Clear Sky Science · nl
Schaalbare fundamentele interatomaire potentialen via message-passing pruning en grafpartitionering
Waarom snellere atomaire "films" ertoe doen
Veel van de technologieën die ons aangaan, van betere batterijen tot schonere katalysatoren, hangen af van wat atomen doen over lange tijden en in enorme aantallen deeltjes. Computersimulaties kunnen zulke atomen in beweging als "films" maken, maar de meest nauwkeurige methoden zijn zo traag dat ze vaak vastlopen bij zeer kleine systemen en korte tijden. Dit artikel presenteert een manier om de hoge nauwkeurigheid van moderne kunstmatige-intelligentie modellen voor atomen te behouden, terwijl de kosten zo ver worden verlaagd dat simulaties met miljoenen atomen en nanoseconden aan tijd praktisch uitvoerbaar worden op hedendaagse grafische processors. 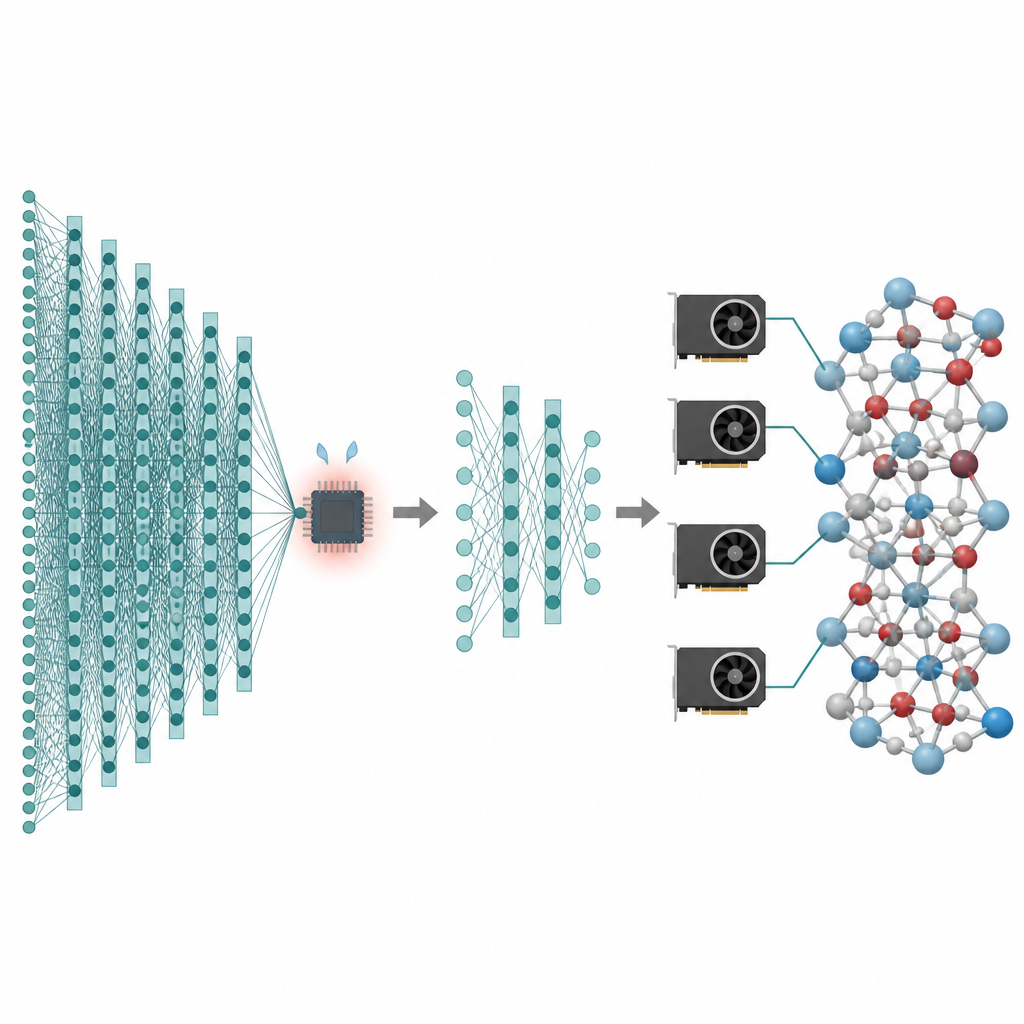
Van kwantumnauwkeurigheid naar praktische grenzen
Aan het ene uiterste beschrijven kwantumgebaseerde methoden atomaire interacties met grote detailnauwkeurigheid, maar ze zijn veel te traag voor grote, realistische systemen. Om deze kloof te overbruggen, zijn onderzoekers overgestapt op machine-learningmodellen die van kwantumgegevens leren hoe atomen op elkaar inwerken, en vervolgens dure berekeningen vervangen door snelle voorspellingen. Een recente doorbraak in dit veld is de opkomst van “atomistische fundatiemodellen”, grote neurale netwerken die zijn getraind op uitgestrekte en gevarieerde verzamelingen atomische structuren. Deze modellen kunnen met slechts een kleine hoeveelheid nieuwe data worden fijnafgesteld en halen toch vaak de nauwkeurigheid van of overtreffen veel op maat gemaakte modellen, wat ze aantrekkelijk maakt als algemene hulpmiddelen voor materiaalwetenschap.
