Clear Sky Science · pl
Porównanie architektur uczenia wielookienkowego od wycinków do patologii w wykrywaniu i gradacji raka prostaty z wykorzystaniem uwagowo‑opartego słabego nadzoru
Dlaczego to ma znaczenie dla pacjentów i lekarzy
Rak prostaty jest jednym z najczęstszych nowotworów u mężczyzn, a ocena jego zaawansowania na podstawie preparatów mikroskopowych bezpośrednio wpływa na wybór leczenia. Obecnie to zadanie jest czasochłonne, może się różnić między patomorfologami i trudno je skalować wraz ze starzeniem się populacji. Badanie to pokazuje, jak nowoczesna sztuczna inteligencja może nauczyć się oceniać ciężkość choroby na cyfrowych skanach przy użyciu znacznie mniejszej liczby ludzkich oznaczeń niż dotąd, pozostając jednocześnie zrozumiałą dla lekarzy. To sprawia, że jest realistycznym kandydatem do wspierania codziennej diagnostyki w rzeczywistych szpitalach, a nie tylko w laboratoriach badawczych.
Od olbrzymich skanów do drobnych kafelków obrazu
Nowoczesne skanery zamieniają cienki przekrój tkanki gruczołu krokowego w gigantyczne cyfrowe zdjęcie, często o rozmiarze 20 000 na 20 000 pikseli. Większość obrazu to tło, a nawet użyteczna tkanka jest zbyt duża, by w całości wprowadzić ją do typowego modelu komputerowego. Badacze rozwiązywali to, dzieląc każdy preparat na wiele małych kwadratowych „patchy” tkanki, jakby zamieniali plakat w puzzle. Starannie wykrywali rzeczywiste obszary tkankowe, odfiltrowywali puste fragmenty i artefakty oraz generowali mapy współrzędnych mówiące komputerowi, skąd pobierać próbki. Przetestowali cztery strategie dzielenia na patchy, mieszając duże i małe kwadraty oraz opcję z nakładaniem się lub bez, ostatecznie wygenerowali ponad 31 milionów patchy z ponad 10 600 skanów w dużym publicznym zbiorze danych o raku prostaty zwanym PANDA. 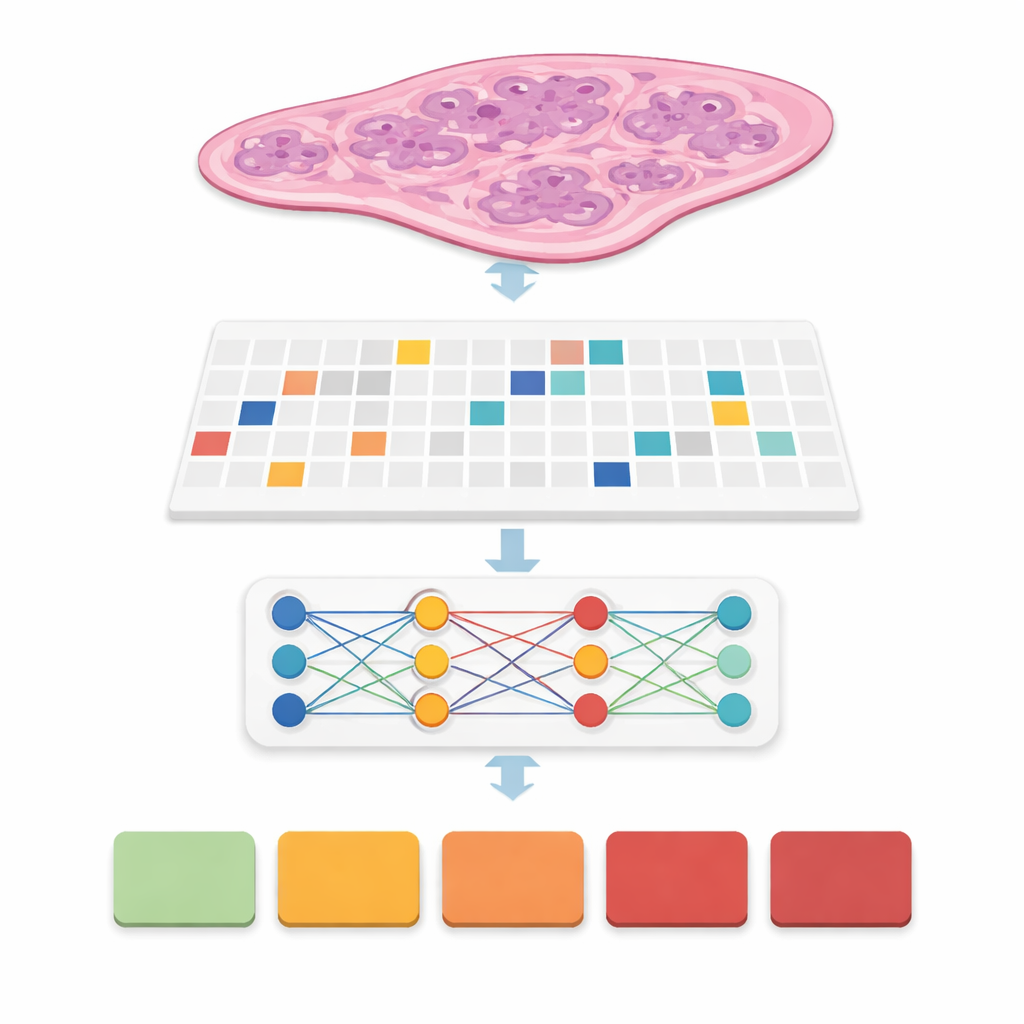
Nauczanie komputerów rozpoznawania raka bez pikselowych etykiet
