Clear Sky Science · es
Evaluación comparativa de arquitecturas de aprendizaje por instancias múltiples desde parches hasta patología para la detección y graduación del cáncer de próstata usando supervisión débil basada en atención
Por qué esto importa para pacientes y médicos
El cáncer de próstata es uno de los tumores más frecuentes en hombres, y determinar su severidad a partir de láminas al microscopio influye directamente en las decisiones terapéuticas. Hoy en día, esta tarea de gradación es lenta, puede variar entre patólogos y resulta difícil de escalar en poblaciones envejecidas. Este estudio muestra cómo la inteligencia artificial moderna puede aprender a evaluar la gravedad del cáncer a partir de láminas digitales usando muchas menos anotaciones humanas que antes, manteniéndose al mismo tiempo comprensible para los médicos. Eso la convierte en una candidata realista para apoyar el diagnóstico cotidiano en hospitales reales y no solo en laboratorios de investigación.
De láminas gigantes a pequeñas teselas de imagen
Los escáneres modernos convierten una fina sección de tejido prostático en una imagen digital gigantesca, a menudo de 20 000 por 20 000 píxeles. La mayor parte de esa imagen es fondo, e incluso el tejido útil es demasiado grande para introducirlo en un modelo informático típico de una sola vez. Los investigadores resolvieron esto dividiendo cada lámina completa en muchos pequeños cuadrados o "parches" de tejido, como convertir un póster en un rompecabezas. Detectaron cuidadosamente solo las regiones con tejido verdadero, filtraron áreas vacías y artefactos, y generaron mapas de coordenadas que indican al ordenador dónde muestrear exactamente. Probaron cuatro estrategias de división en parches, combinando cuadrados grandes y pequeños y con solapamiento o sin él, produciendo finalmente más de 31 millones de parches a partir de más de 10 600 láminas en un gran conjunto público de cáncer de próstata llamado PANDA. 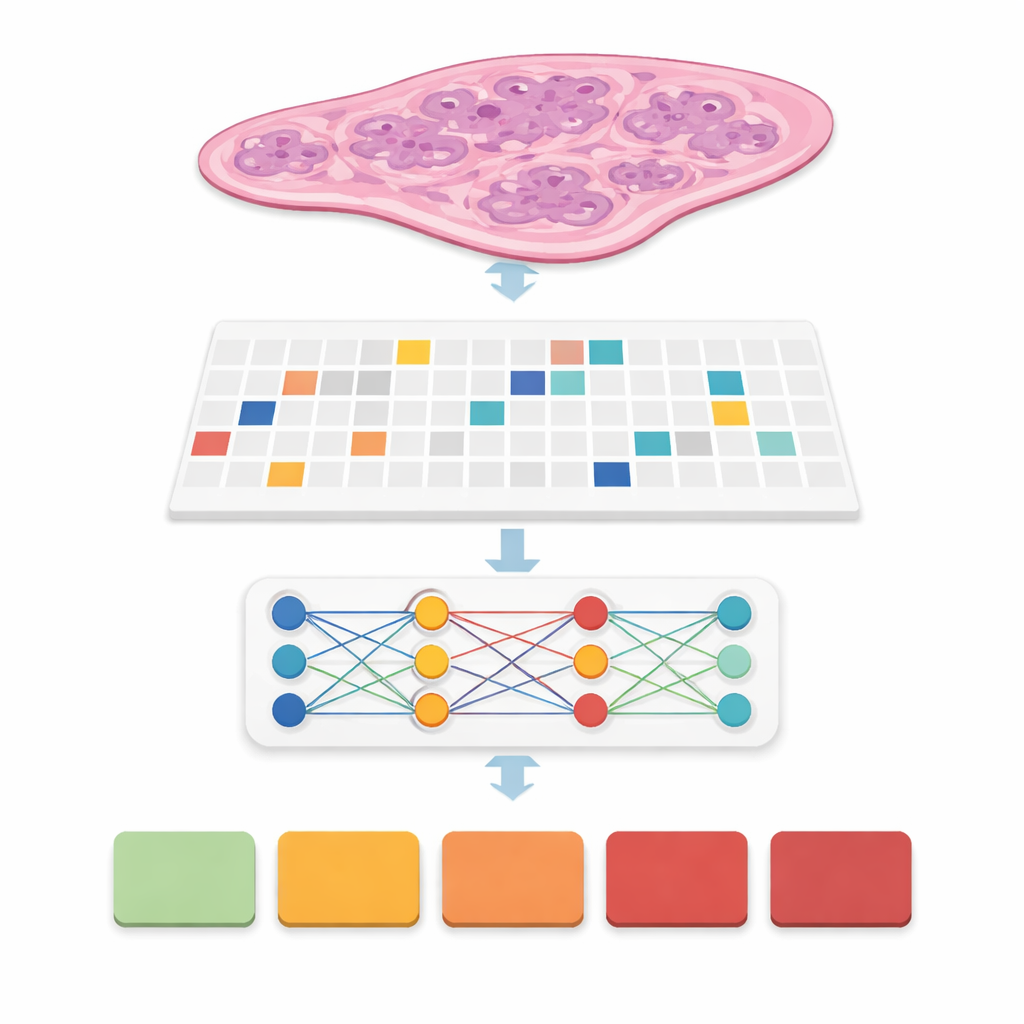
Enseñar a los ordenadores a ver el cáncer sin etiquetas píxel a píxel
