Clear Sky Science · zh
通过消息传递剪枝和图划分实现可扩展的原子间基础势
为什么更快的原子“电影”很重要
我们关心的许多技术,从更好的电池到更清洁的催化剂,都依赖于原子在长时间尺度和大量颗粒上的行为。计算模拟可以生成这些原子运动的“电影”,但最精确的方法太慢,常常只能处理极小的体系和非常短的时间。本论文提出了一种方法,在保留现代人工智能原子模型高精度的同时大幅降低其成本,使得在当今图形处理器上进行百万原子、纳秒尺度的模拟变得可行。 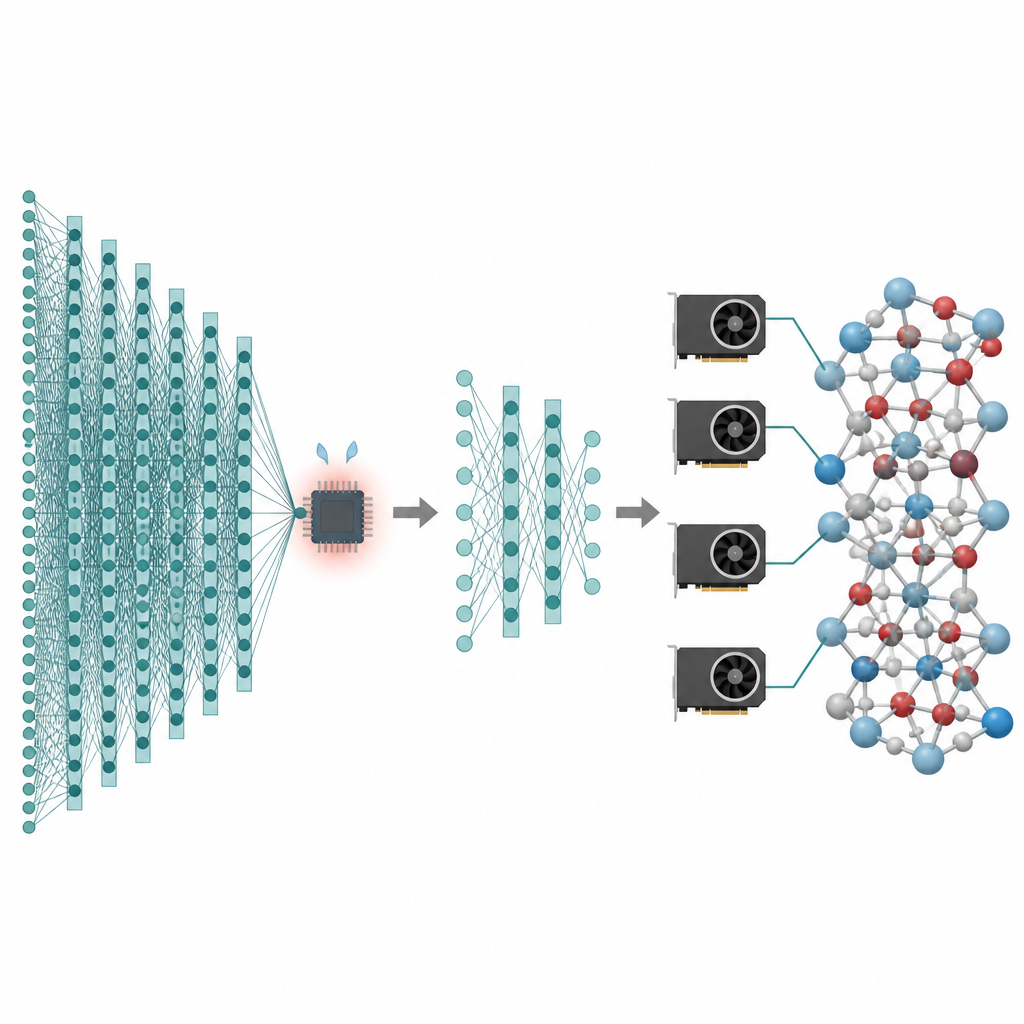
从量子精度到实用极限
在一端,基于量子的方法能够非常详尽地描述原子相互作用,但对于大而真实的体系来说太慢。为弥合这一差距,研究者转向机器学习模型,这些模型从量子数据中学习原子间的推拉作用,并用快速预测替代昂贵的计算。该领域最近的一个飞跃是“原子基础模型”的出现,指经大量多样原子结构训练的大型神经网络。这些模型仅需少量新数据即可微调,并且在精度上常常能匹配或超过许多专门构建的模型,使其成为材料科学的通用工具。
当更大的模型成为负担时
这些基础模型的强大之处同时也是它们的弱点。为了覆盖多种元素和键合环境,它们依赖深层的“消息传递”网络,在相邻原子之间反复交换信息。每增加一层都能让原子感知更广的邻域,但也会膨胀模型体积和内存使用。因此,这些模型比更简单的机器学习势运行慢得多,且难以处理远超几万原子的结构。对于需要研究稀有事件、缓慢扩散或复杂相变的科学家而言,这一性能墙使得强大模型变成了小众工具。作者的目标是在保留基础模型优势的同时剥离不必要的开销。
在不丧失能力的前提下修剪神经网络
所提出工作流的第一步称为消息传递深度剪枝。团队分析了若干流行原子基础模型中每一层对原子内部描述实际产生的变化量。他们观察到一种“过度平滑”效应:在早期层完成大部分工作的情况下,后续层仅做微小且重复的调整。基于此,他们保留前几层并移除其余层,然后在特定任务数据上对缩短后的模型进行微调。在磷酸锂玻璃、混合硅-二氧化硅体系以及氧化物支撑金属粒子的测试中,即便只保留一到两层的模型,也能达到几乎与完整网络相当的精度,同时更轻、更快。 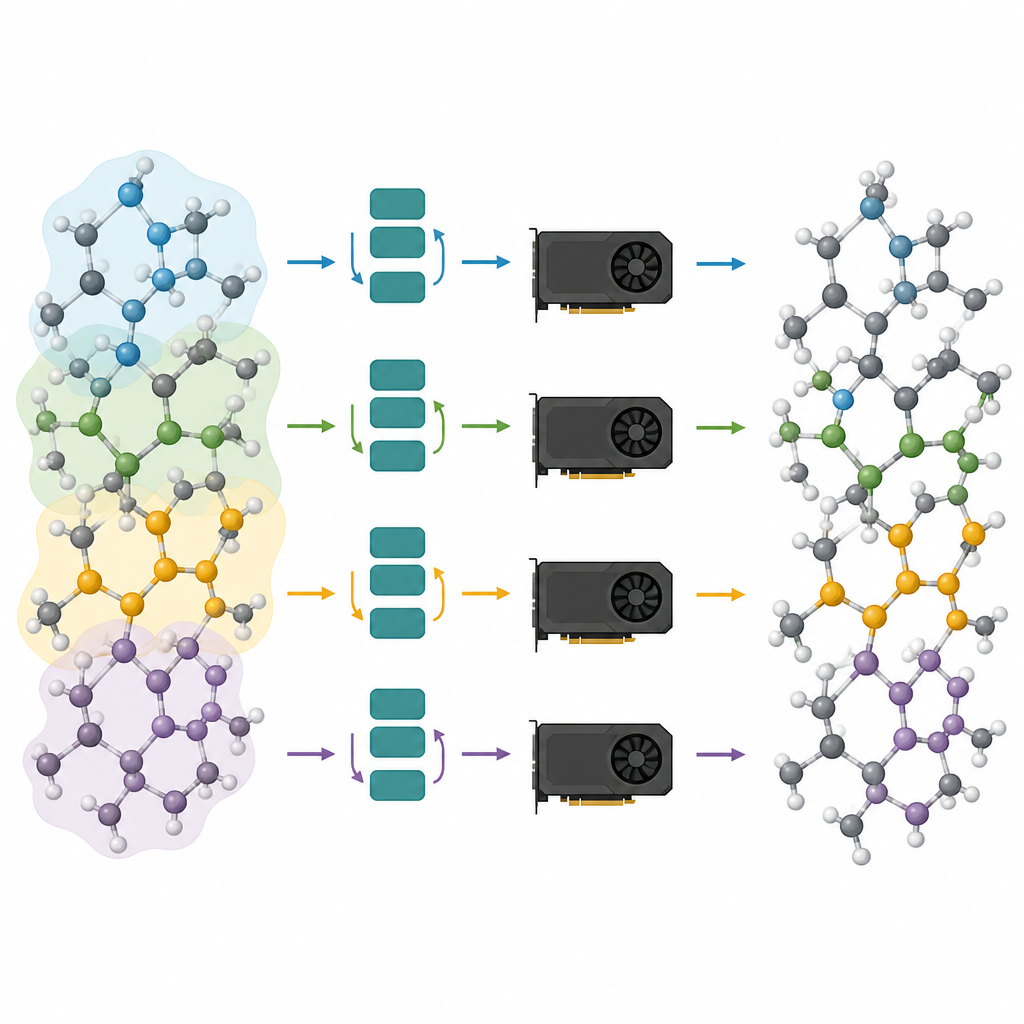
