Clear Sky Science · pt
Avaliação comparativa de arquiteturas de aprendizagem por instâncias múltiplas de fragmentos a patologia para detecção e classificação do câncer de próstata usando supervisão fraca baseada em atenção
Por que isso importa para pacientes e médicos
O câncer de próstata é um dos tumores mais comuns em homens, e determinar sua gravidade a partir de lâminas de microscópio influencia diretamente as opções de tratamento. Atualmente, esse trabalho de gradação é demorado, pode variar entre patologistas e é difícil de escalar com o envelhecimento da população. Este estudo demonstra como técnicas modernas de inteligência artificial podem aprender a avaliar a severidade do câncer a partir de lâminas digitais usando muito menos marcações humanas do que antes, mantendo-se compreensíveis para os médicos. Isso torna a abordagem um candidato realista para apoiar diagnósticos do dia a dia em hospitais reais, e não apenas em laboratórios de pesquisa.
De lâminas gigantes a pequenos blocos de imagem
Escâneres modernos transformam uma fina fatia de tecido prostático em uma imagem digital gigantesca, frequentemente de 20.000 por 20.000 pixels. A maior parte dessa imagem é fundo, e mesmo o tecido útil é grande demais para ser processado de uma só vez por um modelo computacional típico. Os pesquisadores resolveram isso cortando cada lâmina inteira em muitos pequenos quadrados—"patches"—de tecido, como transformar um pôster em um quebra‑cabeça. Eles detectaram cuidadosamente apenas as regiões de tecido verdadeiro, filtraram áreas vazias e artefatos, e geraram mapas de coordenadas que indicam ao computador exatamente onde amostrar. Testaram quatro estratégias de patch, combinando quadrados grandes e pequenos, com e sem sobreposição, eventualmente produzindo mais de 31 milhões de patches a partir de mais de 10.600 lâminas em um grande conjunto público de câncer de próstata chamado PANDA. 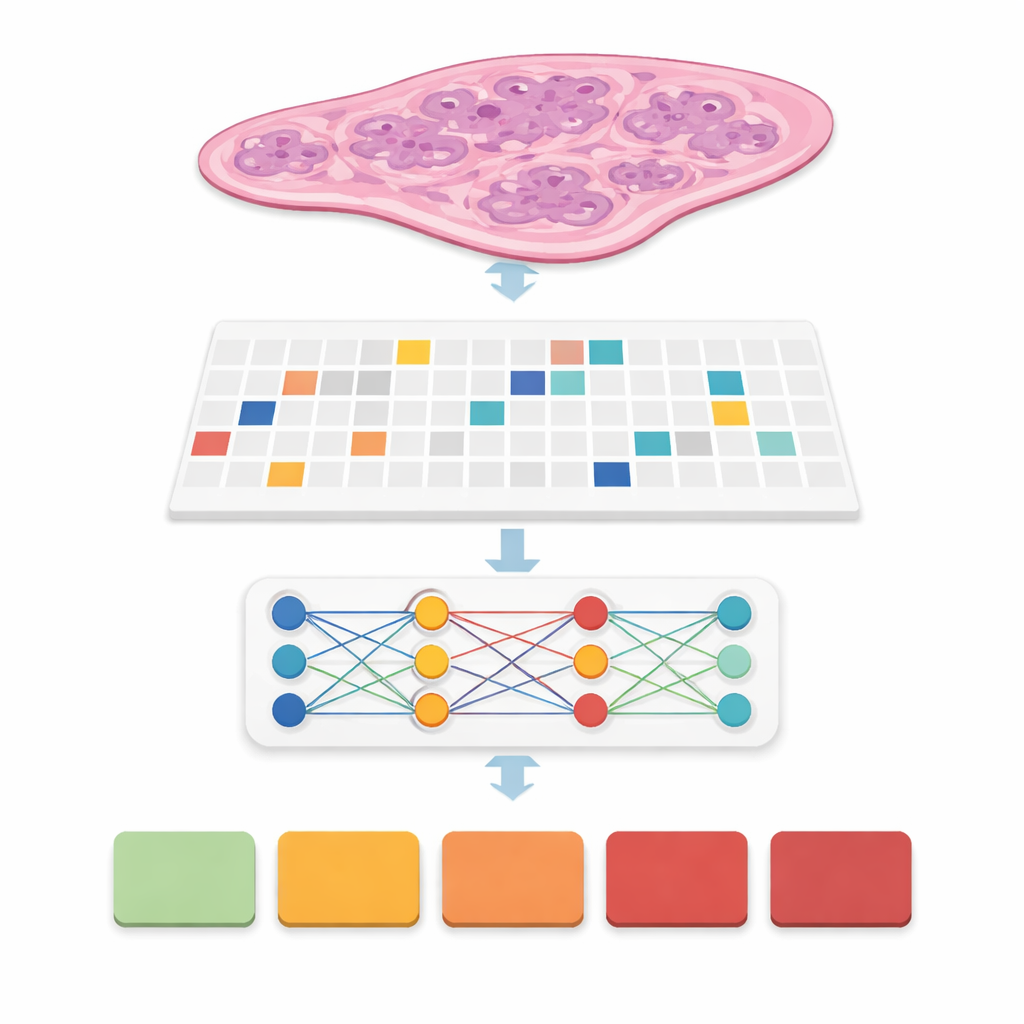
Ensinando computadores a ver o câncer sem rótulos pixel a pixel
