Clear Sky Science · it
Valutazione comparativa di architetture di multiple instance learning da patch a patologia per la rilevazione e la stadiazione del cancro alla prostata usando supervisione debole basata su attention
Perché questo è importante per pazienti e medici
Il cancro alla prostata è uno dei tumori più comuni negli uomini, e determinare quanto sia grave a partire dalle vetrini al microscopio influisce direttamente sulle scelte terapeutiche. Oggi questa valutazione è lenta, può variare tra patologi diversi ed è difficile da scalare con l’invecchiamento della popolazione. Questo studio mostra come l’intelligenza artificiale moderna possa apprendere a giudicare la gravità del tumore da vetrini digitali usando molto meno markup umano rispetto al passato, pur restando interpretabile per i medici. Ciò la rende una candidata realistica per supportare la diagnosi di routine in ospedali reali, non solo nei laboratori di ricerca.
Dalle vetrini giganti alle piccole tessere d’immagine
I moderni scanner trasformano una sottile sezione di tessuto prostatico in un’enorme immagine digitale, spesso di 20.000 per 20.000 pixel. Gran parte di quell’immagine è sfondo, e anche il tessuto utile è troppo grande per essere fornito interamente a un modello informatico tipico. I ricercatori hanno risolto questo problema ritagliando ogni vetrino in molte piccole «patch» quadrate di tessuto, come trasformare un poster in un puzzle. Hanno rilevato con cura solo le vere regioni di tessuto, filtrato aree vuote e artefatti e generato mappe di coordinate che indicano al computer dove campionare esattamente. Hanno testato quattro strategie di patch, mixando quadrati grandi e piccoli e con o senza sovrapposizione, producendo infine più di 31 milioni di patch da oltre 10.600 vetrini in un ampio dataset pubblico sul cancro alla prostata chiamato PANDA. 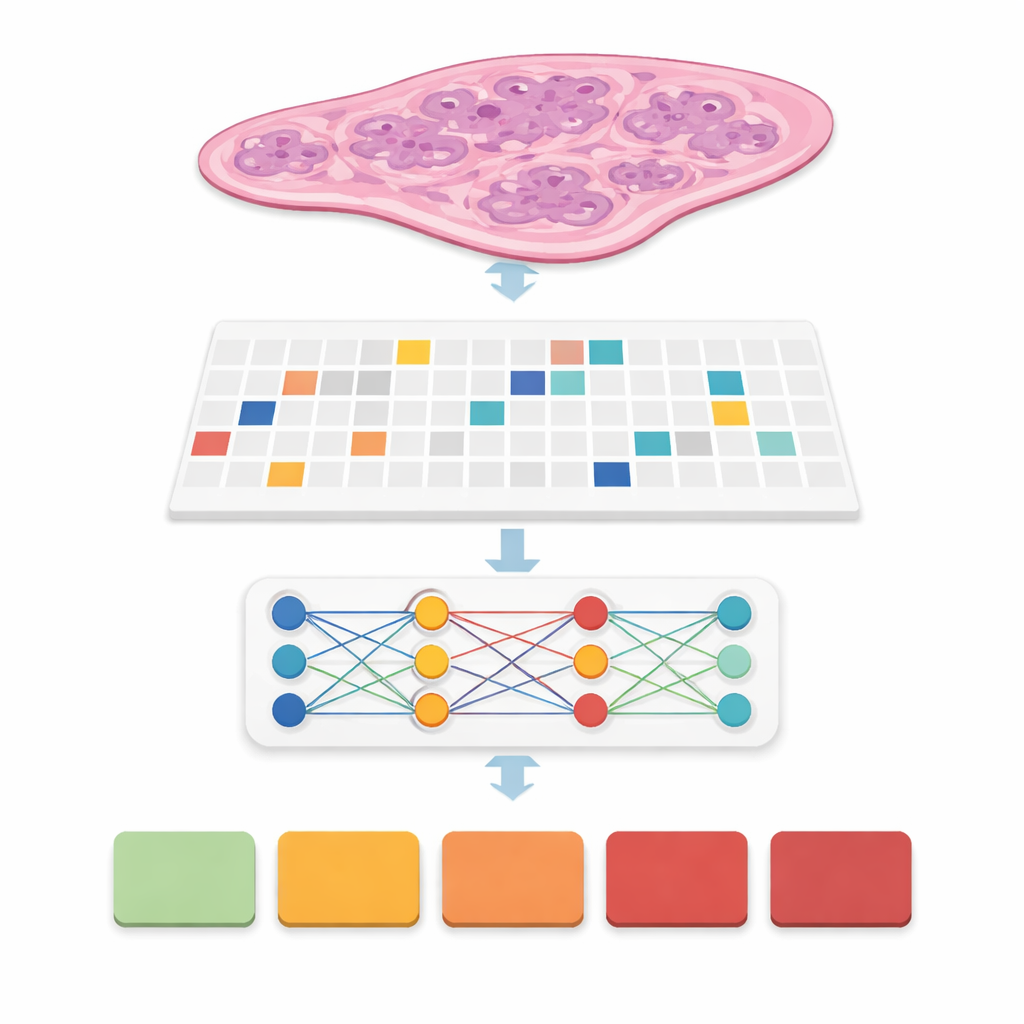
Insegnare ai computer a riconoscere il cancro senza etichette pixel‑per‑pixel
In molti sistemi precedenti, gli esperti dovevano tracciare contorni precisi attorno a ogni focolaio tumorale, un passaggio che richiede molto tempo e rende difficile l’implementazione nel mondo reale. Qui il gruppo ha usato un approccio chiamato supervisione debole: il computer vede solo un’etichetta a livello di vetrino, come il gruppo di grado