En muchos sistemas previos, los expertos debían dibujar contornos precisos alrededor de cada foco canceroso, un paso que consume mucho tiempo y dificulta el despliegue en el mundo real. Aquí, el equipo usó un enfoque llamado supervisión débil: el ordenador solo ve una etiqueta a nivel de lámina, como el grupo final de gradación del cáncer de 0 (benigno) a 5 (más agresivo), sin marcas detalladas internas. Cada lámina se convierte en una "bolsa" de parches, y modelos especiales aprenden qué parches son más relevantes para predecir la gradación global. Esta familia de métodos, denominada aprendizaje por instancias múltiples, permite al sistema descubrir patrones de glándulas y células que distinguen enfermedad leve de agresiva, mientras reduce drásticamente la carga de trabajo de los patólogos durante el entrenamiento.
Comparando muchos componentes de IA cara a cara
En lugar de proponer un único modelo nuevo, los autores construyeron una evaluación comparativa cuidadosa. Combinaron seis diseños líderes de aprendizaje por instancias múltiples con tres extractores de características distintos, o "codificadores", que transforman cada parche en una huella numérica rica. Un codificador era un modelo clásico de visión entrenado con fotografías cotidianas, mientras que los otros eran grandes modelos "fundacionales" entrenados específicamente con cientos de miles de láminas de patología. Ejecutaron todas estas combinaciones bajo cuatro configuraciones de parches y cinco pliegues de validación cruzada, lo que dio lugar a 360 entrenamientos y 72 configuraciones principales. El rendimiento se midió con precisión, varios tipos de puntuaciones F y kappa ponderado cuadrático, una estadística que premia obtener una gradación de cáncer cercana a la decisión del experto incluso cuando no es exactamente igual.
Encontrar el punto óptimo: parches pequeños y solapados y un modelo fundacional de patología
El claro vencedor surgió cuando el equipo usó parches de tejido relativamente pequeños (256 por 256 píxeles) con un 50 % de solapamiento, codificados por el modelo fundacional UNI2 y agregados mediante un método de atención de bajo rango llamado ILRA‑MIL. Esta combinación alcanzó alrededor del 79 % de precisión y un kappa ponderado cuadrático muy alto de poco más de 0,90, acercándose a los niveles de acuerdo observados entre expertos en el desafío PANDA original. Los parches más pequeños y solapados dieron al modelo tanto detalle celular fino como contexto suficiente, mientras que el codificador específico de patología superó claramente a la red genérica entrenada con fotos en 15–20 puntos porcentuales de precisión. De forma importante, los autores mostraron que estas mejoras son alcanzables con recursos en la nube accesibles, usando computación distribuida en plataformas públicas en lugar de costosos clústeres dedicados. 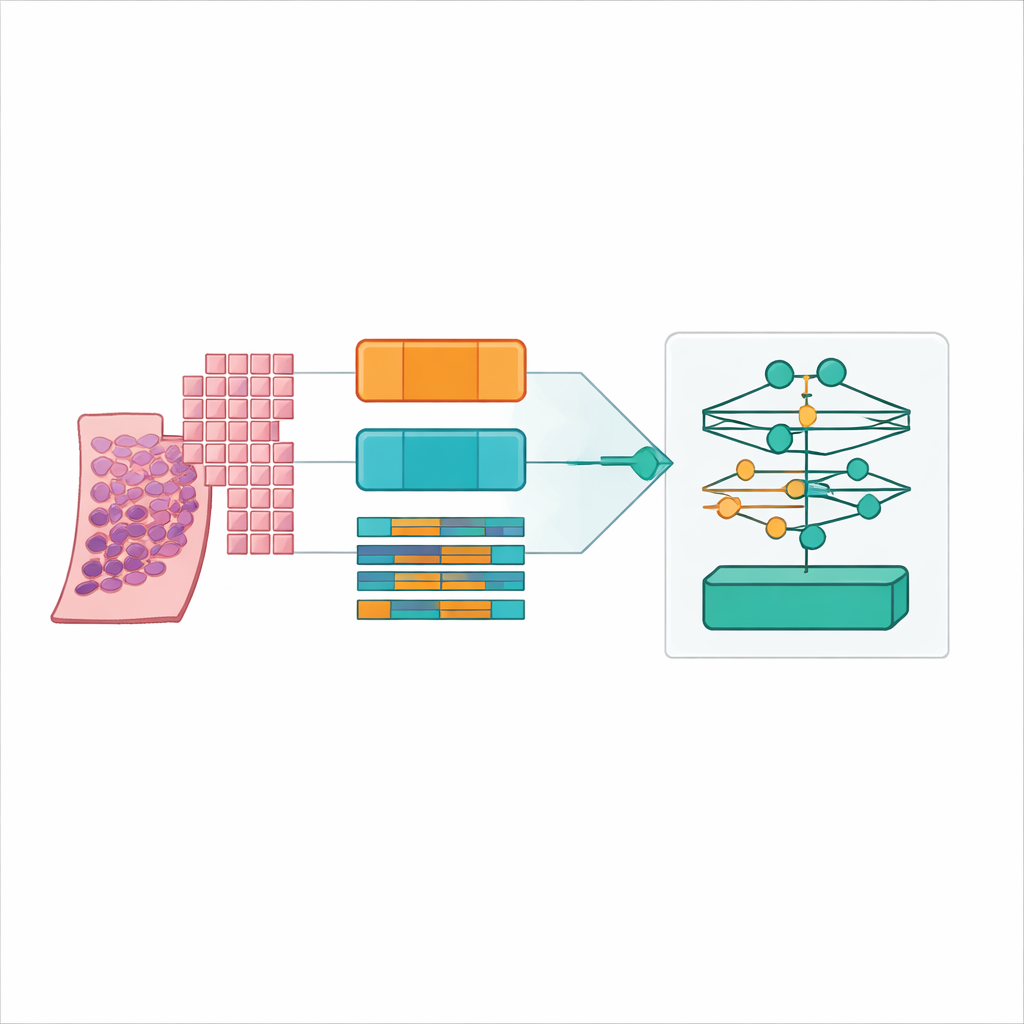
