Clear Sky Science · fr
Évaluation comparative des architectures d’apprentissage par instances multiples, des fragments aux diagnostics en pathologie pour la détection et le classement du cancer de la prostate en utilisant une supervision faible basée sur l’attention
Pourquoi c’est important pour les patients et les médecins
Le cancer de la prostate est l’un des cancers les plus fréquents chez l’homme, et l’évaluation de sa gravité à partir de lames au microscope influence directement les choix thérapeutiques. Aujourd’hui, ce travail de graduation est lent, peut varier d’un pathologiste à l’autre et est difficile à étendre face au vieillissement des populations. Cette étude montre comment l’intelligence artificielle moderne peut apprendre à estimer la sévérité d’un cancer à partir de lames numériques en nécessitant beaucoup moins d’annotations humaines qu’auparavant, tout en restant compréhensible pour les médecins. Cela en fait une candidate réaliste pour assister le diagnostic quotidien dans des hôpitaux réels et pas seulement dans des laboratoires de recherche.
Des lames géantes aux petites tuiles d’image
Les scanners modernes transforment une coupe mince de tissu prostatique en une image numérique gigantesque, souvent de 20 000 par 20 000 pixels. La majeure partie de cette image est du fond, et même le tissu utile est bien trop volumineux pour être traité en une seule fois par un modèle informatique classique. Les chercheurs ont résolu ce problème en découpant chaque lame complète en nombreuses petites « tuiles » carrées de tissu, comme transformer une affiche en puzzle. Ils ont détecté avec soin les régions de tissu effectives, filtré les zones vides et les artefacts, et généré des cartes de coordonnées indiquant à l’ordinateur où échantillonner exactement. Ils ont testé quatre stratégies de découpage, mélangeant tuiles grandes et petites et avec ou sans chevauchement, produisant finalement plus de 31 millions de tuiles à partir de plus de 10 600 lames dans un grand jeu de données public sur le cancer de la prostate appelé PANDA. 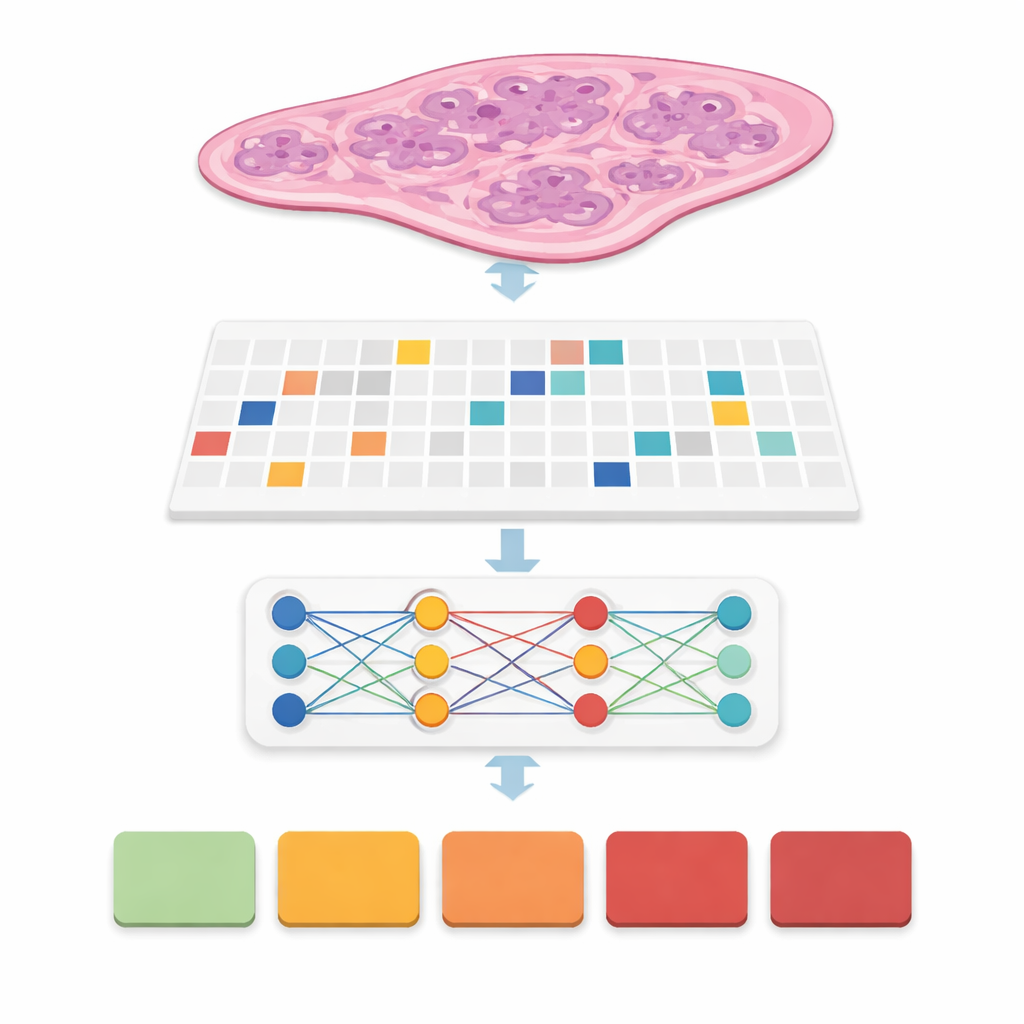
Apprendre aux ordinateurs à voir le cancer sans annotations pixel par pixel