W wielu wcześniejszych systemach eksperci musieli odręcznie obrysowywać każde ognisko nowotworu, co było czasochłonne i utrudniało wdrożenie w praktyce klinicznej. W tej pracy zespół zastosował podejście zwane słabym nadzorem: komputer widzi jedynie etykietę na poziomie całego skanu, na przykład ostateczną grupę stopnia raka od 0 (łagodny) do 5 (najbardziej agresywny), bez szczegółowych oznaczeń wewnątrz. Każdy skan staje się „workiem” patchy, a specjalne modele uczą się, które fragmenty mają największe znaczenie dla przewidywania ogólnego stopnia. Ta rodzina metod, zwana uczeniem wielookienkowym, pozwala komputerowi odkrywać wzorce gruczołów i komórek rozróżniające chorobę łagodną od agresywnej, przy znacznym zmniejszeniu nakładu pracy patomorfologów podczas treningu.
Porównanie wielu bloków budulcowych AI twarzą w twarz
Zamiast proponować jedynie jeden nowy model, autorzy zbudowali staranny benchmark. Połączyli sześć wiodących projektów uczenia wielookienkowego z trzema różnymi ekstraktorami cech, czyli „enkoderami”, które przekształcają każdy patch w bogaty wektor liczb. Jeden enkoder był klasycznym modelem wizji trenowanym na zdjęciach z codziennego życia, podczas gdy pozostałe to duże modele „fundacyjne” trenowane specjalnie na setkach tysięcy skanów patologicznych. Uruchomili wszystkie te kombinacje w ramach czterech ustawień patchy i pięciu foldów walidacji krzyżowej, co dało 360 treningów i 72 podstawowe konfiguracje. Wydajność mierzono dokładnością, kilkoma rodzajami miary F oraz kwadratowym ważonym kappą, statystyką nagradzającą przewidywanie stopnia raka zbliżone do oceny eksperta nawet jeśli nie jest idealnie dokładne.
Znajdowanie optymalnego rozwiązania: małe nakładające się patchy i fundacyjny model patologiczny
Wyraźnym zwycięzcą okazało się zastosowanie stosunkowo małych fragmentów tkanki (256 na 256 pikseli) z nakładaniem 50 procent, zakodowanych przez fundacyjny model UNI2 i agregowanych przez metodę uwagi o niskim rzędzie nazwaną ILRA‑MIL. Ta kombinacja osiągnęła około 79 procent dokładności i bardzo wysoką kwadratową ważoną kappę nieco ponad 0,90, zbliżając się do poziomów zgodności obserwowanych między ekspertami w oryginalnym konkursie PANDA. Mniejsze, nakładające się patchy dawały modelowi zarówno precyzyjne informacje o poziomie komórkowym, jak i wystarczający kontekst, podczas gdy enkoder wyszkolony na danych patologicznych wyraźnie przewyższał ogólny sieciowy model trenowany na zdjęciach o 15–20 punktów procentowych w dokładności. Co ważne, autorzy pokazali, że te zyski da się osiągnąć przy użyciu dostępnych zasobów chmurowych, wykorzystując obliczenia rozproszone na publicznych platformach zamiast drogich dedykowanych klastrów. 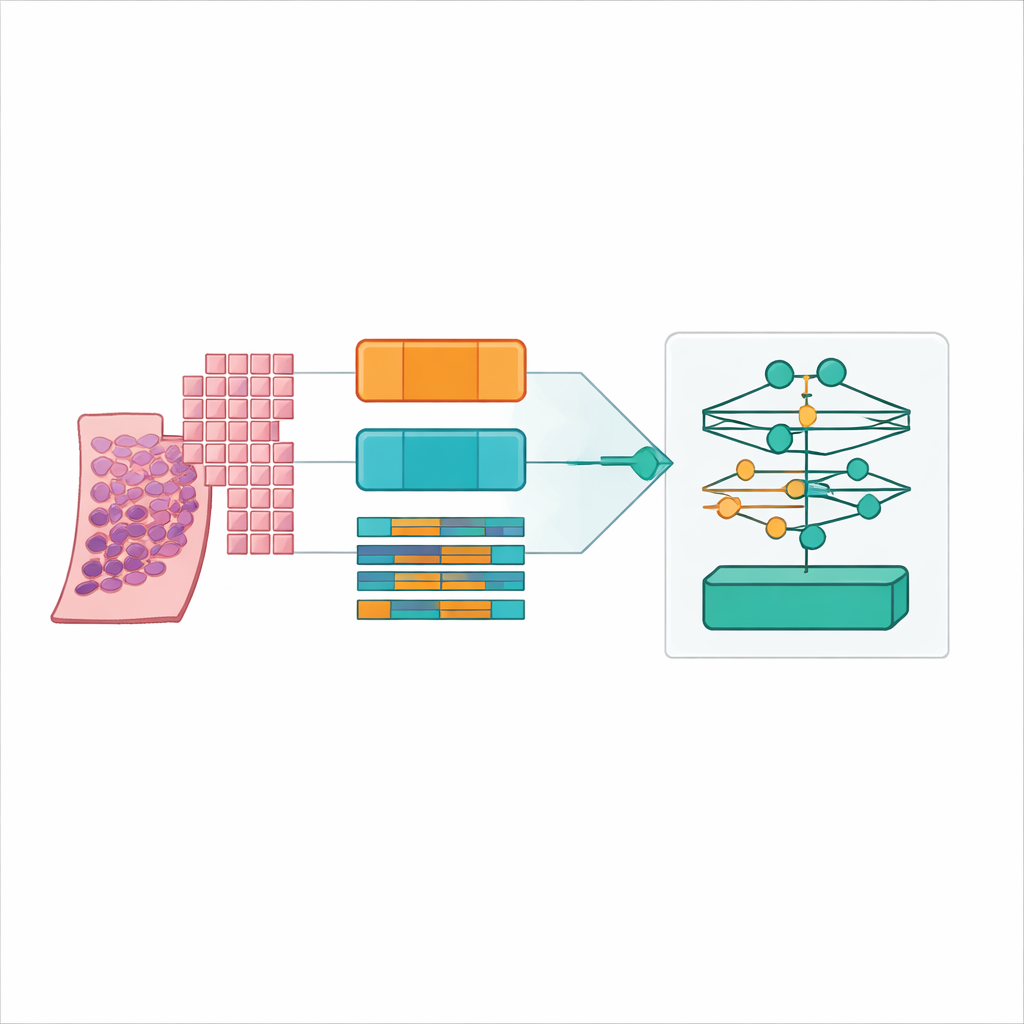
