Clear Sky Science · pl
Model językowy tensorów umożliwia generatywne planowanie w celu wydajnej kompilacji tensorów
Dlaczego szybsze narzędzia AI mają znaczenie
W miarę jak sztuczna inteligencja staje się coraz potężniejsza, trenowanie i uruchamianie dużych sieci neuronowych może wymagać ogromnych nakładów czasu obliczeniowego i energii. W tle specjalne programy zwane kompilatorami przekształcają modele wysokiego poziomu w niskopoziomowe instrukcje dla układów takich jak CPU i GPU. W artykule przedstawiono nowe podejście, które pozwala wykonać tę translację znacznie szybciej i niemal tak wydajnie jak najlepsze ręcznie dopracowane metody, wykorzystując pomysły zapożyczone ze współczesnych modeli językowych.
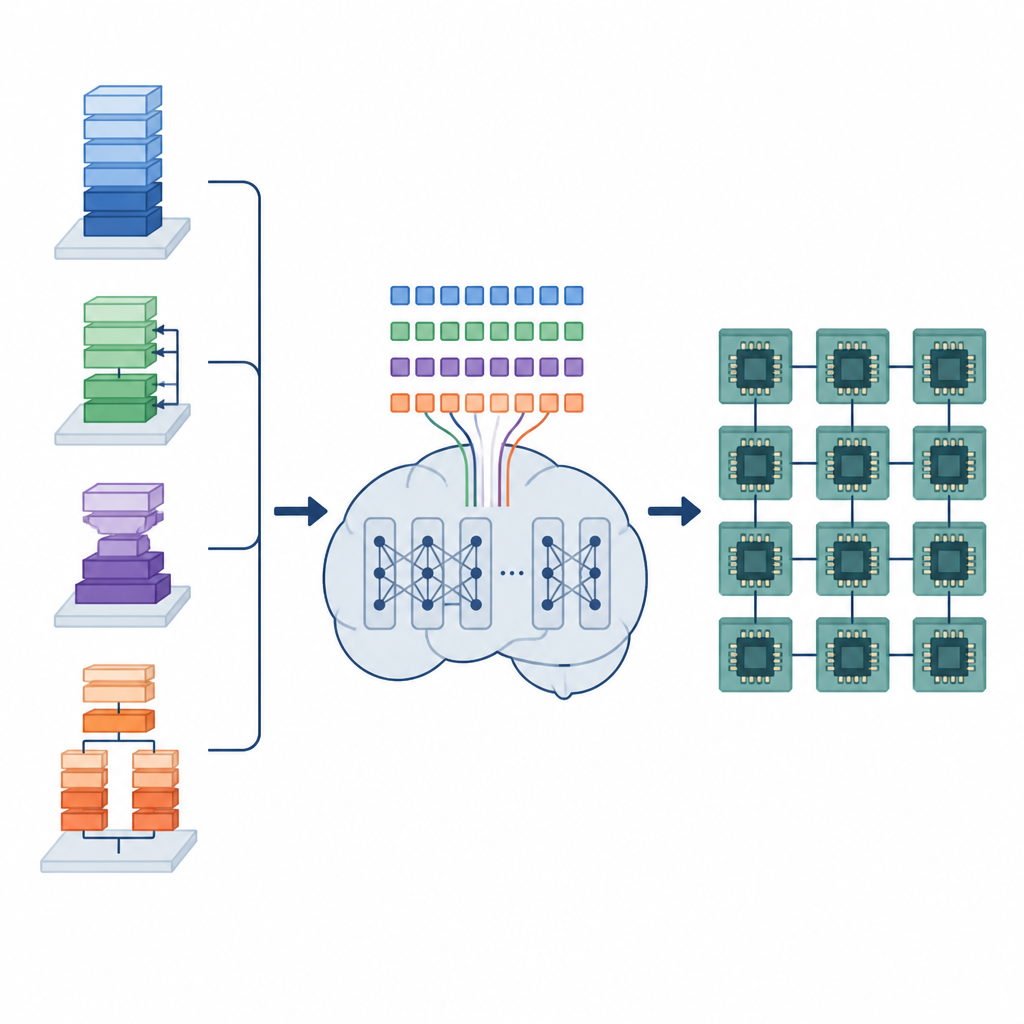
Ukryta praca kompilatorów AI
Modele głębokiego uczenia opierają się na wielu powtarzających się operacjach na danych, takich jak mnożenie dużych macierzy czy nakładanie filtrów na obrazy. Operacje te są realizowane jako niewielkie niskopoziomowe programy zwane programami tensorowymi. Aby działały dobrze na różnych platformach sprzętowych, każdy program tensorowy musi być starannie zorganizowany: pętle należy podzielić na kafelki, zadania rozdzielić między rdzenie, a dane ułożyć w pamięci tak, by można je było szybko pobierać. Istniejące narzędzia automatyczne albo przeszukują ogromny zbiór możliwości, co może zająć godziny lub dni, albo opierają się na stałych regułach, które kompilują szybko, ale mogą pozostawiać znaczny potencjał wydajności niewykorzystany.
