Clear Sky Science · es
Un modelo de lenguaje para tensores permite programación generativa para una compilación de tensores eficiente
Por qué importan las herramientas de IA más rápidas
A medida que la inteligencia artificial se vuelve más potente, entrenar y ejecutar grandes redes neuronales puede requerir enormes cantidades de tiempo y energía de cómputo. Tras bambalinas, programas especiales llamados compiladores convierten modelos de alto nivel en instrucciones de bajo nivel para chips como CPUs y GPUs. Este artículo presenta una nueva manera de acelerar mucho esa traducción y alcanzar una eficiencia casi equivalente a los mejores métodos afinados a mano actuales, empleando ideas tomadas de los modelos de lenguaje modernos.
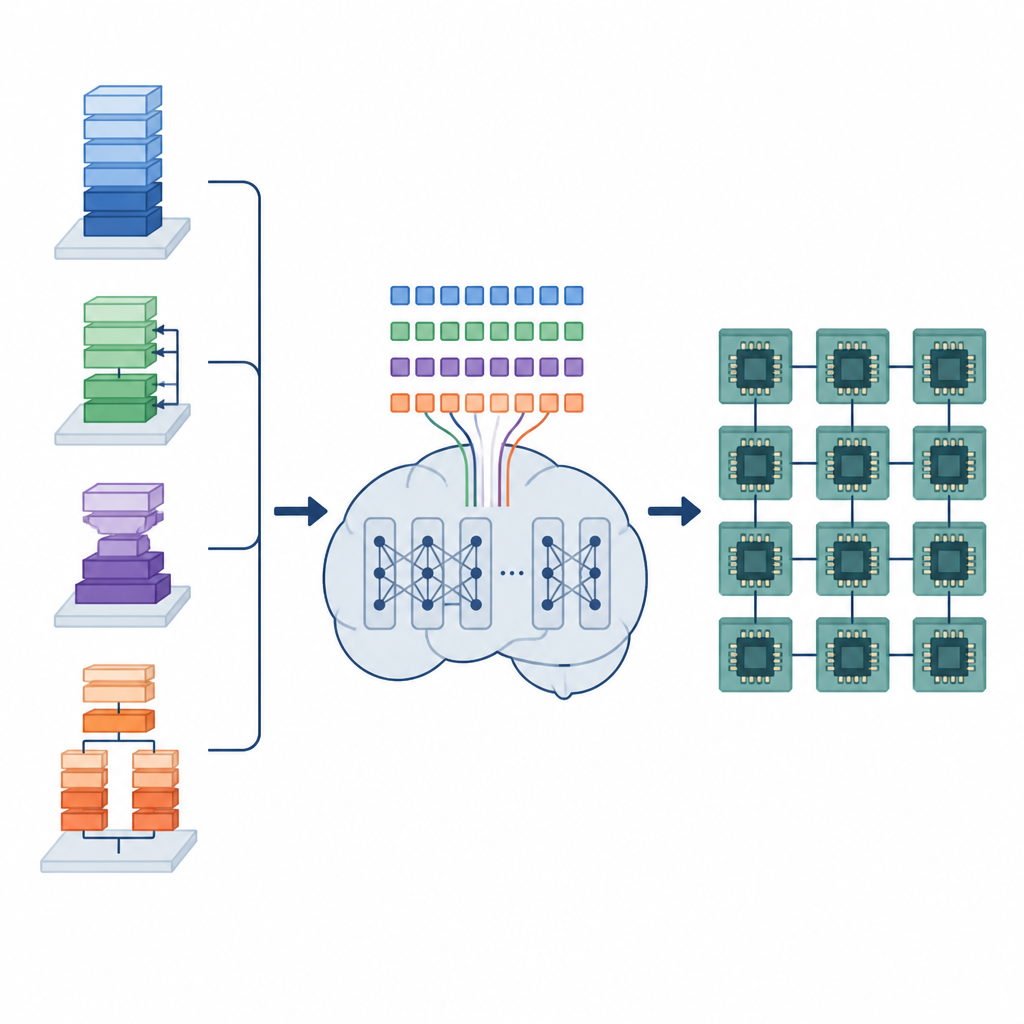
El trabajo oculto de los compiladores de IA
Los modelos de aprendizaje profundo dependen de muchas operaciones de datos repetitivas, como multiplicar grandes rejillas de números o aplicar filtros deslizantes sobre imágenes. Estas operaciones se implementan como pequeños programas de bajo nivel llamados programas tensoriales. Para ejecutarse bien en distinto hardware, cada programa tensorial debe organizarse con cuidado: los bucles se dividen en tiles, el trabajo se distribuye entre núcleos y los datos se colocan en memoria para que puedan recuperarse rápidamente. Las herramientas automáticas actuales o bien exploran un número vasto de posibilidades, lo que puede llevar horas o días, o se basan en reglas fijas que compilan rápido pero pueden dejar mucho rendimiento sobre la mesa.