Hacer visibles las decisiones de la IA para los patólogos
Para cualquier herramienta que pueda influir en el tratamiento, no basta con ser precisa; los médicos necesitan entender por qué realiza una decisión concreta. Los investigadores incorporaron mapas de atención y mapas de calor Grad‑CAM que resaltan qué regiones de la lámina impulsaron la predicción. Estas explicaciones visuales pueden superponerse a la imagen del tejido para que un patólogo confirme que el modelo realmente se centra en glándulas cancerosas o en patrones agresivos en lugar de ruido o estructuras benignas. Esta atención a la interpretabilidad, combinada con una interfaz web y un flujo de trabajo completamente descrito desde la lámina cruda hasta la predicción, está pensada para facilitar la adopción y la validación independiente en laboratorios clínicos.
Qué supone esto para la futura atención del cáncer de próstata
En términos sencillos, el estudio demuestra que un sistema de IA cuidadosamente diseñado puede graduar el cáncer de próstata en láminas digitales con un rendimiento cercano al de patólogos especialistas, sin exigir un trazado manual exhaustivo en cada lámina de entrenamiento. La receta más eficaz emplea muchos azulejos de imagen pequeños y solapados y un gran codificador entrenado en patología que alimenta un modelo basado en atención capaz de señalar el tejido en el que se apoyó. Aunque el trabajo aún depende de un único conjunto de datos importante y necesita pruebas más amplias entre hospitales, ofrece una vía realista hacia diagnósticos de cáncer de próstata más rápidos, consistentes y disponibles de forma más amplia, especialmente en regiones con escasez de patólogos expertos.
Cita: Butt, N.A., Sarwat, D., Noya, I.D. et al. Benchmarking multiple instance learning architectures from patches to pathology for prostate cancer detection and grading using attention-based weak supervision. Sci Rep 16, 11535 (2026). https://doi.org/10.1038/s41598-026-39196-x
Palabras clave: cáncer de próstata, patología digital, aprendizaje con supervisión débil, aprendizaje por instancias múltiples, patología computacional