Przekształcenie planowania w zadanie językowe
Autorzy proponują ramy nazwane Tensor Language Model (TLM), które traktują problem organizacji programów tensorowych tak, jakby chodziło o pisanie zdania. Projektują kompaktowy „język tensorowy”, w którym każdy token koduje informacje o operacji, sprzęcie i wyborze harmonogramu. Model w stylu GPT-2 jest trenowany na milionach takich tensorowych zdań, ucząc się wzorców łączących określone operatory i konfiguracje sprzętowe z efektywnymi harmonogramami. Zamiast eksplorować wiele opcji w czasie kompilacji, TLM generuje jeden dobry harmonogram w jednym przebiegu, podobnie jak przewiduje się kolejne słowo w zdaniu.
Jak zbudowano nowy system
Ramy składają się z dwóch głównych części. Space Builder analizuje model AI, rozbija go na mniejsze podgrafy i konstruuje pełen zakres prawidłowych opcji planowania dla każdego fragmentu, nie odrzucając obiecujących wyborów. Ta przestrzeń jest następnie kodowana w tensorowe zdania. Generator, napędzany wytrenowanym TLM, czyta te zdania wraz ze wskazówkami sprzętowymi i generuje kompletną sekwencję decyzji planistycznych. Dzięki starannemu zaprojektowaniu języka tensorowego każda wygenerowana sekwencja odpowiada ważnemu programowi niskiego poziomu, który istniejący backend kompilatora może przekształcić w kod wykonywalny.
Co pokazują eksperymenty
Naukowcy trenowali TLM na programach tensorowych pochodzących z popularnych modeli wizji i języka, w tym ResNet-50, MobileNetV2, EfficientNet, BERT, GPT-2 i LLAMA-7B. Następnie porównali go z wiodącymi kompilatorami opartymi na przeszukiwaniu, takimi jak Ansor i MetaSchedule, oraz z szybkim systemem heurystycznym o nazwie Roller. W wielu testowych obciążeniach TLM generował programy, których czas wykonania dorównywał lub nieznacznie przewyższał narzędzia bazujące na przeszukiwaniu, jednocześnie kompilując do około 61 razy szybciej. W porównaniu z Rollerem kompilował w podobnym lub krótszym czasie, ale uruchamiał modele do ~1,5 raza szybciej. Te zyski utrzymywały się od małych podgrafów po pełne modele end-to-end, a TLM dawał deterministyczne wyniki między kolejnymi uruchomieniami.