Dans de nombreux systèmes antérieurs, les experts devaient dessiner des contours précis autour de chaque foyer cancéreux, une étape chronophage qui complique le déploiement en conditions réelles. Ici, l’équipe a utilisé une approche dite de supervision faible : l’ordinateur ne voit qu’une étiquette au niveau de la lame, par exemple le groupe de grade final du cancer de 0 (bénin) à 5 (le plus agressif), sans aucune annotation détaillée à l’intérieur. Chaque lame devient un « sac » de tuiles, et des modèles spécialisés apprennent quelles tuiles importent le plus pour prédire le grade global. Cette famille de méthodes, appelée apprentissage par instances multiples, permet à l’ordinateur de découvrir des motifs de glandes et de cellules qui distinguent maladie légère et maladie agressive tout en réduisant considérablement la charge de travail des pathologistes pendant l’entraînement.
Comparer de nombreux éléments d’IA tête-à-tête
Plutôt que de proposer un seul nouveau modèle, les auteurs ont construit une évaluation comparative rigoureuse. Ils ont combiné six architectures majeures d’apprentissage par instances multiples avec trois extracteurs de caractéristiques différents, ou « encodeurs », qui transforment chaque tuile en un riche vecteur numérique. Un encodeur était un modèle de vision classique entraîné sur des photos courantes, tandis que les autres étaient de grands modèles « fondation » entraînés spécifiquement sur des centaines de milliers de lames de pathologie. Ils ont exécuté toutes ces combinaisons sous quatre paramètres de tuiles et cinq plis de validation croisée, aboutissant à 360 entraînements et 72 configurations principales. Les performances ont été mesurées par l’exactitude, plusieurs types de scores F et le kappa quadratique pondéré, une statistique qui récompense le fait d’obtenir un grade proche de la décision de l’expert même lorsqu’il n’est pas parfaitement exact.
Trouver le point optimal : petites tuiles chevauchantes et modèle fondation en pathologie
Le vainqueur clair a émergé lorsque l’équipe a utilisé des tuiles de tissu relativement petites (256 par 256 pixels) avec un chevauchement de 50 %, encodées par le modèle fondation UNI2 et agrégées par une méthode d’attention à faible rang appelée ILRA‑MIL. Cette combinaison a atteint environ 79 % d’exactitude et un kappa quadratique pondéré très élevé juste au‑dessus de 0,90, se rapprochant des niveaux d’accord observés entre experts humains dans le défi PANDA original. Les petites tuiles chevauchantes ont offert au modèle à la fois un détail cellulaire fin et suffisamment de contexte, tandis que l’encodeur spécifique à la pathologie a clairement surpassé le réseau générique entraîné sur des photos de 15 à 20 points de pourcentage en exactitude. Fait important, les auteurs ont montré que ces gains sont réalisables avec des ressources cloud accessibles, en utilisant le calcul distribué sur des plateformes publiques plutôt que des grappes dédiées coûteuses. 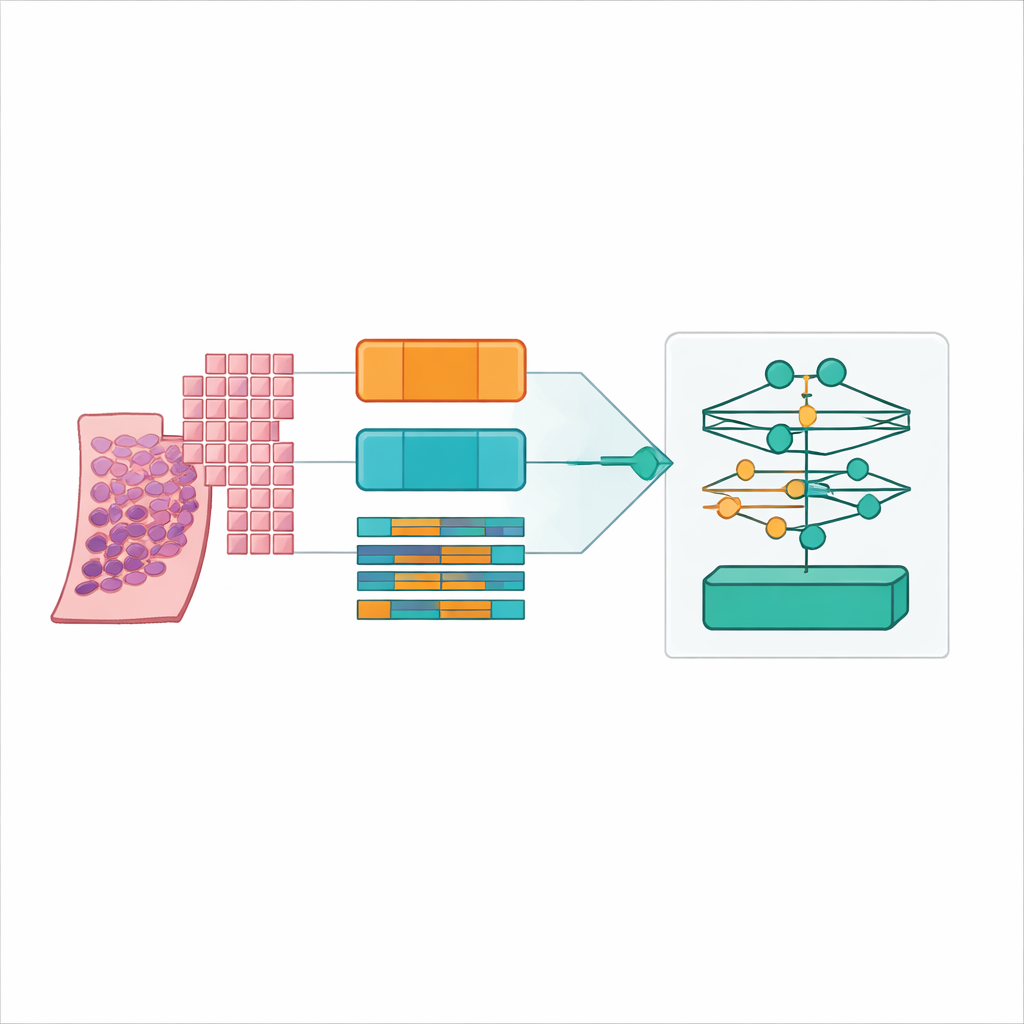