Wanneer grotere modellen een last worden
De kracht van deze fundatiemodellen is ook hun zwakte. Om veel elementen en bindingsomgevingen te dekken, vertrouwen ze op diepe "message-passing" netwerken die herhaaldelijk informatie uitwisselen tussen naburige atomen. Elke extra laag helpt atomen een groter gebied om zich heen waar te nemen, maar vergroot ook de modelgrootte en het geheugengebruik. Daardoor draaien deze modellen veel trager dan eenvoudigere machine-learning potentialen en kunnen ze niet gemakkelijk structuren aan die veel verder gaan dan tienduizenden atomen. Voor wetenschappers die zeldzame gebeurtenissen, trage diffusie of complexe faseovergangen willen bestuderen, verandert deze prestatielimiet krachtige modellen in niche-instrumenten. De auteurs streven ernaar de voordelen van fundatiemodellen te behouden en tegelijkertijd onnodige kosten te schrappen.
Het neural netwerk trimmen zonder vaardigheden te verliezen
De eerste stap in de voorgestelde workflow heet pruning van de message-passing-diepte. Het team analyseerde hoeveel elke laag in verschillende populaire atomistische fundatiemodellen de interne beschrijving van atomen daadwerkelijk verandert. Ze observeerden een "oversmoothing"-effect: nadat de vroege lagen het grootste deel van het werk hebben gedaan, brengen latere lagen slechts kleine, repetitieve aanpassingen aan. Hierop inspelend, houden ze eenvoudigweg de eerste paar lagen en verwijderen de rest, en fijnregelen vervolgens het verkorte model op taak-specifieke data. Tests op lithiumfosfaatglas, gemengde silicium–silica systemen en metaaldeeltjes op oxide-ondersteuningen tonen aan dat zelfs modellen met slechts één of twee overgebleven lagen bijna dezelfde nauwkeurigheid als de volledige netwerken kunnen bereiken, terwijl ze veel lichter en sneller zijn. 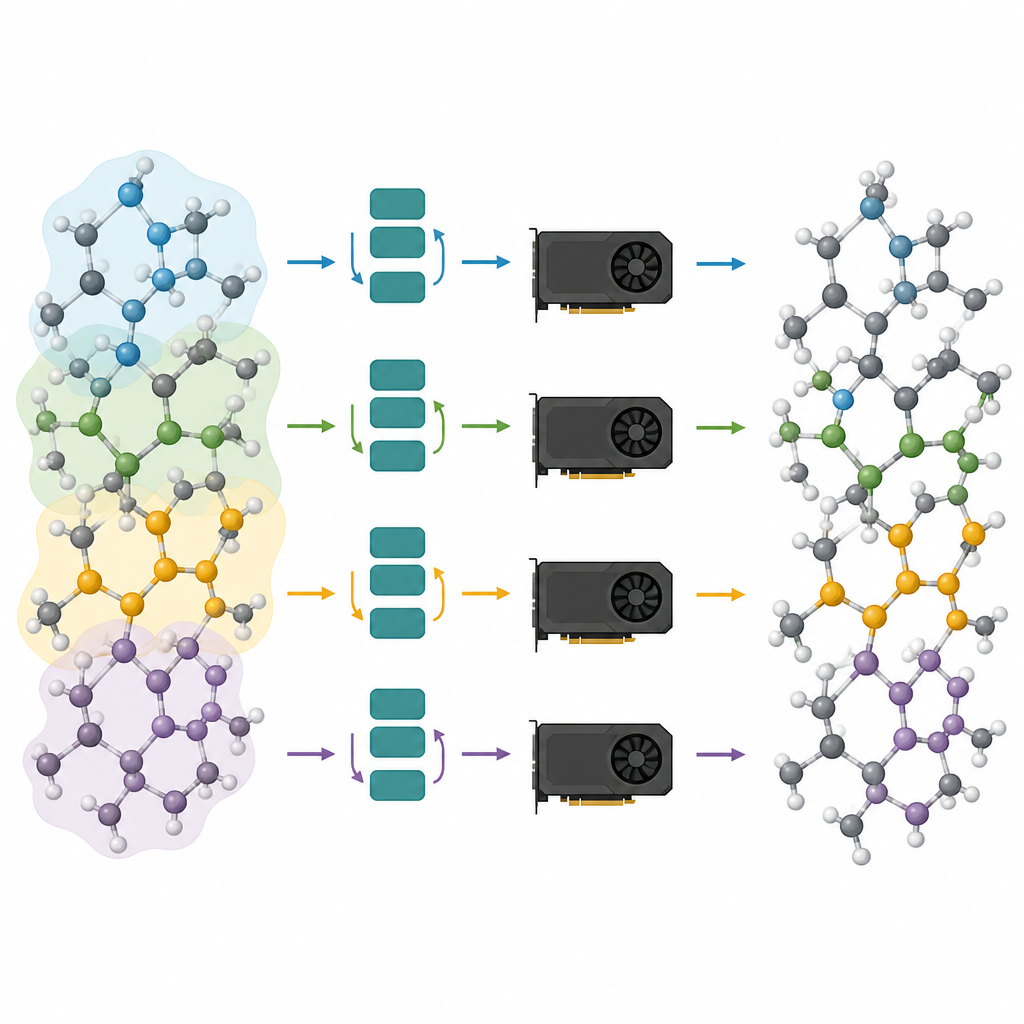
Grote atomaire systemen over meerdere chips verdelen
