Clear Sky Science · zh
基于从切片到病理的补丁多实例学习架构基准测试:使用基于注意力的弱监督进行前列腺癌检测与分级
这对患者和医生为何重要
前列腺癌是男性中最常见的癌症之一,从显微镜切片判断其严重程度直接影响治疗方案。如今,这类分级工作既耗时,又可能在病理学家之间存在差异,随着人口老龄化也难以扩展。本研究展示了现代人工智能如何在远少于以往人工标注的情况下,从数字切片中学习评估癌症严重度,同时仍能为医生所理解。这使其成为在真实医院环境中支持日常诊断的现实候选,而不仅限于研究实验室。
从巨幅切片到微小图像块
现代扫描仪会将一薄片前列腺组织转换为巨大的数字图像,常常达到2万乘2万像素。图像的大部分是背景,即便是有用的组织区域也远大于典型计算模型一次能处理的规模。研究团队通过将整张切片裁成许多小方形“补丁”来解决此问题,就像把一张海报拆成拼图。他们仔细检测真实组织区域,过滤掉空白区和伪影,并生成坐标映射以告知计算机从何取样。他们测试了四种补丁策略,混合不同大小并有无重叠,最终从大型公开前列腺癌数据集PANDA的1万多张切片中生成了超过3100万张补丁。
在无需像素级标注的情况下教计算机识别癌症
在许多先前系统中,专家必须为每个癌灶绘制精确轮廓,这一步既费时又阻碍实际部署。此处研究团队采用了一种称为弱监督的方法:计算机只看到切片级别的标签,例如从0(良性)到5(最具侵袭性)的最终癌症分级,而无需内部的详细标注。每张切片成为一个由补丁组成的“包”,特殊模型学习哪些补丁对预测整体分级最为重要。这类被称为多实例学习的方法,使计算机能够在大幅减少病理学家训练负担的同时,发现区分轻度与侵袭性疾病的腺体与细胞模式。
多种AI模块的直接比较
作者并未只提出一种新模型,而是构建了一个严谨的基准。他们将六种领先的多实例学习设计与三种不同的特征提取器或“编码器”组合,将每个补丁转化为丰富的数值指纹。其中一款编码器是对日常照片训练的经典视觉模型,另两款是专门在数十万张病理切片上训练的大型“基础”模型。他们在四种补丁设置和五折交叉验证下运行了所有组合,产生了360次训练运行和72个核心配置。性能以准确率、若干种F分数以及二次加权卡帕(quadratic weighted kappa)来衡量——该统计量对接近专家判断的分级予以奖励,即使不完全一致也能反映出接近程度。
找到最佳组合:小而重叠的补丁与病理学基础模型
