Clear Sky Science · de
Benchmarking mehrerer Multiple-Instance-Learning-Architekturen von Patches bis Pathologie zur Erkennung und Einstufung von Prostatakrebs mit auf Aufmerksamkeit basierender schwacher Überwachung
Warum das für Patientinnen, Patienten und Ärztinnen und Ärzte wichtig ist
Prostatakrebs zählt zu den häufigsten Krebserkrankungen bei Männern; die Einstufung der Schwere anhand von Mikroskopiepräparaten beeinflusst die Therapieentscheidungen unmittelbar. Heute ist diese Begutachtung zeitaufwendig, kann zwischen Pathologinnen und Pathologen variieren und ist bei alternden Bevölkerungen schwer zu skalieren. Diese Studie zeigt, wie moderne Künstliche Intelligenz lernen kann, die Tumor‑Schwere auf digitalen Schnitten mit deutlich weniger manuellen Markierungen als bisher zu bestimmen, und dabei weiterhin für Ärztinnen und Ärzte nachvollziehbar bleibt. Das macht den Ansatz zu einem realistischen Kandidaten, um alltägliche Diagnosen in Krankenhäusern zu unterstützen und nicht nur Laborforschung zu sein.
Von riesigen Schnitten zu winzigen Bildkacheln
Moderne Scanner verwandeln eine dünne Gewebeschicht der Prostata in ein riesiges digitales Bild, oft 20.000 mal 20.000 Pixel groß. Ein großer Teil davon ist Hintergrund, und selbst das relevante Gewebe ist zu umfangreich, um es auf einmal in ein übliches Computermodell einzuspeisen. Die Forschenden lösten das, indem sie jeden ganzen Schnitt in viele kleine quadratische „Patches“ zerschnitten haben, wie ein Poster in ein Puzzle. Sie erkannten gezielt die tatsächlichen Geweberegionen, filterten leere Flächen und Artefakte aus und erzeugten Koordinatenkarten, die dem Rechner genau sagen, wo Proben zu entnehmen sind. Es wurden vier Patch‑Strategien getestet — mit verschiedenen Größen und mit oder ohne Überlappung — und am Ende mehr als 31 Millionen Patches aus über 10.600 Schnitten eines großen öffentlichen Prostatakrebsdatensatzes namens PANDA erzeugt. 
Computern Krebs beibringen, ohne Pixel-für-Pixel-Labels
In vielen früheren Systemen mussten Expertinnen und Experten präzise Umrisse um jeden Krebsherd zeichnen — ein zeitraubender Schritt, der den Einsatz in der Praxis erschwert. Das Team verwendete hier einen Ansatz namens schwache Überwachung: Der Computer sieht nur ein Slide‑Level‑Label, etwa die finale Grade‑Group des Tumors von 0 (benigne) bis 5 (am aggressivsten), ohne detaillierte Markierungen innerhalb des Schnitts. Jeder Schnitt wird so zu einer „Tasche“ von Patches, und spezielle Modelle lernen, welche Patches für die Vorhersage der Gesamtbewertung wichtig sind. Diese Methodenfamilie, Multiple‑Instance‑Learning genannt, erlaubt es dem System, Muster von Drüsen und Zellen zu entdecken, die leicht von aggressivem Befund unterscheiden, und reduziert gleichzeitig den Arbeitsaufwand für Pathologinnen und Pathologen während des Trainings deutlich.
