Clear Sky Science · pt
Modelo de linguagem de tensores possibilita escalonamento generativo para compilação eficiente de tensores
Por que ferramentas de IA mais rápidas importam
À medida que a inteligência artificial se torna mais poderosa, treinar e executar grandes redes neurais pode demandar enormes quantidades de tempo computacional e energia. Nos bastidores, programas especiais chamados compiladores traduzem modelos de alto nível em instruções de baixo nível para chips como CPUs e GPUs. Este artigo introduz uma nova maneira de tornar essa tradução muito mais rápida e quase tão eficiente quanto os melhores métodos ajustados manualmente hoje, usando ideias emprestadas de modelos de linguagem modernos.
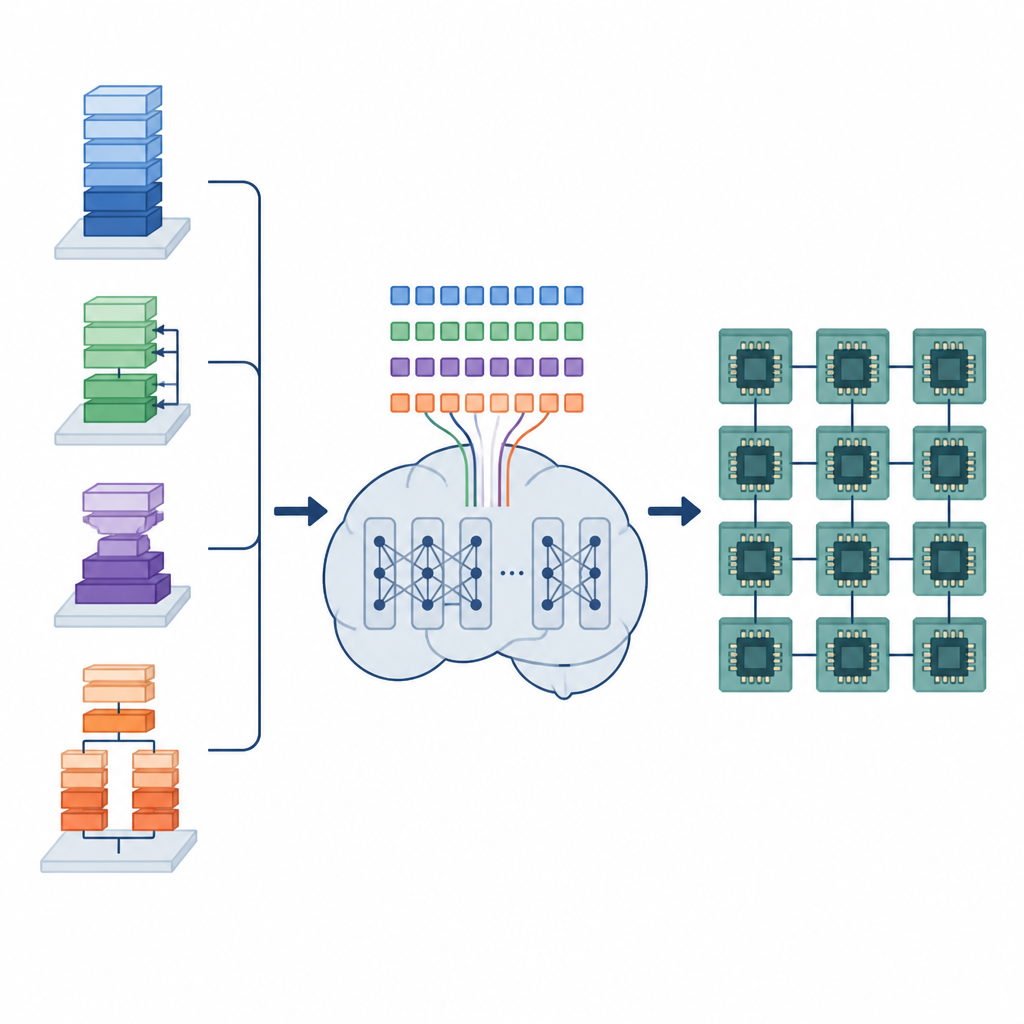
O trabalho oculto dos compiladores de IA
Modelos de deep learning dependem de muitas operações de dados repetidas, como multiplicar grandes matrizes de números ou deslizar filtros sobre imagens. Essas operações são implementadas como pequenos programas de baixo nível chamados programas de tensor. Para rodar bem em diferentes hardwares, cada programa de tensor precisa ser organizado com cuidado: laços devem ser divididos em blocos (tiling), trabalho distribuído entre núcleos e dados dispostos na memória para serem buscados rapidamente. As ferramentas automáticas existentes ou procuram entre um número vasto de possibilidades, o que pode levar horas ou dias, ou se apoiam em regras fixas que compilam rápido, mas podem deixar muito desempenho na mesa.