finale del cancro da 0 (benigno) a 5 (più aggressivo), senza segnalazioni dettagliate all’interno. Ogni vetrino diventa una «busta» di patch, e modelli speciali imparano quali patch sono più importanti per predire il grado complessivo. Questa famiglia di metodi, chiamata multiple instance learning, permette al computer di scoprire pattern di ghiandole e cellule che distinguono malattia lieve da aggressiva riducendo notevolmente il carico di lavoro dei patologi durante l’addestramento.
Confrontare molti componenti di IA testa a testa
Invece di proporre un singolo nuovo modello, gli autori hanno costruito un benchmark accurato. Hanno combinato sei progetti leader di multiple‑instance learning con tre diversi estrattori di caratteristiche, o «encoder», che trasformano ogni patch in un ricco impronta numerica. Un encoder era un modello visivo classico addestrato su foto di uso quotidiano, mentre gli altri erano grandi modelli «foundation» addestrati specificamente su centinaia di migliaia di vetrini di patologia. Hanno eseguito tutte queste combinazioni sotto quattro impostazioni di patch e cinque fold di cross‑validation, producendo 360 sessioni di addestramento e 72 configurazioni principali. Le prestazioni sono state misurate con accuratezza, diversi tipi di punteggio F e il kappa pesato quadratico, una statistica che premia il fatto di avvicinarsi al grado assegnato dall’esperto anche quando non è perfettamente esatto.
Trovare il punto ottimale: patch piccole sovrapposte e un foundation model di patologia
Il chiaro vincitore è emerso quando il team ha usato patch di tessuto relativamente piccole (256 per 256 pixel) con il 50% di sovrapposizione, codificate dal modello foundation UNI2 e aggregate da un metodo di attention a rango basso chiamato ILRA‑MIL. Questa combinazione ha raggiunto circa il 79% di accuratezza e un kappa pesato quadratico molto elevato appena sopra 0,90, avvicinandosi ai livelli di concordanza osservati tra esperti umani nella sfida PANDA originale. Patch più piccole e sovrapposte hanno fornito al modello sia dettaglio cellulare fine sia sufficiente contesto, mentre l’encoder specifico per patologia ha superato nettamente la rete generica addestrata su foto di uso quotidiano di circa 15–20 punti percentuali in accuratezza. Importante, gli autori hanno dimostrato che questi guadagni sono raggiungibili con risorse cloud accessibili, usando calcolo distribuito su piattaforme pubbliche anziché costosi cluster dedicati. 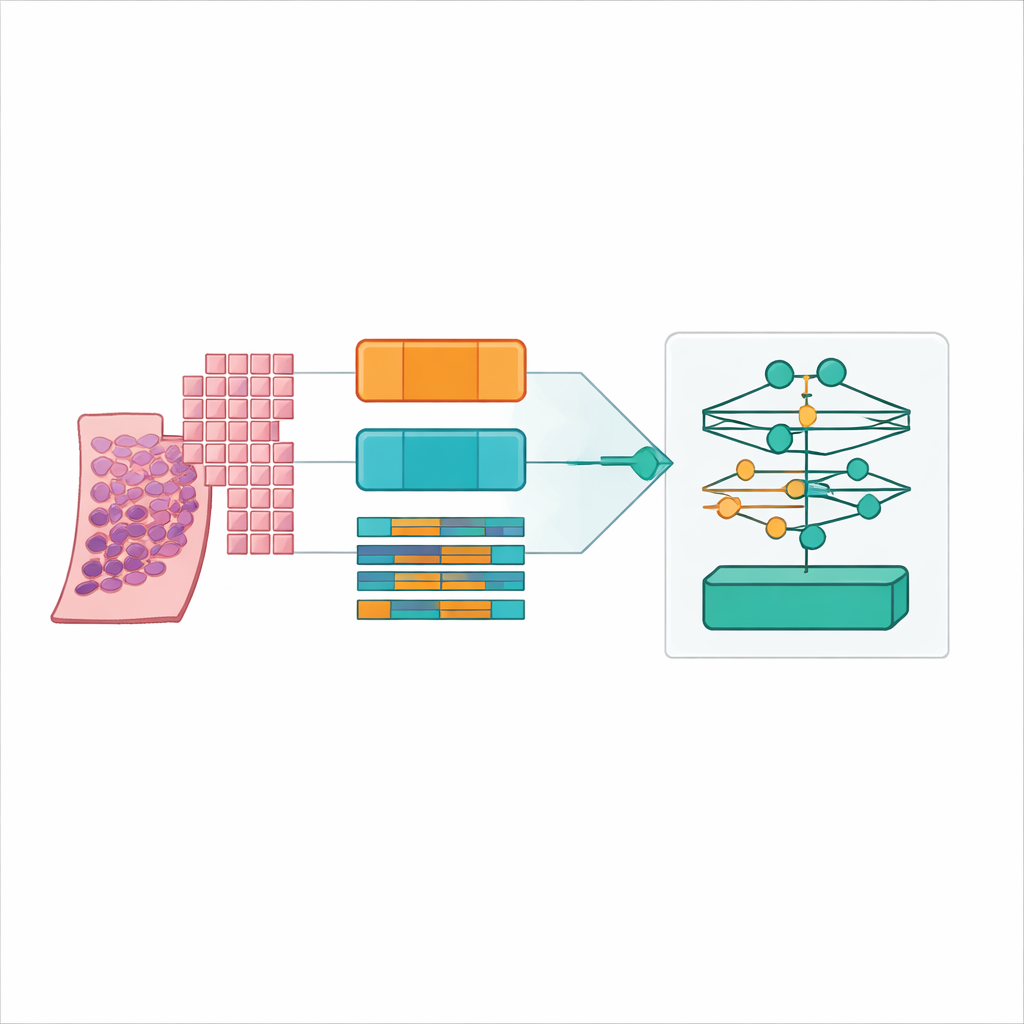