Viele KI-Bausteine direkt vergleichen
Anstatt nur ein neues Modell vorzuschlagen, bauten die Autorinnen und Autoren ein sorgfältiges Benchmark auf. Sie kombinierten sechs führende Multiple‑Instance‑Learning‑Designs mit drei verschiedenen Feature‑Extraktoren, sogenannten „Encodern“, die jeden Patch in einen dichten numerischen Fingerabdruck überführen. Ein Encoder war ein klassisches Vision‑Modell, das auf Alltagsfotos trainiert wurde, während die anderen große „Foundation“-Modelle waren, die speziell auf Hunderttausenden von Pathologie‑Schnitten trainiert worden sind. Alle Kombinationen wurden unter vier Patch‑Einstellungen und fünf Kreuzvalidierungs‑Folds ausgeführt, was 360 Trainingsläufe und 72 Kernkonfigurationen ergab. Die Leistung wurde mit Genauigkeit, mehreren F‑Scores und dem quadratisch gewichteten Kappa gemessen — einer Statistik, die belohnt, wenn die vorhergesagte Tumorklasse nah an der Expertenentscheidung liegt, auch wenn sie nicht exakt übereinstimmt.
Den Sweet Spot finden: kleine überlappende Patches und ein Pathologie‑Foundation‑Model
Der klare Gewinner trat zutage, als das Team relativ kleine Gewebepatches (256 × 256 Pixel) mit 50‑prozentiger Überlappung verwendete, kodiert durch das UNI2‑Foundation‑Model und aggregiert durch eine niedrig‑rangige Aufmerksamkeitsmethode namens ILRA‑MIL. Diese Kombination erreichte rund 79 Prozent Genauigkeit und ein sehr hohes quadratisch gewichtetes Kappa von knapp über 0,90, was an die Übereinstimmungsniveaus zwischen menschlichen Expertinnen und Experten in der ursprünglichen PANDA‑Challenge heranreicht. Kleinere, überlappende Patches lieferten sowohl feine zelluläre Details als auch genügend Kontext, während der pathologiespezifische Encoder das generische, auf Fotos trainierte Netzwerk in der Genauigkeit klar um 15–20 Prozentpunkte übertraf. Wichtig ist, dass die Autorinnen und Autoren zeigten, dass diese Verbesserungen mit zugänglichen Cloud‑Ressourcen erreichbar sind, indem verteiltes Rechnen auf öffentlichen Plattformen statt teurer dedizierter Cluster verwendet wurde. 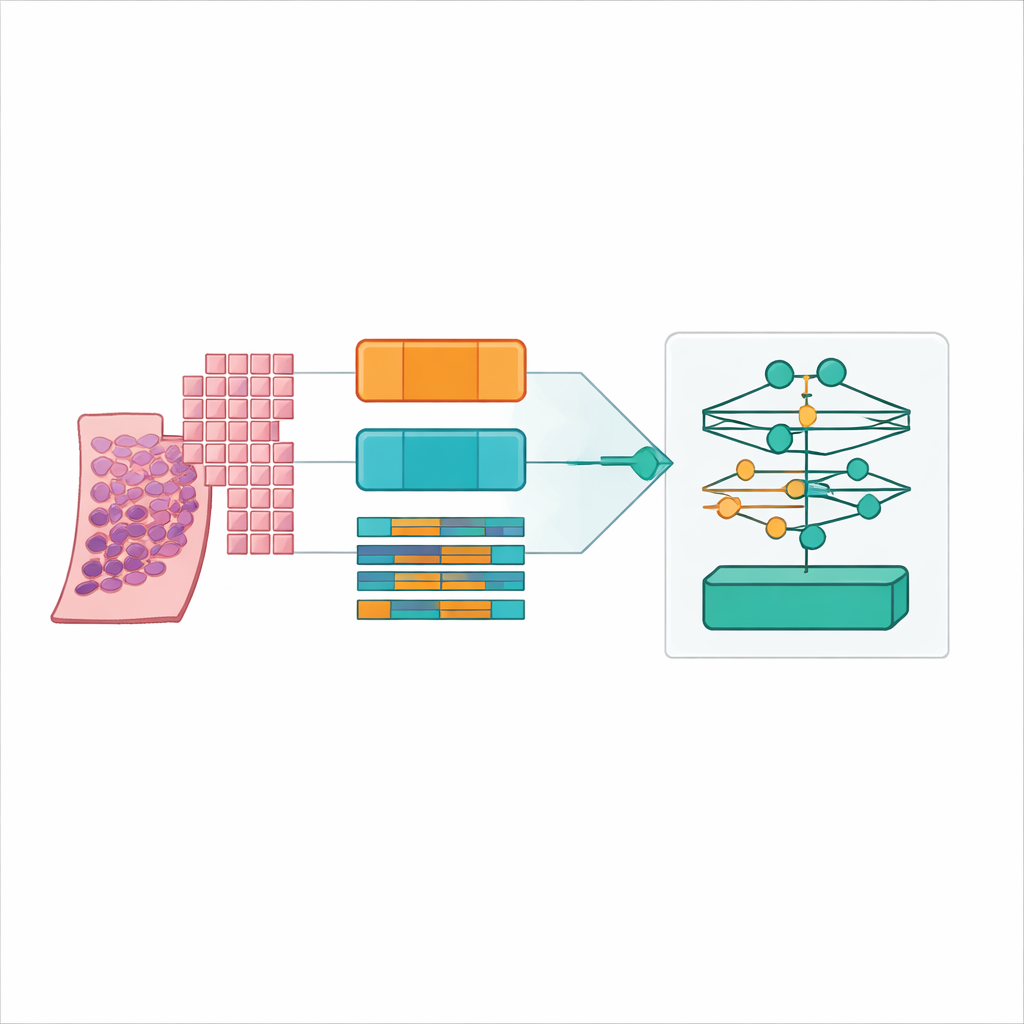
KI‑Entscheidungen für Pathologinnen und Pathologen sichtbar machen