Transformando o escalonamento em uma tarefa de linguagem
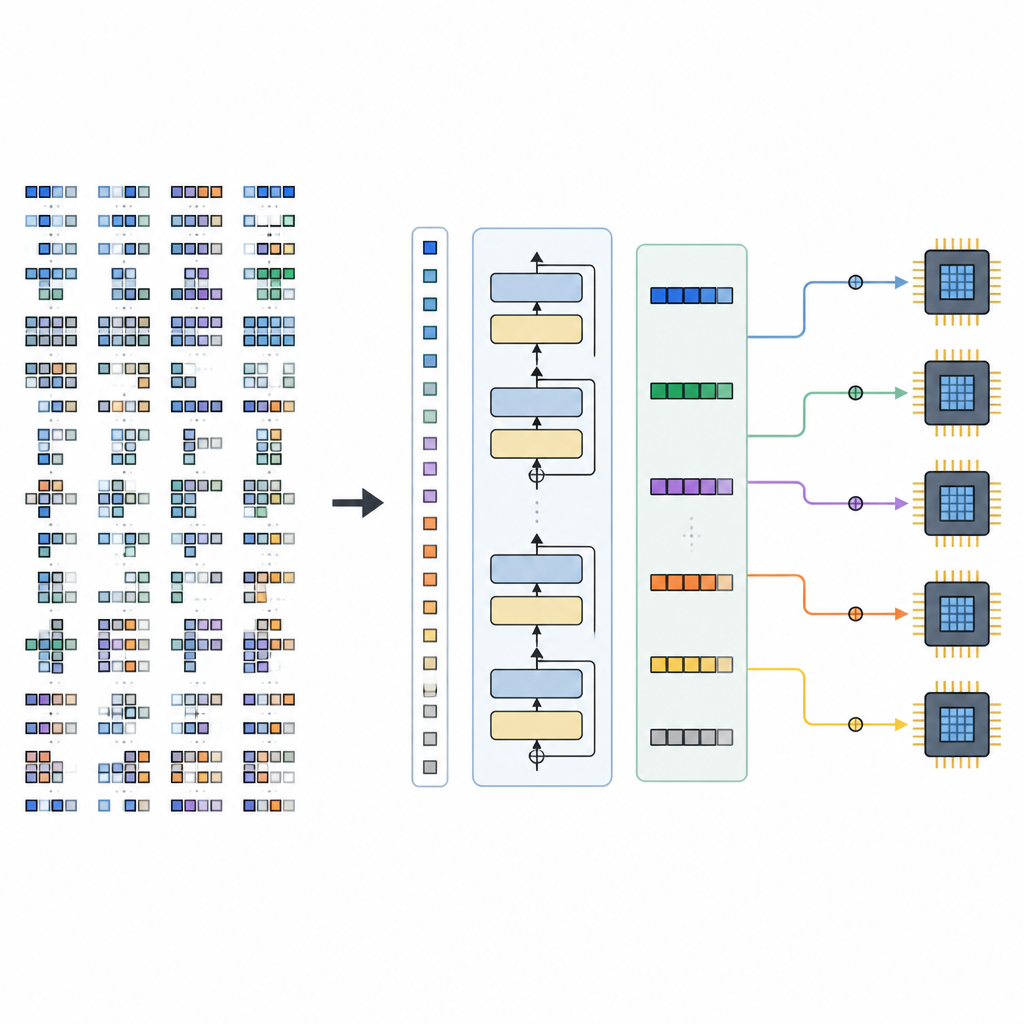
Os autores propõem uma estrutura chamada Tensor Language Model (TLM) que trata o problema de organizar esses programas de tensor como se fosse escrever uma frase. Eles projetam uma “linguagem de tensores” compacta em que cada token codifica informações sobre a operação, o hardware e uma escolha de escalonamento. Um modelo no estilo GPT-2 é treinado com milhões dessas sentenças de tensor, aprendendo padrões que ligam certos operadores e configurações de hardware a escalonamentos eficientes. Em vez de explorar muitas opções em tempo de compilação, o TLM gera um bom escalonamento em uma única passada, muito parecido com a previsão da próxima palavra em uma frase.