Uczynienie decyzji AI widocznymi dla patomorfologów
Dla każdego narzędzia, które może wpływać na leczenie, nie wystarczy sama dokładność; lekarze muszą rozumieć, dlaczego system podejmuje określoną decyzję. Badacze zaimplementowali mapy uwagi i mapy cieplne Grad‑CAM, które podświetlają obszary skanu mające największy wpływ na przewidywanie. Te wizualne wyjaśnienia można nałożyć na obraz tkanki, aby patomorfolog mógł potwierdzić, że model rzeczywiście skupia się na gruczołach nowotworowych lub wzorcach agresywnych, a nie na szumie czy strukturach łagodnych. To podejście do interpretowalności, połączone z interfejsem webowym i w pełni opisanym workflow od surowego skanu do predykcji, ma ułatwić adopcję i niezależną walidację w laboratoriach klinicznych.
Co to oznacza dla przyszłej opieki nad rakiem prostaty
Mówiąc prosto, badanie pokazuje, że starannie zaprojektowany system AI potrafi oceniać stopień zaawansowania raka prostaty na cyfrowych skanach z wydajnością zbliżoną do specjalistycznych patomorfologów, bez konieczności żmudnego ręcznego obrysowywania każdego skanu treningowego. Najskuteczniejszy przepis to wiele małych, nakładających się kafelków obrazu oraz duży enkoder trenowany na danych patologicznych w połączeniu z modelem opartym na uwadze, który potrafi wskazać fragmenty tkanki, na których się opierał. Choć praca nadal opiera się na jednym dużym zbiorze danych i wymaga szerszych testów międzyszpitalnych, oferuje realistyczną drogę do szybszej, bardziej spójnej i szerzej dostępnej diagnostyki raka prostaty, zwłaszcza w regionach, gdzie brakuje ekspertów patomorfologów.
Cytowanie: Butt, N.A., Sarwat, D., Noya, I.D. et al. Benchmarking multiple instance learning architectures from patches to pathology for prostate cancer detection and grading using attention-based weak supervision. Sci Rep 16, 11535 (2026). https://doi.org/10.1038/s41598-026-39196-x
Słowa kluczowe: rak prostaty, patologia cyfrowa, słabo nadzorowane uczenie, uczenie wielookienkowe, patologia obliczeniowa