Em muitos sistemas anteriores, especialistas precisavam desenhar contornos precisos ao redor de cada foco de câncer, uma etapa demorada que dificulta a implantação em cenários reais. Aqui, a equipe usou uma abordagem chamada supervisão fraca: o computador vê apenas um rótulo ao nível da lâmina, como o grupo final de classificação do câncer de 0 (benigno) a 5 (mais agressivo), sem marcações detalhadas internas. Cada lâmina torna‑se uma "bag" de patches, e modelos especiais aprendem quais patches importam mais para prever a classificação global. Essa família de métodos, chamada aprendizagem por instância múltipla, permite que o computador descubra padrões de glândulas e células que distinguem doença branda de agressiva, reduzindo muito a carga de trabalho dos patologistas durante o treinamento.
Comparando muitos blocos de construção da IA lado a lado
Em vez de propor apenas um novo modelo, os autores construíram um benchmark cuidadoso. Combinaram seis projetos líderes de aprendizagem por instância múltipla com três extratores de características diferentes, ou "encoders", que transformam cada patch em uma impressão numérica rica. Um encoder era um modelo clássico de visão treinado em fotos do cotidiano, enquanto os outros eram grandes modelos "foundation" treinados especificamente em centenas de milhares de lâminas de patologia. Executaram todas essas combinações sob quatro configurações de patch e cinco dobras de validação cruzada, resultando em 360 execuções de treinamento e 72 configurações principais. O desempenho foi medido com acurácia, vários tipos de F‑score e kappa ponderado quadrático, uma estatística que recompensa chegar perto da decisão do especialista mesmo quando não é perfeitamente exata.
Encontrando o ponto ideal: patches pequenos com sobreposição e um modelo foundation de patologia
O vencedor claro surgiu quando a equipe usou patches de tecido relativamente pequenos (256 por 256 pixels) com 50% de sobreposição, codificados pelo modelo foundation UNI2 e agregados por um método de atenção de baixa classificação chamado ILRA‑MIL. Essa combinação atingiu cerca de 79% de acurácia e um kappa ponderado quadrático muito alto, pouco acima de 0,90, aproximando‑se dos níveis de concordância observados entre especialistas no desafio PANDA original. Patches menores e sobrepostos deram ao modelo tanto detalhes celulares finos quanto contexto suficiente, enquanto o encoder específico para patologia superou claramente a rede genérica treinada em fotos por 15–20 pontos percentuais em acurácia. Importante, os autores mostraram que esses ganhos são alcançáveis com recursos de nuvem acessíveis, usando computação distribuída em plataformas públicas em vez de clusters dedicados caros. 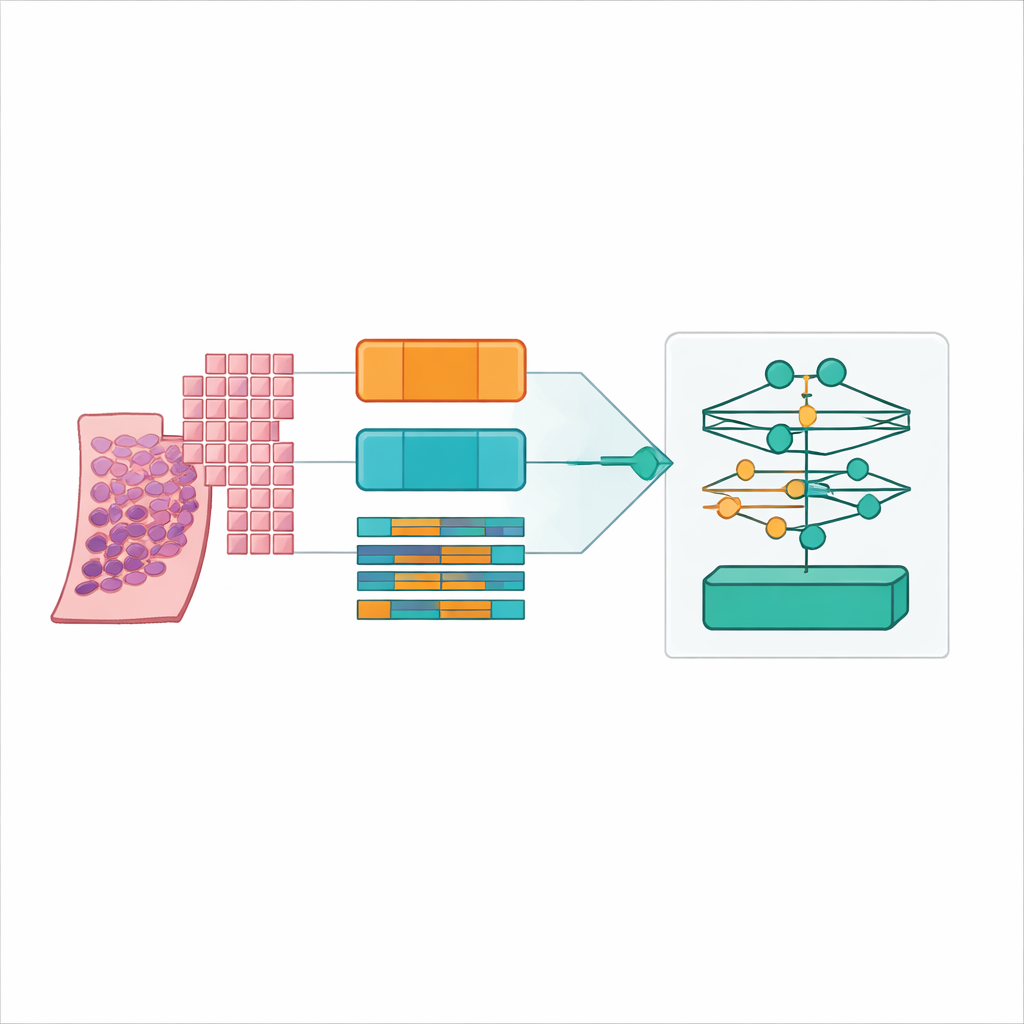