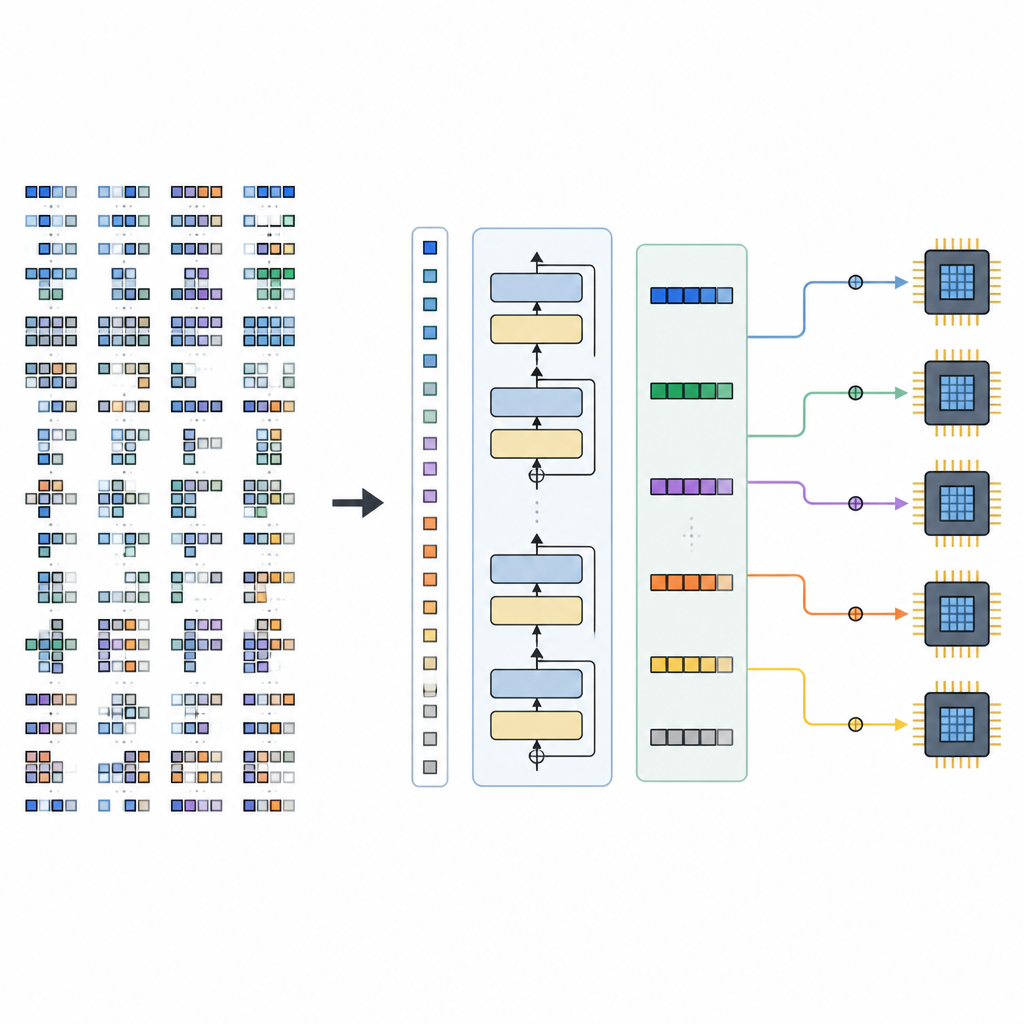
Ograniczenia i kierunki rozwoju
Korzystanie z TLM zależy od tego, jak dobrze dane treningowe pokrywają przyszłe obciążenia i platformy sprzętowe. Jeśli pojawi się zupełnie nowy typ operatora lub układu, który nie był reprezentowany w zbiorze treningowym, generowane harmonogramy mogą być mniej wydajne, dopóki nie dodadzą się nowe przykłady i model nie zostanie dopasowany. Sam trening TLM jest również zasobożerny, ponieważ wymaga milionów przykładowych programów tensorowych. Autorzy sugerują rozszerzenie podejścia na większe modele językowe, szersze zbiory operatorów i dodatkowe platformy sprzętowe, być może z lekkimi metodami adaptacji.
Co to oznacza dla codziennego użycia AI
W praktyce praca ta pokazuje, że kosztowny kompromis między szybką kompilacją a szybkim wykonaniem nie jest niezmienny. Ucząc się na podstawie wcześniejszych doświadczeń optymalizacyjnych, kompilator oparty na modelu językowym może niemal natychmiast generować wydajny kod niskiego poziomu. Dla firm i badaczy, którzy często wdrażają lub aktualizują duże modele AI, taki system może znacznie skrócić czas realizacji przy utrzymaniu wydajności zbliżonej do najlepszych dostępnych narzędzi.
Cytowanie: Mehmood, S., Arooj, A., Al-Shamayleh, A.S. et al. Tensor language model enables generative scheduling for efficient tensor compilation. Sci Rep 16, 15379 (2026). https://doi.org/10.1038/s41598-026-41392-8
Słowa kluczowe: kompilacja tensorów, kompilatory do głębokiego uczenia, modele językowe, optymalizacja GPU, harmonogramowanie modeli