Clear Sky Science · ar
نموذج لغوي للتنسورات يمكّن التوليد الجدولي لتجميع التنسورات بكفاءة
لماذا تهم أدوات الذكاء الاصطناعي الأسرع
مع تزايد قدرات الذكاء الاصطناعي، قد تتطلب عملية تدريب وتشغيل الشبكات العصبية الكبيرة كميات هائلة من الوقت والحوسبة والطاقة. خلف الكواليس، توجد برامج متخصصة تُسمى المجمّعات تحول نماذج الذكاء الاصطناعي عالية المستوى إلى تعليمات منخفضة المستوى لشِرائح مثل وحدات المعالجة المركزية ووحدات معالجة الرسومات. تقدّم هذه الورقة طريقة جديدة لتسريع تلك الترجمة إلى حد كبير وبكفاءة تقارب أفضل الطرق المحسّنة يدويًا اليوم، باستخدام أفكار مستعارة من نماذج اللغة الحديثة.
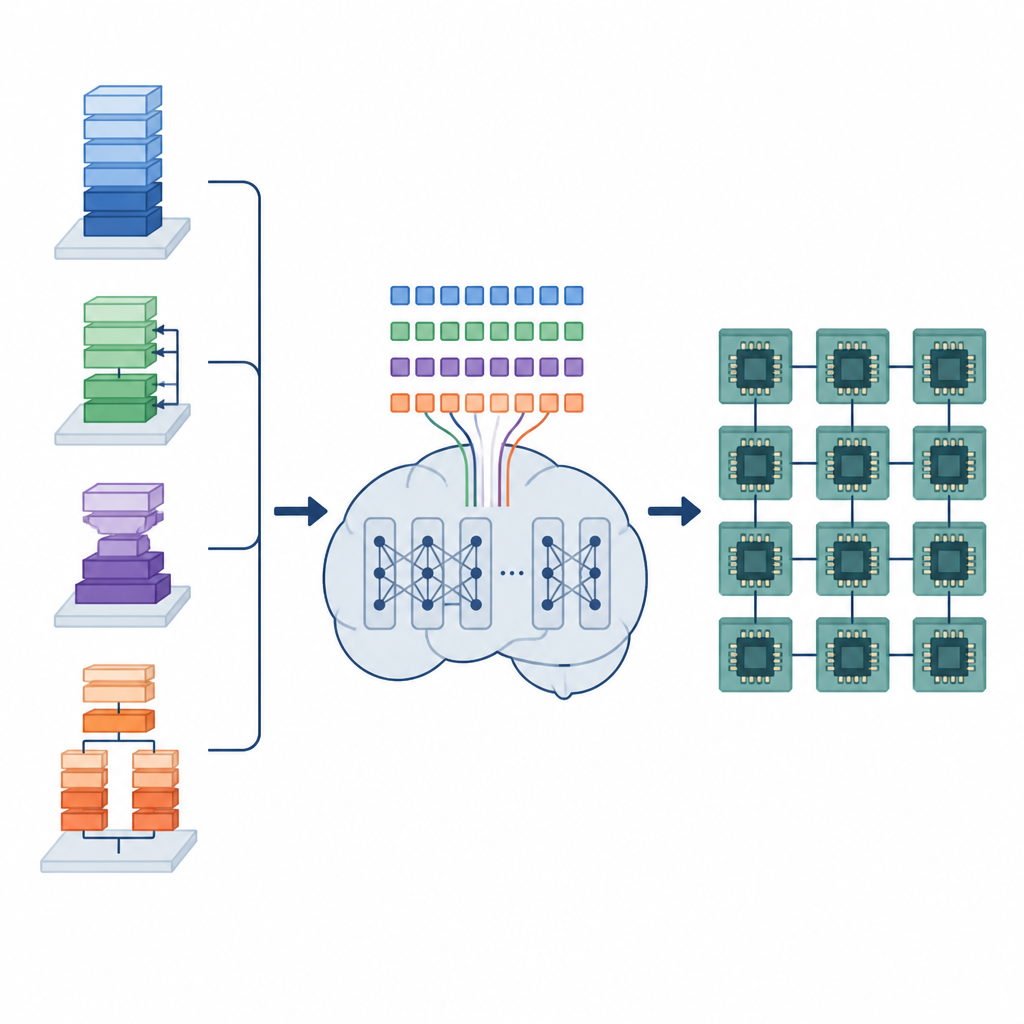
العمل الخفي لمجمّعات الذكاء الاصطناعي
تعتمد نماذج التعلم العميق على العديد من العمليات المتكررة للبيانات، مثل ضرب مصفوفات كبيرة أو تمرير مرشحات فوق الصور. تُنفّذ هذه العمليات كبرامج منخفضة المستوى صغيرة تُسمى برامج التنسور. لكي تعمل جيدًا على أجهزة مختلفة، يجب ترتيب كل برنامج تنسور بعناية: تقسيم الحلقات إلى بلاطات، توزيع العمل عبر النوى، وتنظيم تخزين البيانات في الذاكرة بحيث تُسترجع بسرعة. الأدوات الآلية الحالية إمّا تبحث عبر عدد هائل من الاحتمالات، وهو ما قد يستغرق ساعات أو أيام، أو تعتمد قواعد ثابتة تُجمع بسرعة ولكن قد تترك الكثير من الأداء غير مستغل.