Für jedes Werkzeug, das Behandlungsentscheidungen beeinflussen könnte, reicht es nicht aus, nur korrekt zu sein; Ärztinnen und Ärzte müssen verstehen, warum eine bestimmte Entscheidung getroffen wurde. Die Forschenden integrierten Aufmerksamkeitskarten und Grad‑CAM‑Heatmaps, die die Regionen eines Schnitts hervorheben, die die Vorhersage getrieben haben. Diese visuellen Erklärungen können über das Gewebebild gelegt werden, sodass eine Pathologin oder ein Pathologe bestätigen kann, dass das Modell wirklich auf krebsartige Drüsen oder aggressive Muster statt auf Rauschen oder gutartige Strukturen achtet. Diese Betonung der Interpretierbarkeit, kombiniert mit einer webbasierten Schnittstelle und einem vollständig beschriebenen Workflow vom Rohschnitt bis zur Vorhersage, soll die Einführung und unabhängige Validierung in klinischen Laboren erleichtern.
Was das für die zukünftige Prostatakrebsversorgung bedeutet
Kurz gesagt zeigt die Studie, dass ein sorgfältig gestaltetes KI‑System Prostatakrebs auf digitalen Schnitten mit einer Leistung einstufen kann, die der von spezialisierten Pathologinnen und Pathologen nahekommt, ohne dass auf jedem Trainingsschnitt aufwändige manuelle Umrisse nötig sind. Das effektivste Rezept nutzt viele kleine, überlappende Bildkacheln und einen großen, auf Pathologie trainierten Encoder, der in ein auf Aufmerksamkeit basierendes Modell eingespeist wird, das zurück auf das Gewebe verweisen kann, auf das es sich stützte. Zwar beruht die Arbeit noch auf einem einzigen großen Datensatz und es bedarf weiterreichender Tests zwischen Krankenhäusern, doch sie bietet einen realistischen Weg zu schnelleren, konsistenteren und breiter verfügbaren Prostatakrebsdiagnosen — insbesondere in Regionen mit wenig Expertise an Pathologinnen und Pathologen.
Zitation: Butt, N.A., Sarwat, D., Noya, I.D. et al. Benchmarking multiple instance learning architectures from patches to pathology for prostate cancer detection and grading using attention-based weak supervision. Sci Rep 16, 11535 (2026). https://doi.org/10.1038/s41598-026-39196-x
Schlüsselwörter: Prostatakrebs, digitale Pathologie, schwach überwachte Lernverfahren, Multiple-Instance-Learning, computationale Pathologie