Clear Sky Science · it
Un modello di linguaggio per tensori abilita la generazione di schedule per una compilazione efficiente dei tensori
Perché strumenti di IA più veloci sono importanti
Con l’aumentare della potenza dell’intelligenza artificiale, addestrare ed eseguire grandi reti neurali può richiedere enormi quantità di tempo di calcolo ed energia. Dietro le quinte, programmi specializzati chiamati compilatori trasformano modelli di alto livello in istruzioni a basso livello per chip come CPU e GPU. Questo articolo introduce un nuovo modo per rendere quella traduzione molto più rapida e quasi altrettanto efficiente quanto i metodi ottimizzati a mano odierni, usando idee prese in prestito dai moderni modelli di linguaggio.
Il lavoro nascosto dei compilatori per IA
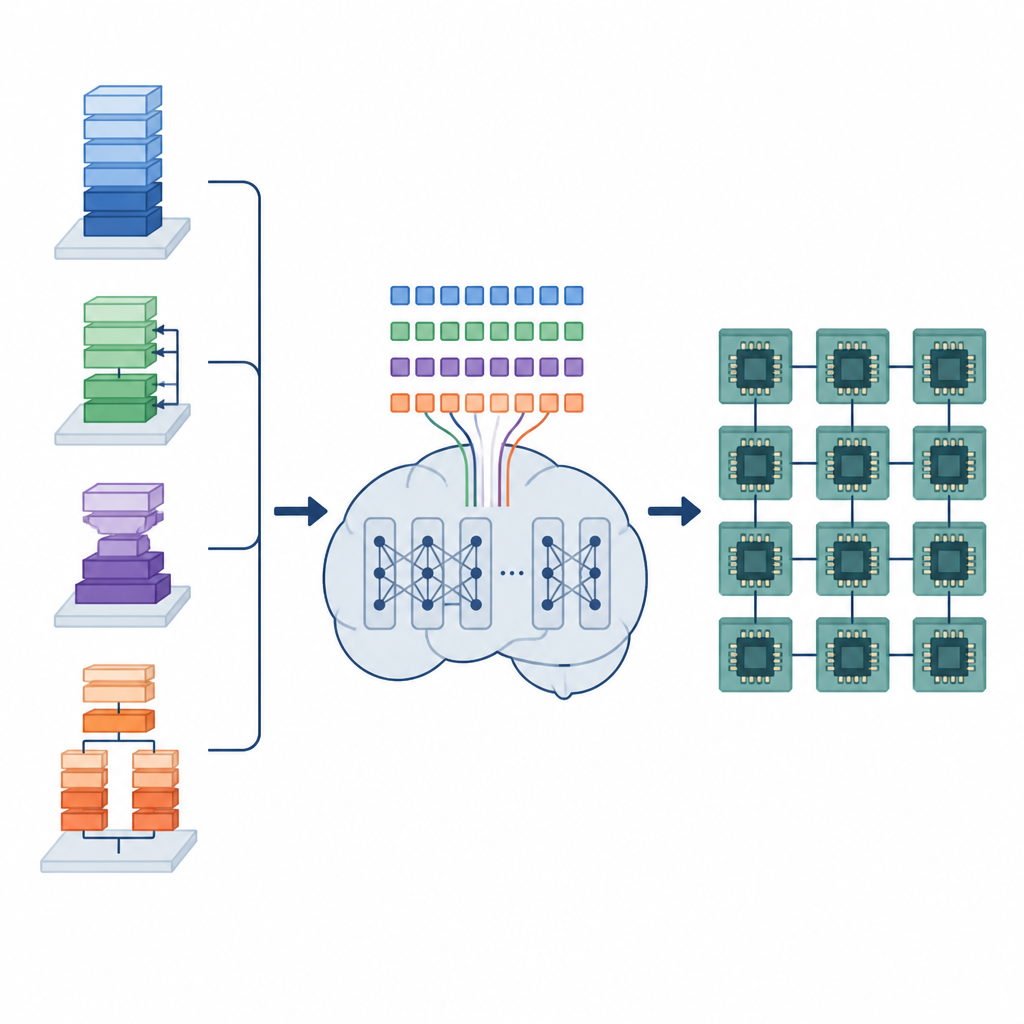
I modelli di deep learning si basano su molte operazioni di dati ripetute, come moltiplicare grandi matrici di numeri o applicare filtri scorrevoli sulle immagini. Queste operazioni sono implementate come piccoli programmi a basso livello chiamati programmi tensoriali. Per funzionare bene su hardware diversi, ogni programma tensoriale deve essere organizzato con cura: i loop vanno suddivisi in tile, il lavoro distribuito tra i core e i dati disposti in memoria in modo che possano essere recuperati rapidamente. Gli strumenti automatici esistenti o esplorano un numero vastissimo di possibilità, il che può richiedere ore o giorni, oppure si basano su regole fisse che compilano in fretta ma possono lasciare molta prestazione inutilizzata.