明显的优胜组合是在使用相对较小的组织补丁(256×256像素)且重叠50%时出现,编码器为UNI2基础模型,聚合方法为一种低秩注意力方法ILRA‑MIL。该组合达到约79%的准确率和略高于0.90的非常高的二次加权卡帕,接近原始PANDA挑战中人类专家之间的达成水平。较小且重叠的补丁既提供了细胞级的精细信息,又保留了足够的上下文,而专门为病理训练的编码器在准确率上明显优于通用的照片训练网络,领先约15–20个百分点。重要的是,作者展示了这些改进可以用可获得的云资源实现,采用公共平台上的分布式计算而非昂贵的专用集群。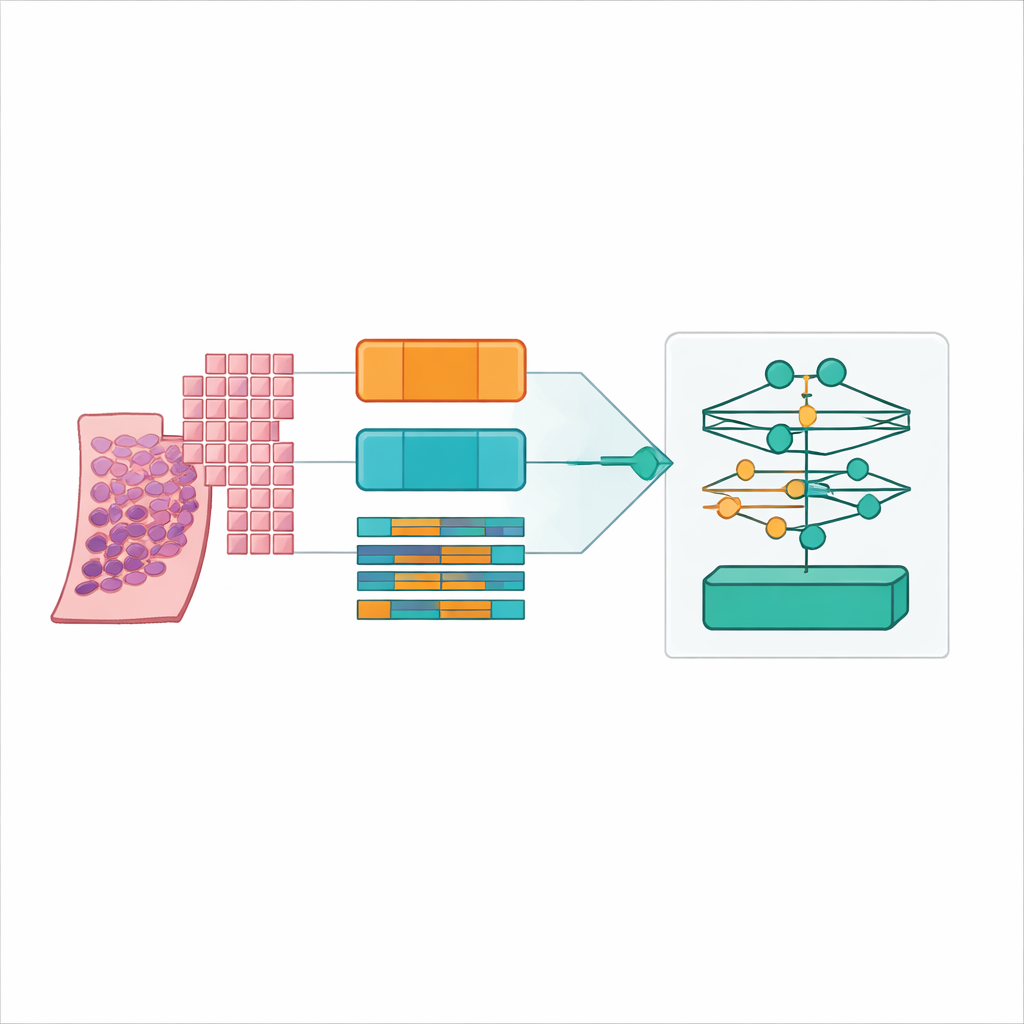
让AI的决策对病理学家可见
对于可能影响治疗的任何工具,仅仅准确还不够;医生需要理解其做出特定判断的原因。研究团队加入了注意力图和Grad‑CAM热图,高亮显示驱动预测的切片区域。这些可视化解释可以覆盖在组织图像上,使病理学家能够确认模型确实关注的是癌性腺体或侵袭性模式,而非噪音或良性结构。这种对可解释性的关注,结合基于网络的界面以及从原始切片到预测的完整流程描述,旨在降低临床实验室采用和独立验证的门槛。
对未来前列腺癌护理的意义
简而言之,该研究表明:精心设计的AI系统能够在数字切片上对前列腺癌进行接近专科病理学家水平的分级,而无需对每张训练切片进行详尽的手工标注。最有效的方案是使用许多小且重叠的图像块,配合大型病理训练的编码器,输入基于注意力的模型,这类模型还能指示其依赖的组织区域。尽管该工作仍依赖单一大型数据集并需要更广泛的医院间测试,但它为更快速、更一致且更广泛可用的前列腺癌诊断提供了现实路径,尤其是在缺乏专科病理学家的地区。
引用: Butt, N.A., Sarwat, D., Noya, I.D. et al. Benchmarking multiple instance learning architectures from patches to pathology for prostate cancer detection and grading using attention-based weak supervision. Sci Rep 16, 11535 (2026). https://doi.org/10.1038/s41598-026-39196-x
关键词: 前列腺癌, 数字病理学, 弱监督学习, 多实例学习, 计算病理学