Tornando as decisões da IA visíveis para os patologistas
Para qualquer ferramenta que possa influenciar o tratamento, não basta ser precisa; os médicos precisam entender por que ela faz determinada escolha. Os pesquisadores incorporaram mapas de atenção e mapas de calor Grad‑CAM que destacam quais regiões de uma lâmina motivaram a predição. Essas explicações visuais podem ser sobrepostas à imagem do tecido para que um patologista confirme que o modelo está realmente focando em glândulas cancerosas ou em padrões agressivos, e não em ruído ou estruturas benignas. Essa preocupação com interpretabilidade, combinada a uma interface baseada na web e a um fluxo de trabalho totalmente descrito da lâmina bruta até a predição, pretende facilitar a adoção e a validação independente em laboratórios clínicos.
O que isso significa para o futuro do cuidado do câncer de próstata
Em termos simples, o estudo mostra que um sistema de IA cuidadosamente projetado pode classificar o câncer de próstata em lâminas digitais com desempenho próximo ao de patologistas especialistas, sem exigir desenhos manuais exaustivos em cada lâmina de treinamento. A receita mais eficaz usa muitos pequenos blocos de imagem sobrepostos e um grande encoder treinado em patologia alimentando um modelo baseado em atenção que pode apontar de volta para o tecido em que se baseou. Embora o trabalho ainda dependa de um único grande conjunto de dados e precise de testes mais amplos entre hospitais, ele oferece um caminho realista para diagnósticos de câncer de próstata mais rápidos, mais consistentes e mais amplamente disponíveis, especialmente em regiões onde especialistas são escassos.
Citação: Butt, N.A., Sarwat, D., Noya, I.D. et al. Benchmarking multiple instance learning architectures from patches to pathology for prostate cancer detection and grading using attention-based weak supervision. Sci Rep 16, 11535 (2026). https://doi.org/10.1038/s41598-026-39196-x
Palavras-chave: câncer de próstata, patologia digital, aprendizado com supervisão fraca, aprendizado por instância múltipla, patologia computacional