Convertir la programación en una tarea lingüística
Los autores proponen un marco llamado Modelo de Lenguaje para Tensores (TLM) que trata el problema de organizar estos programas tensoriales como si se estuviera escribiendo una oración. Diseñan un “lenguaje tensorial” compacto donde cada token codifica información sobre la operación, el hardware y una elección de programación. Se entrena un modelo estilo GPT-2 con millones de estas oraciones tensoriales, aprendiendo patrones que vinculan ciertos operadores y configuraciones de hardware con programaciones eficientes. En lugar de explorar muchas opciones en tiempo de compilación, TLM genera una buena programación en una sola pasada, de forma similar a predecir la siguiente palabra en una frase.
Cómo se construye el nuevo sistema
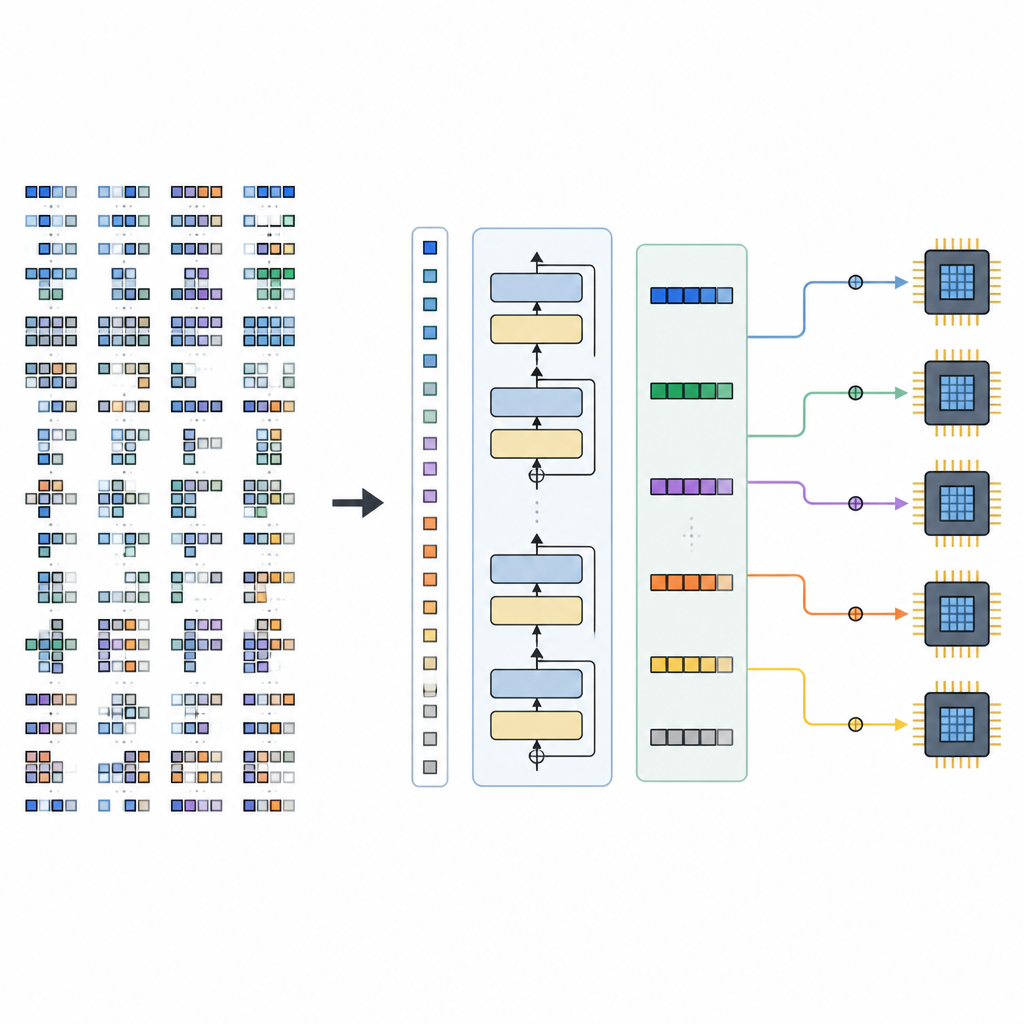
El marco tiene dos partes principales. Un Constructor de Espacios examina un modelo de IA, lo descompone en subgrafos más pequeños y construye el conjunto completo de opciones de programación legales para cada pieza, sin descartar opciones prometedoras. Este espacio se codifica luego en oraciones tensoriales. Un Generador, alimentado por el TLM entrenado, lee estas oraciones junto con pistas de hardware y produce una secuencia completa de decisiones de programación. Dado que el lenguaje tensorial está cuidadosamente diseñado, cada secuencia generada corresponde a un programa de bajo nivel válido que puede convertirse en código ejecutable mediante un backend de compilador existente.
Qué muestran los experimentos
Los investigadores entrenaron TLM con programas tensoriales extraídos de modelos populares de visión y lenguaje, incluidos ResNet-50, MobileNetV2, EfficientNet, BERT, GPT-2 y LLAMA-7B. Luego lo compararon con compiladores basados en búsqueda líderes como Ansor y MetaSchedule, y con un sistema heurístico rápido llamado Roller. En muchos casos de prueba, TLM produjo programas cuyo tiempo de