Trasformare la schedulazione in un compito linguistico
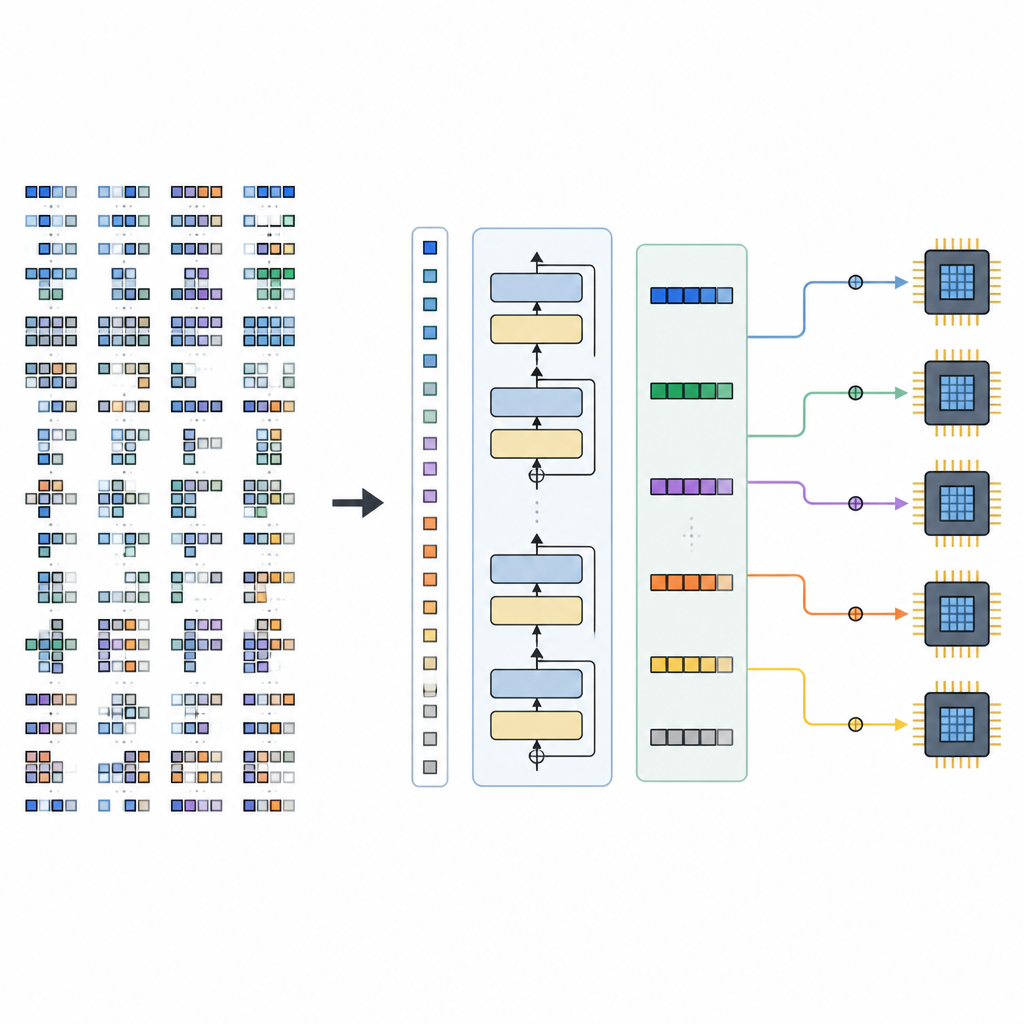
Gli autori propongono un framework chiamato Tensor Language Model (TLM) che tratta il problema di organizzare questi programmi tensoriali come se si stesse scrivendo una frase. Progettano un “linguaggio dei tensori” compatto in cui ogni token codifica informazioni sull’operazione, sull’hardware e su una scelta di schedulazione. Un modello in stile GPT-2 viene addestrato su milioni di queste frasi tensoriali, imparando schemi che collegano certi operatori e configurazioni hardware a schedule efficienti. Invece di esplorare molte opzioni a tempo di compilazione, TLM genera in un’unica passata uno schedule valido, proprio come predire la parola successiva in una frase.