将大型原子体系分配到多块芯片上
剪枝模型只是解决方案的一半;另一半是如何在现代图形处理器上高效运行它们。作者将原子体系视为一个图,原子为节点,键或近邻为连边。他们将该图划分为重叠的子块,每个子块包含所需消息传递步数范围内的所有邻居,并将这些子图分配给不同的图形处理器。由于模型变浅,所需邻域较小,每个子块中附加的原子数量保持可控。关键在于,每个处理器可以独立运行其子块,在计算密集阶段无需通信,然后再将结果拼接起来。这种“环带”式划分使得该方法无论在单卡还是多卡并行情况下都适用。
这些新工具能实现什么
通过将剪枝与图划分相结合,作者在速度和规模上取得了巨大提升。他们演示了在标准硬件上可实现百万原子模拟,甚至超过五百万原子的体系,同时保持基础模型提供的可信力和结构。在实际案例研究中,剪枝模型再现了无定形磷酸锂的形成、硅-二氧化硅玻璃中的纳米尺度分离,以及铂纳米粒子被缺陷氧化物表面逐步包裹的过程。对非专业读者而言,结论很明确:这项工作把先前缓慢且占用大量内存的原子 AI,转变为能够驱动真实材料模拟的高效引擎,为在复杂器件和材料上进行常规虚拟实验打开了大门。
引用: Kong, L., Shim, J., Hu, G. et al. Scalable foundation interatomic potentials via message-passing pruning and graph partitioning. npj Comput Mater 12, 180 (2026). https://doi.org/10.1038/s41524-026-02001-4
关键词: 原子基础模型, 分子动力学, 图神经网络, GPU 加速, 材料模拟