تحويل الجدولة إلى مهمة لغوية
يقترح المؤلفون إطار عمل يُدعى نموذج لغة التنسور (TLM) يعامل مشكلة ترتيب برامج التنسور كما لو كانت صياغة جملة. يصممون "لغة تنسور" مضغوطة حيث يُشفّر كل رمز معلومات عن العملية، والأجهزة، وخيار الجدولة. يتم تدريب نموذج على طراز GPT-2 على ملايين من هذه الجمل التنسورية، ليكتسب أنماطًا تربط بين مُشغلات معينة وتركيبات الأجهزة والجداول الفعّالة. بدلًا من استكشاف العديد من الخيارات أثناء وقت التجميع، يولّد TLM جدولًا جيدًا في مرور واحد، تمامًا مثل التنبؤ بالكلمة التالية في جملة.
كيف تُبنى المنظومة الجديدة
يتكون الإطار من جزأين رئيسيين. يفحص مُنشئ الفضاء نموذج الذكاء الاصطناعي، ويقسّمه إلى رسومات فرعية أصغر، وينشئ نطاق الخيارات القانونية للجدولة لكل جزء دون استبعاد الخيارات الواعدة. ثم تُشفّر هذه المساحة إلى جمل تنسورية. يقرأ المولّد، المدفوع بنموذج TLM المدرب، هذه الجمل مع تلميحات الأجهزة ويخرج تسلسلًا كاملاً من قرارات الجدولة. وبما أن لغة التنسور مُصمَّمة بعناية، فإن كل تسلسل مولَّد يقابل برنامجًا منخفض المستوى صالحًا يمكن تحويله إلى شيفرة قابلة للتنفيذ بواسطة خلفية مجمّع موجودة.
ماذا تُظهر التجارب
درّب الباحثون TLM على برامج تنسور مأخوذة من نماذج رؤية ولغة شائعة، بما في ذلك ResNet-50 وMobileNetV2 وEfficientNet وBERT وGPT-2 وLLAMA-7B. قارنوه بعد ذلك بأفضل المجمّعات المعتمدة على البحث مثل Ansor وMetaSchedule، وبنظام إرشادي سريع يُسمى Roller. عبر عبء عمل متنوع، أنتج TLM برامج زمن تشغيلها مطابق أو أفضل قليلًا من الأدوات المعتمدة على البحث، مع وقت تجميع أسرع بما يصل إلى حوالي 61 مرة. مقارنةً بـ Roller، كان زمن التجميع مشابهًا أو أقل، لكن البرامج التي أنتجها عملت أسرع بنحو 1.5 مرة في بعض الحالات. امتدت هذه المكاسب من الرسومات الفرعية الصغيرة إلى النماذج الكاملة من طرف إلى طرف، وكان TLM يعطي نتائج محددة قابلة للتكرار عند التشغيل المتكرر.