Rendre les décisions de l’IA visibles pour les pathologistes
Pour tout outil susceptible d’influencer le traitement, il ne suffit pas d’être précis ; les médecins doivent comprendre pourquoi il rend une décision particulière. Les chercheurs ont intégré des cartes d’attention et des cartes de chaleur Grad‑CAM qui mettent en évidence les régions d’une lame ayant motivé la prédiction. Ces explications visuelles peuvent être superposées à l’image du tissu afin qu’un pathologiste puisse vérifier que le modèle se concentre réellement sur des glandes cancéreuses ou des motifs agressifs plutôt que sur du bruit ou des structures bénignes. Cette attention à l’interprétabilité, combinée à une interface web et à un flux de travail entièrement décrit depuis la lame brute jusqu’à la prédiction, vise à faciliter l’adoption et la validation indépendante dans les laboratoires cliniques.
Ce que cela signifie pour la prise en charge future du cancer de la prostate
En termes clairs, l’étude montre qu’un système d’IA bien conçu peut graduer le cancer de la prostate sur des lames numériques avec des performances proches de celles de pathologistes spécialistes, sans exiger des tracés manuels exhaustifs sur chaque lame d’entraînement. La recette la plus efficace utilise de nombreuses petites tuiles d’image chevauchantes et un grand encodeur entraîné en pathologie alimentant un modèle basé sur l’attention capable de renvoyer aux zones de tissu sur lesquelles il s’est appuyé. Bien que le travail repose encore sur un jeu de données majeur unique et nécessite des tests plus larges d’hôpital à hôpital, il offre une voie réaliste vers des diagnostics du cancer de la prostate plus rapides, plus cohérents et plus largement disponibles, en particulier dans les régions où les pathologistes experts font défaut.
Citation: Butt, N.A., Sarwat, D., Noya, I.D. et al. Benchmarking multiple instance learning architectures from patches to pathology for prostate cancer detection and grading using attention-based weak supervision. Sci Rep 16, 11535 (2026). https://doi.org/10.1038/s41598-026-39196-x
Mots-clés: cancer de la prostate, pathologie numérique, apprentissage faiblement supervisé, apprentissage par instances multiples, pathologie computationnelle