ejecución igualó o superó ligeramente a las herramientas basadas en búsqueda, mientras que compilaba hasta aproximadamente 61 veces más rápido. En comparación con Roller, compiló en un tiempo similar o menor, pero ejecutó modelos hasta aproximadamente 1,5 veces más rápido. Estas mejoras se mantuvieron desde pequeños subgrafos hasta modelos completos de extremo a extremo, y TLM produjo resultados deterministas de una ejecución a otra.
Límites y direcciones futuras
Los beneficios de TLM dependen de cuánto cubran sus datos de entrenamiento las cargas de trabajo y el hardware futuros. Si aparece un tipo de operador o un chip totalmente nuevo que no estuviera representado en el conjunto de entrenamiento, las programaciones generadas podrían ser menos eficientes hasta que se añadan más ejemplos y se realice un fine-tuning del modelo. Entrenar el propio TLM también exige muchos recursos, ya que requiere millones de programas tensoriales de ejemplo. Los autores sugieren ampliar el enfoque a modelos de lenguaje mayores, conjuntos de operadores más amplios y plataformas de hardware adicionales, posiblemente con métodos ligeros de adaptación.
Qué significa esto para el uso cotidiano de la IA
En términos prácticos, este trabajo demuestra que la costosa disyuntiva entre compilación rápida y ejecución rápida no es inmutable. Aprendiendo de la experiencia pasada en optimización, un compilador basado en modelos de lenguaje puede generar código de bajo nivel eficiente casi al instante. Para empresas e investigadores que despliegan o actualizan con frecuencia modelos de IA grandes, un sistema así podría acortar enormemente los tiempos de respuesta manteniendo el rendimiento cercano al mejor que las herramientas actuales pueden alcanzar.
Cita: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Palabras clave: compilación de tensores, compiladores de aprendizaje profundo, modelos de lenguaje, optimización en GPU, programación de modelos