Clear Sky Science · sv
Jämförelse av multiple instance learning‑arkitekturer från patchar till patologi för upptäckt och gradbedömning av prostatacancer med uppmärksamhetsbaserad svagt övervakad inlärning
Varför detta är viktigt för patienter och läkare
Prostatacancer är en av de vanligaste cancerformerna hos män, och bedömningen av hur allvarlig den är utifrån mikroskopiska snitt påverkar direkt behandlingsval. I dag går den här graderingen långsamt, kan variera mellan patologer och är svår att skala upp i takt med en åldrande befolkning. Denna studie visar hur modern artificiell intelligens kan lära sig bedöma cancergrad från digitala snitt med betydligt färre mänskliga markeringar än tidigare, samtidigt som resultaten förblir begripliga för läkare. Det gör tekniken till en realistisk kandidat för att stödja vardagsdiagnostik i verkliga sjukhus istället för enbart i forskningsmiljöer.
Från jättelika snitt till små bildrutor
Moderna skannrar förvandlar en tunn bit prostatavävnad till en gigantisk digital bild, ofta 20 000 gånger 20 000 pixlar. Största delen av bilden är bakgrund, och även den användbara vävnaden är alltför stor för att mata in i en vanlig datormodell på en gång. Forskarna löste detta genom att dela varje helt snitt i många små kvadratiska "patchar" av vävnad, ungefär som att göra ett pussel av en affisch. De detekterade noggrant enbart de verkliga vävnadsregionerna, filtrerade bort tomma områden och artefakter, och genererade koordinatkartor som talar om för datorn exakt var den ska sampla. De testade fyra patch‑strategier, med stora och små rutor och med eller utan överlappning, och producerade slutligen mer än 31 miljoner patchar från över 10 600 snitt i en stor offentlig prostatacancer‑datamängd kallad PANDA. 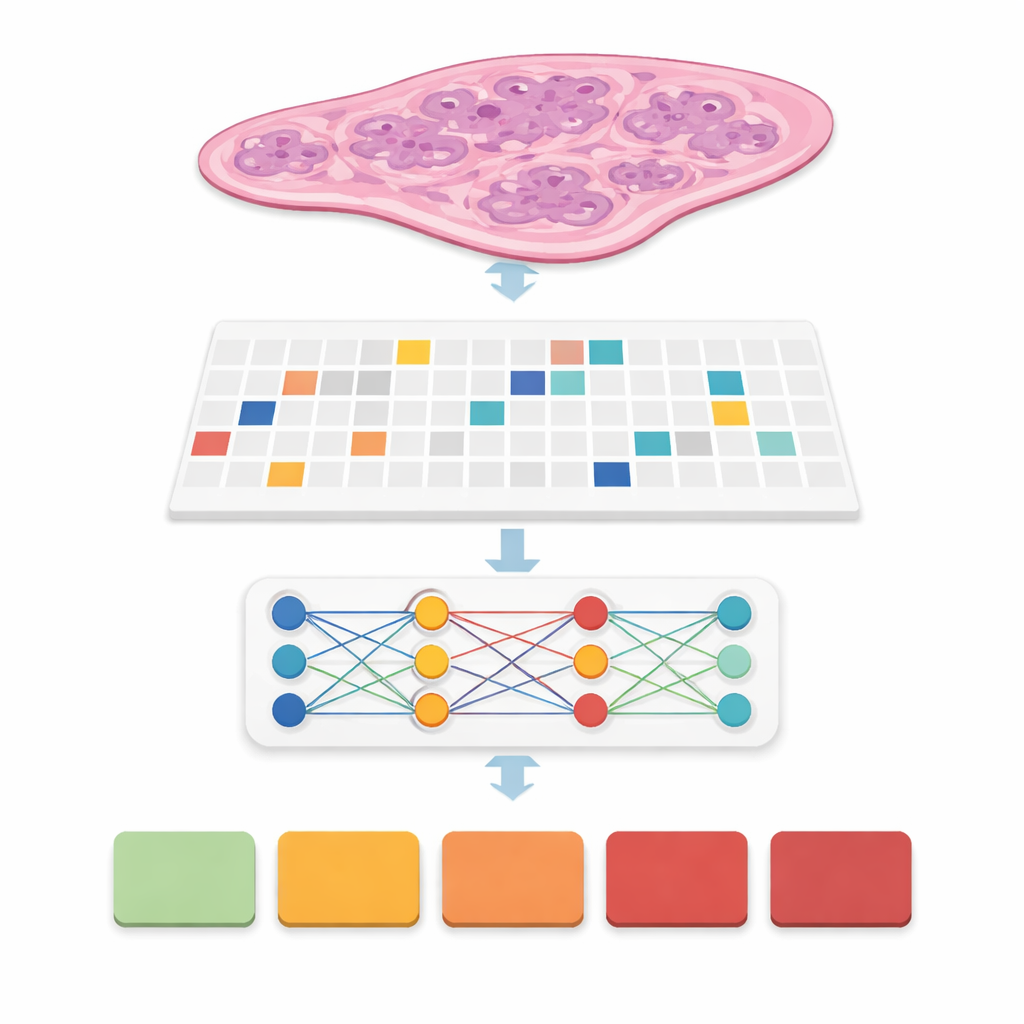
Att lära datorer att se cancer utan pixel‑för‑pixel‑etiketter