Como o novo sistema é montado
A estrutura tem duas partes principais. Um Space Builder examina um modelo de IA, divide-o em subgrafos menores e constrói o conjunto completo de opções legais de escalonamento para cada peça, sem eliminar escolhas promissoras. Esse espaço é então codificado em sentenças de tensor. Um Generator, alimentado pelo TLM treinado, lê essas sentenças juntamente com dicas de hardware e produz uma sequência completa de decisões de escalonamento. Como a linguagem de tensores é cuidadosamente projetada, toda sequência gerada corresponde a um programa de baixo nível válido que pode ser convertido em código executável por um backend de compilador existente.
O que os experimentos mostram
Os pesquisadores treinaram o TLM em programas de tensor extraídos de modelos populares de visão e linguagem, incluindo ResNet-50, MobileNetV2, EfficientNet, BERT, GPT-2 e LLAMA-7B. Em seguida, compararam-no com compiladores baseados em busca líderes, como Ansor e MetaSchedule, e com um sistema heurístico rápido chamado Roller. Em muitos conjuntos de teste, o TLM produziu programas cujo tempo de execução igualou ou superou ligeiramente as ferramentas baseadas em busca, enquanto compilava até cerca de 61 vezes mais rápido. Em comparação com o Roller, compilou em tempo semelhante ou menor, mas executou modelos até aproximadamente 1,5 vez mais rápido. Esses ganhos se estenderam desde pequenos subgrafos até modelos completos de ponta a ponta, e o TLM gerou resultados determinísticos de execução para execução.
Limites e direções futuras
Os benefícios do TLM dependem de quão bem seus dados de treinamento cobrem cargas de trabalho e hardwares futuros. Se surgir um tipo de operador ou chip totalmente novo que não estava representado no conjunto de treinamento, os escalonamentos gerados podem ser menos eficientes até que mais exemplos sejam adicionados e o modelo seja ajustado. Treinar o próprio TLM também é intensivo em recursos, pois requer milhões de programas de tensor de exemplo. Os autores sugerem estender a abordagem para modelos de linguagem maiores, conjuntos de operadores mais amplos e plataformas de hardware adicionais, possivelmente com métodos de adaptação leves.
O que isso significa para o uso cotidiano de IA
Em termos práticos, este trabalho mostra que a troca custosa entre compilação rápida e execução rápida não é fixa. Ao aprender com experiências de otimização passadas, um compilador baseado em modelo de linguagem pode gerar código de baixo nível eficiente quase instantaneamente. Para empresas e pesquisadores que frequentemente implantam ou atualizam grandes modelos de IA, tal sistema poderia reduzir bastante o tempo de resposta mantendo o desempenho próximo ao melhor que as ferramentas atuais conseguem alcançar.
Citação: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Palavras-chave: compilação de tensores, compiladores de deep learning, modelos de linguagem, otimização para GPU, escalonamento de modelos