Com’è composto il nuovo sistema
Il framework ha due parti principali. Un Space Builder esamina un modello di IA, lo suddivide in sotto-grafi più piccoli e costruisce l’intera gamma di opzioni di schedulazione legali per ogni pezzo, senza scartare scelte promettenti. Questo spazio viene quindi codificato in frasi tensoriali. Un Generator, alimentato dal TLM addestrato, legge queste frasi insieme a suggerimenti sull’hardware e produce una sequenza completa di decisioni di schedulazione. Poiché il linguaggio dei tensori è progettato con cura, ogni sequenza generata corrisponde a un programma a basso livello valido che può essere trasformato in codice eseguibile da un backend di compilatore esistente.
Cosa mostrano gli esperimenti
I ricercatori hanno addestrato il TLM su programmi tensoriali estratti da modelli popolari per visione e linguaggio, tra cui ResNet-50, MobileNetV2, EfficientNet, BERT, GPT-2 e LLAMA-7B. Successivamente lo hanno confrontato con compilatori basati sulla ricerca di primo piano come Ansor e MetaSchedule, e con un sistema euristico veloce chiamato Roller. Su molti carichi di lavoro di test, TLM ha prodotto programmi il cui tempo di esecuzione era pari o leggermente migliore rispetto agli strumenti basati sulla ricerca, compilando fino a circa 61 volte più velocemente. Rispetto a Roller, ha compilato in tempi simili o inferiori ma ha eseguito i modelli fino a circa 1,5 volte più velocemente. Questi vantaggi si sono estesi dai piccoli sotto-grafi ai modelli end-to-end completi, e TLM ha prodotto risultati deterministici da esecuzione a esecuzione.
Limiti e direzioni future
I benefici di TLM dipendono da quanto bene i dati di addestramento coprano i futuri carichi di lavoro e l’hardware. Se dovesse comparire un nuovo tipo di operatore o di chip non presente nel set di addestramento, gli schedule generati potrebbero essere meno efficienti finché non vengono aggiunti più esempi e il modello non viene messo a punto. Anche l’addestramento di TLM è dispendioso in risorse, poiché richiede milioni di esempi di programmi tensoriali. Gli autori suggeriscono di estendere l’approccio a modelli di linguaggio più grandi, a insiemi più ampi di operatori e ad altre piattaforme hardware, possibilmente con metodi di adattamento leggeri.
Cosa significa per l’uso quotidiano dell’IA
In termini pratici, questo lavoro mostra che il costo del compromesso tra compilazione rapida ed esecuzione veloce non è immutabile. Imparando dall’esperienza passata di ottimizzazione, un compilatore basato su modelli di linguaggio può generare codice a basso livello efficiente quasi istantaneamente. Per aziende e ricercatori che distribuiscono o aggiornano frequentemente grandi modelli di IA, un sistema del genere potrebbe ridurre significativamente i tempi di consegna mantenendo le prestazioni vicine al meglio che gli strumenti attuali possono raggiungere.
Citazione: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Parole chiave: compilazione di tensori, compilatori per deep learning, modelli di linguaggio, ottimizzazione GPU, schedulazione dei modelli