I många tidigare system var experter tvungna att rita precisa konturer runt varje cancerfokus, ett tidskrävande steg som försvårar verklig implementering. Här använde teamet en metod kallad svag övervakning: datorn ser endast en snittnivåetikett, till exempel slutligt cancergruppsgrad från 0 (godartad) till 5 (mest aggressiv), utan några detaljerade markeringar inuti. Varje snitt blir en "påse" av patchar, och specialiserade modeller lär sig vilka patchar som är viktigast för att förutsäga den övergripande graden. Denna metodfamilj, kallad multiple instance learning, låter datorn upptäcka mönster i körtlar och celler som skiljer mild från aggressiv sjukdom samtidigt som patologernas arbetsbörda under träning minskas avsevärt.
Jämförelse av många AI‑byggstenar sida vid sida
I stället för att föreslå en enda ny modell byggde författarna en noggrann benchmark. De kombinerade sex ledande multiple‑instance learning‑designer med tre olika feature‑extraktorer, eller "enkodare", som omvandlar varje patch till ett rikt numeriskt fingeravtryck. En enkodare var en klassisk visionsmodell tränad på vardagsfoton, medan de andra var stora "foundation"‑modeller tränade specifikt på hundratusentals patologisnitt. De körde alla dessa kombinationer under fyra patchinställningar och fem korsvalideringsfoldar, vilket gav 360 träningar och 72 kärnkonfigurationer. Prestanda mättes med noggrannhet, flera varianter av F‑poäng och kvadratisk viktad kappa, en statistik som belönar att komma nära expertens grad även när det inte är perfekt.
Att hitta den bästa kombinationen: små överlappande patchar och en patologi‑foundationmodell
Den tydliga vinnaren framträdde när teamet använde relativt små vävnadspatchar (256 gånger 256 pixlar) med 50 procent överlappning, kodade av UNI2‑foundationmodellen och aggregerade med en låg‑rankad uppmärksamhetsmetod kallad ILRA‑MIL. Denna kombination nådde cirka 79 procent noggrannhet och en mycket hög kvadratisk viktad kappa strax över 0,90, vilket närmar sig överensstämmelsen som ses mellan mänskliga experter i det ursprungliga PANDA‑utmaningen. Mindre, överlappande patchar gav modellen både fin cellulär detalj och tillräcklig kontext, medan den patologi‑specifika enkodaren tydligt överträffade det generiska fotonätverket med 15–20 procentenheter i noggrannhet. Viktigt är att författarna visade att dessa vinster är möjliga med tillgängliga molnresurser, med distribuerad beräkning på publika plattformar snarare än dyra dedikerade kluster. 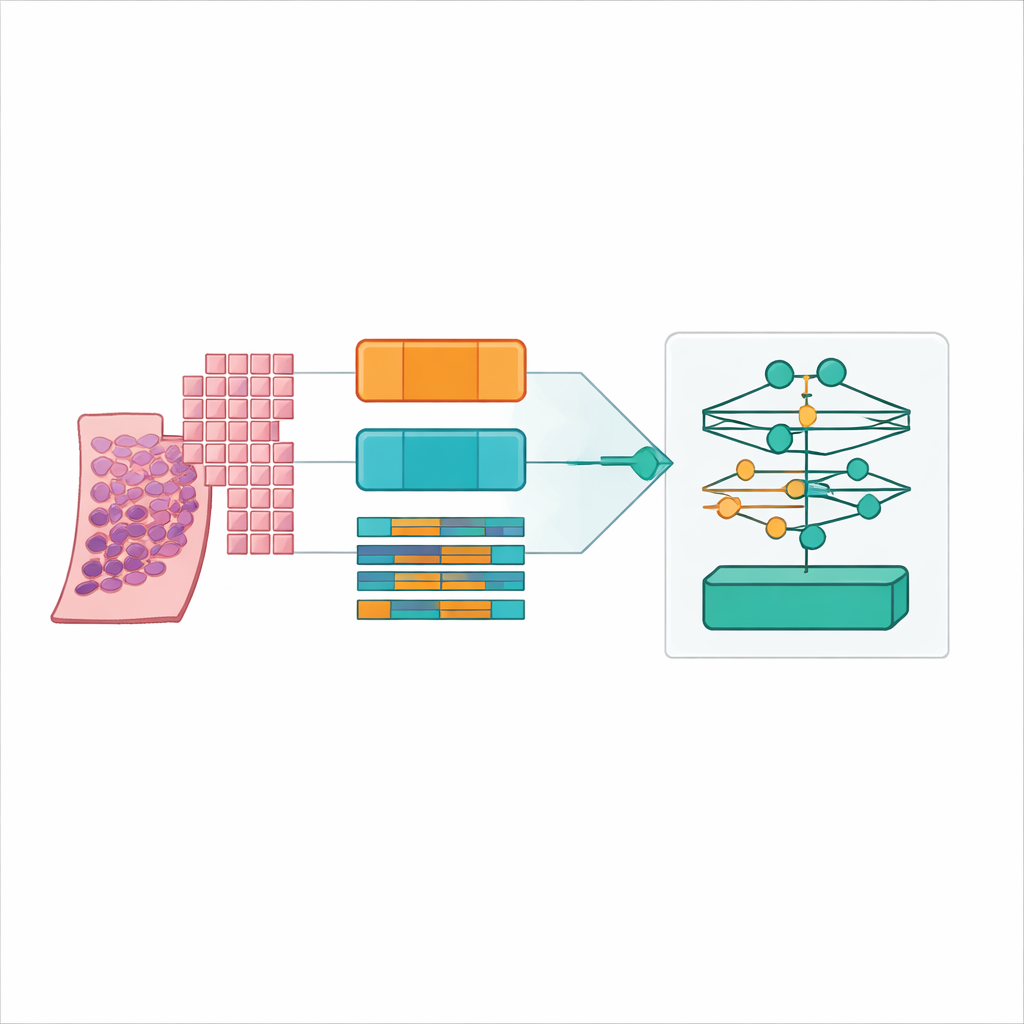