Gesnoeide modellen zijn slechts de helft van de oplossing; de andere helft is ze efficiënt laten draaien op moderne grafische processors. De auteurs zien een atomair systeem als een graaf, waarbij atomen knopen zijn en bindingen of naburige relaties links vormen. Ze partitioneren deze graaf in overlappende stukken, elk met alle buren die nodig zijn voor een gekozen aantal message-passing-stappen, en wijzen deze subgrafen toe aan verschillende grafische processors. Omdat het model nu ondiep is, is de benodigde buurtruimte klein en blijven de extra atomen in elk deel beheersbaar. Cruciaal is dat elke processor zijn deel onafhankelijk kan uitvoeren, zonder te hoeven communiceren tijdens de zware berekening, waarna de resultaten worden samengevoegd. Deze halo-achtige partitionering laat dezelfde methode werken, ongeacht of er één grafische kaart of meerdere parallel werkende kaarten zijn.
Wat de nieuwe tools mogelijk maken
Door pruning te combineren met grafpartitionering boeken de auteurs grote winst in snelheid en schaal. Ze tonen aan dat simulaties met miljoenen atomen en zelfs systemen met meer dan vijf miljoen atomen haalbaar zijn op standaardhardware, terwijl de betrouwbare krachten en structuren die fundatiemodellen bieden behouden blijven. In praktische casestudies reproduceren de gesnoeide modellen de vorming van amorf lithiumfosfaat, nanoschaalse scheiding in silicium–silica glazen en de geleidelijke omsluiting van een platina-nanodeeltje door een defecte oxide-oppervlakte. Voor niet-specialisten is de boodschap duidelijk: dit werk verandert voorheen trage, geheugenhongerige atomaire AI's in slanke motoren die realistische materialensimulaties kunnen aandrijven, en opent de deur naar routinematige virtuele experimenten op complexe apparaten en materialen.
Bronvermelding: Kong, L., Shim, J., Hu, G. et al. Scalable foundation interatomic potentials via message-passing pruning and graph partitioning. npj Comput Mater 12, 180 (2026). https://doi.org/10.1038/s41524-026-02001-4
Trefwoorden: atomistische fundatiemodellen, moleculaire dynamica, grafneurale netwerken, GPU-versnelling, materialensimulatie