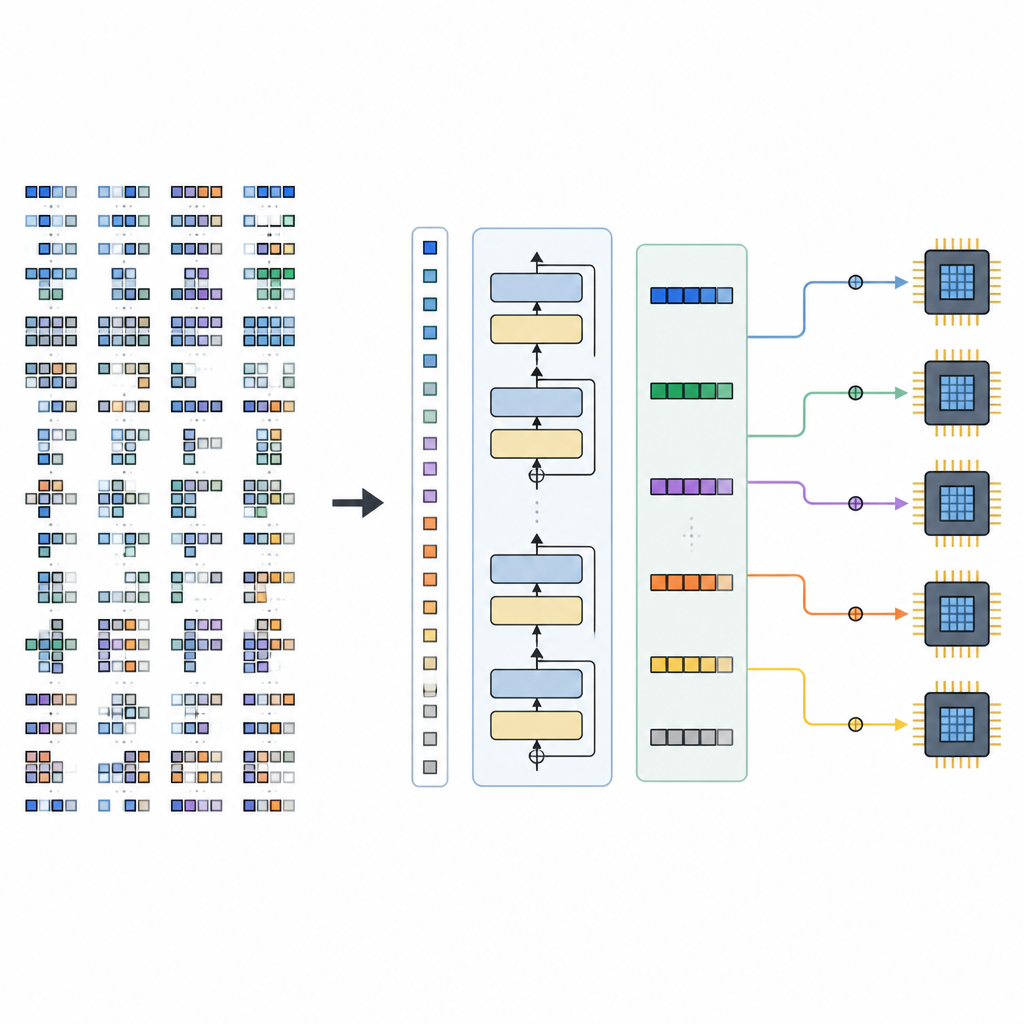
Ограничения и направления развития
Польза от TLM зависит от того, насколько хорошо обучающая выборка покрывает будущие нагрузки и аппаратные платформы. Если появится новый тип оператора или чипа, не представленный в обучающем наборе, сгенерированные расписания могут быть менее эффективными до тех пор, пока не появятся дополнительные примеры и модель не будет дообучена. Само обучение TLM также требует значительных ресурсов, поскольку нужно миллионы примеров тензорных программ. Авторы предлагают расширять подход на более крупные языковые модели, более широкий набор операторов и дополнительные аппаратные платформы, возможно с использованием лёгких методов адаптации.
Что это значит для повседневного использования ИИ
На практике эта работа показывает, что дорогой компромисс между быстрой компиляцией и быстрым выполнением не является неизбежным. Обучаясь на ранее накопленном опыте оптимизации, компилятор на основе языковой модели может почти мгновенно генерировать эффективный низкоуровневый код. Для компаний и исследователей, которые часто разворачивают или обновляют крупные ИИ-модели, такая система может существенно сократить время отклика, сохраняя производительность близкой к лучшим современным инструментам.
Цитирование: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Ключевые слова: компиляция тензоров, компиляторы для глубокого обучения, языковые модели, оптимизация GPU, планирование моделей