Rendere visibili le decisioni dell’IA ai patologi
Per qualsiasi strumento che possa influenzare il trattamento non basta essere precisi; i medici devono comprendere perché viene presa una determinata decisione. I ricercatori hanno integrato mappe di attention e mappe di calore Grad‑CAM che evidenziano quali regioni del vetrino hanno guidato la predizione. Queste spiegazioni visive possono essere sovrapposte all’immagine del tessuto in modo che un patologo possa confermare che il modello si sta davvero focalizzando su ghiandole cancerose o pattern aggressivi piuttosto che su rumore o strutture benigne. Questa attenzione all’interpretabilità, combinata con un’interfaccia web e un flusso di lavoro completamente descritto dalla vetrino grezzo alla predizione, è pensata per facilitare l’adozione e la validazione indipendente nei laboratori clinici.
Cosa significa per la futura cura del cancro alla prostata
In termini semplici, lo studio mostra che un sistema di IA progettato con cura può valutare il grado del cancro alla prostata su vetrini digitali con prestazioni vicine a quelle di patologi specialisti, senza richiedere il disegno esaustivo manuale su ogni vetrino di addestramento. La ricetta più efficace usa molte piccole tessere d’immagine sovrapposte e un grande encoder addestrato su patologia che alimenta un modello basato su attention in grado di rimandare alle aree di tessuto su cui si è basato. Pur dipendendo ancora da un singolo grande dataset e necessitando di test più ampi tra ospedali diversi, offre una strada realistica verso diagnosi del cancro alla prostata più rapide, più coerenti e più ampiamente disponibili, specialmente in aree dove gli esperti patologi sono scarsi.
Citazione: Butt, N.A., Sarwat, D., Noya, I.D. et al. Benchmarking multiple instance learning architectures from patches to pathology for prostate cancer detection and grading using attention-based weak supervision. Sci Rep 16, 11535 (2026). https://doi.org/10.1038/s41598-026-39196-x
Parole chiave: cancro alla prostata, patologia digitale, apprendimento debolmente supervisionato, multiple instance learning, patologia computazionale