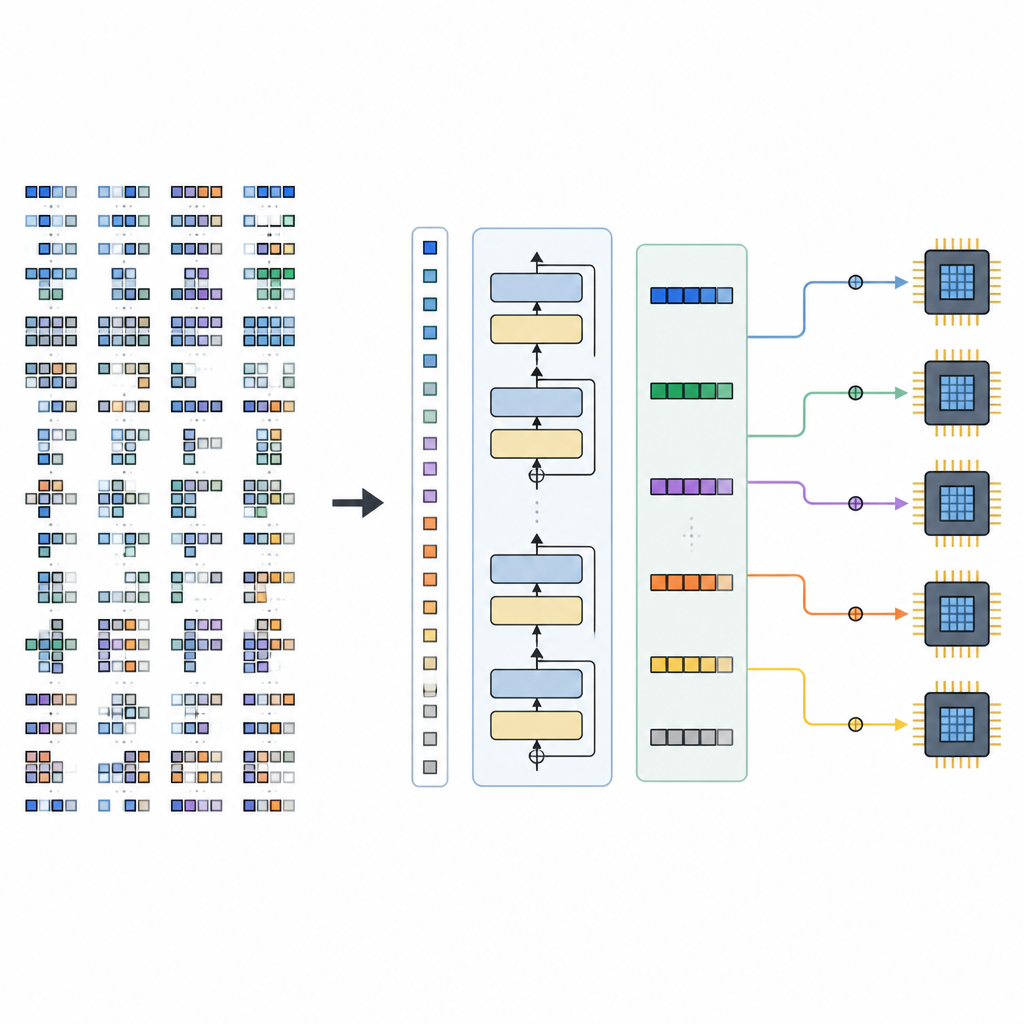
القيود والاتجاهات المستقبلية
تعتمد فوائد TLM على مدى تغطية بيانات التدريب لأحمال العمل والأجهزة المستقبلية. إذا ظهر نوع جديد تمامًا من المُشغلات أو الشريحة لم يكن موجودًا في مجموعة التدريب، فقد تكون الجداول المولَّدة أقل كفاءة حتى تُضاف أمثلة أكثر ويجري ضبط النموذج. كما أن تدريب TLM نفسه يتطلب موارد كبيرة، لأنه يحتاج ملايين أمثلة برامج التنسور. يقترح المؤلفون توسيع المنهج إلى نماذج لغوية أكبر ومجموعات مشغلات أوسع ومنصات أجهزة إضافية، وربما باستخدام طرق تكيّف خفيفة الوزن.
ماذا يعني هذا للاستخدام اليومي للذكاء الاصطناعي
عمليًا، تُظهر هذه العملة أن المقايضة المكلفة بين التجميع السريع والتنفيذ السريع ليست ثابتة. من خلال التعلم من خبرات التحسين السابقة، يمكن لمجمّع يعتمد على نموذج لغوي توليد شيفرة منخفضة المستوى فعّالة تقريبًا فورًا. بالنسبة للشركات والباحثين الذين ينشرون أو يحدثون نماذج ذكاء اصطناعي كبيرة بشكل متكرر، قد يُقصر مثل هذا النظام أوقات الاستجابة بشكل كبير مع الحفاظ على أداء قريب من أفضل ما تستطيع الأدوات الحالية تحقيقه.
الاستشهاد: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
الكلمات المفتاحية: تجميع التنسورات, مجمّعات التعلم العميق, نماذج لغوية, تحسين GPU, جدولة النماذج