Göra AI‑beslut synliga för patologer
För ett verktyg som kan påverka behandling räcker det inte att vara korrekt; läkare behöver förstå varför det ger ett visst omdöme. Forskarna byggde in uppmärksamhetskartor och Grad‑CAM‑värmekartor som lyfter fram vilka regioner av ett snitt som drev prediktionen. Dessa visuella förklaringar kan överlagras på vävnadsbilden så att en patolog kan bekräfta att modellen verkligen fokuserar på cancerösa körtlar eller aggressiva mönster snarare än brus eller godartade strukturer. Denna betoning på tolkbarhet, kombinerad med ett webbaserat gränssnitt och ett fullständigt beskrivet arbetsflöde från rått snitt till prediktion, är avsedd att underlätta adoption och oberoende validering i kliniska laboratorier.
Vad detta betyder för framtida prostatacancervård
Enkelt uttryckt visar studien att ett väl utformat AI‑system kan gradera prostatacancer på digitala snitt med prestanda nära specialiserade patologers, utan att kräva uttömmande manuella ritningar på varje träningssnitt. Den mest effektiva recepten använder många små, överlappande bildrutor och en stor patologi‑tränad enkodare som matar in i en uppmärksamhetsbaserad modell som kan peka tillbaka på den vävnad den förlitade sig på. Även om arbetet fortfarande är beroende av en större datamängd och behöver bredare sjukhus‑till‑sjukhus‑testning, erbjuder det en realistisk väg mot snabbare, mer konsekvent och mer tillgänglig prostatacancerdiagnostik, särskilt i regioner där expertpatologer är knappa.
Citering: Butt, N.A., Sarwat, D., Noya, I.D. et al. Benchmarking multiple instance learning architectures from patches to pathology for prostate cancer detection and grading using attention-based weak supervision. Sci Rep 16, 11535 (2026). https://doi.org/10.1038/s41598-026-39196-x
Nyckelord: prostatacancer, digital patologi, svagt övervakad inlärning, multiple instance learning, beräkningspatologi