Clear Sky Science · ja
メッセージ伝播剪定とグラフ分割によるスケーラブルな原子間基盤ポテンシャル
なぜ高速な原子の“映画”が重要か
より優れた電池やよりクリーンな触媒など、私たちが関心を寄せる多くの技術は、長時間にわたる多数の粒子中で原子がどう振る舞うかに依存しています。コンピュータシミュレーションはこれらの原子の「映画」を作成できますが、最も正確な手法は極めて遅く、しばしば非常に小さな系と非常に短い時間スケールで行き詰まります。本論文は、原子向けの現代的な人工知能モデルの高い精度を保ちながら、そのコストを大幅に削減し、今日のグラフィックスプロセッサ上で百万原子、ナノ秒スケールのシミュレーションを実用にする方法を示します。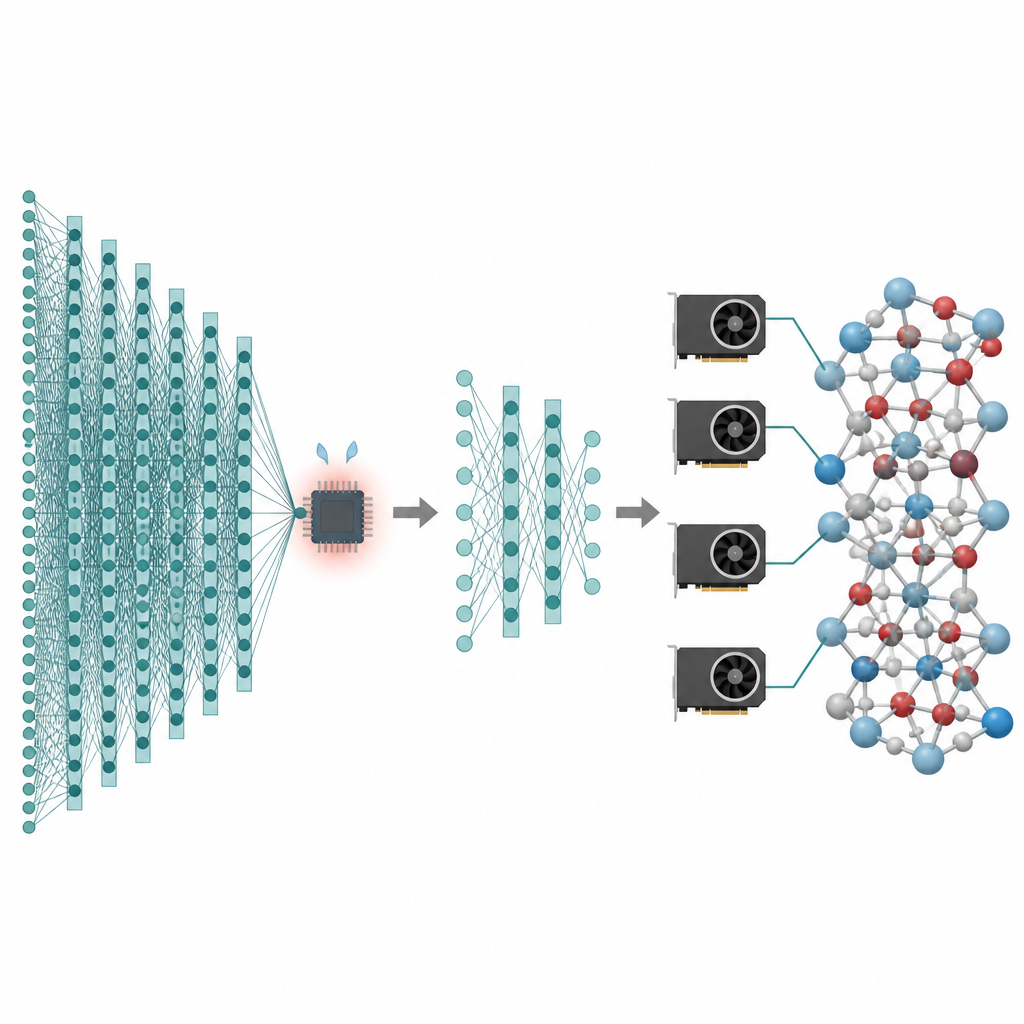
量子精度から実用限界へ
一方の極では、量子に基づく手法は原子間相互作用を詳細に記述しますが、大きく現実的な系にはあまりに遅すぎます。このギャップを埋めるために、研究者たちは量子データから原子が互いにどのように力を及ぼし合うかを学習し、高価な計算を高速な予測で置き換える機械学習モデルに注目してきました。この分野での最近の飛躍は「原子基盤モデル」の台頭です。これは多様な原子構造の大規模なデータに対して訓練された大規模ニューラルネットワークであり、少量の新しいデータでファインチューニングするだけで多くの専用モデルと同等またはそれ以上の精度を示すため、材料科学の汎用ツールとして魅力的です。
大きなモデルが負担になるとき
これら基盤モデルの強みは同時に弱点でもあります。多くの元素や結合環境をカバーするために、隣接原子間で情報を繰り返し交換する深い「メッセージ伝播」ネットワークを利用しています。層を増やすごとに原子はより広い領域を感知できるようになりますが、モデルのサイズとメモリ使用量も膨らみます。その結果、これらのモデルはより単純な機械学習ポテンシャルよりはるかに遅く動作し、数万原子を超える構造を扱うのは容易ではありません。希少事象、遅い拡散、複雑な相変化を研究する科学者にとって、この性能上の壁は強力なモデルをニッチな道具にしてしまいます。著者らの目標は、基盤モデルの利点を保持しつつ不要なコストを削ぎ落とすことです。
性能を損なわずにニューラルネットワークを削る
提案ワークフローの最初のステップはメッセージ伝播深さの剪定と呼ばれます。チームは複数の代表的な原子基盤モデルの各層が原子の内部表現をどれだけ変化させるかを解析しました。その結果「過度の平滑化(オーバースムージング)」効果が観察されました:初期の層が大部分の仕事を終えた後、後続の層はわずかで反復的な調整しか行わない、というものです。これを利用して彼らは単純に最初の数層だけを残して残りを削除し、短縮したモデルをタスク固有のデータでファインチューニングしました。リン酸リチウムガラス、混合シリコン–シリカ系、酸化物支持体上の金属粒子でのテストでは、残存層が1〜2層のモデルでも完全なネットワークとほぼ同等の精度に達し、より軽量で高速であることが示されました。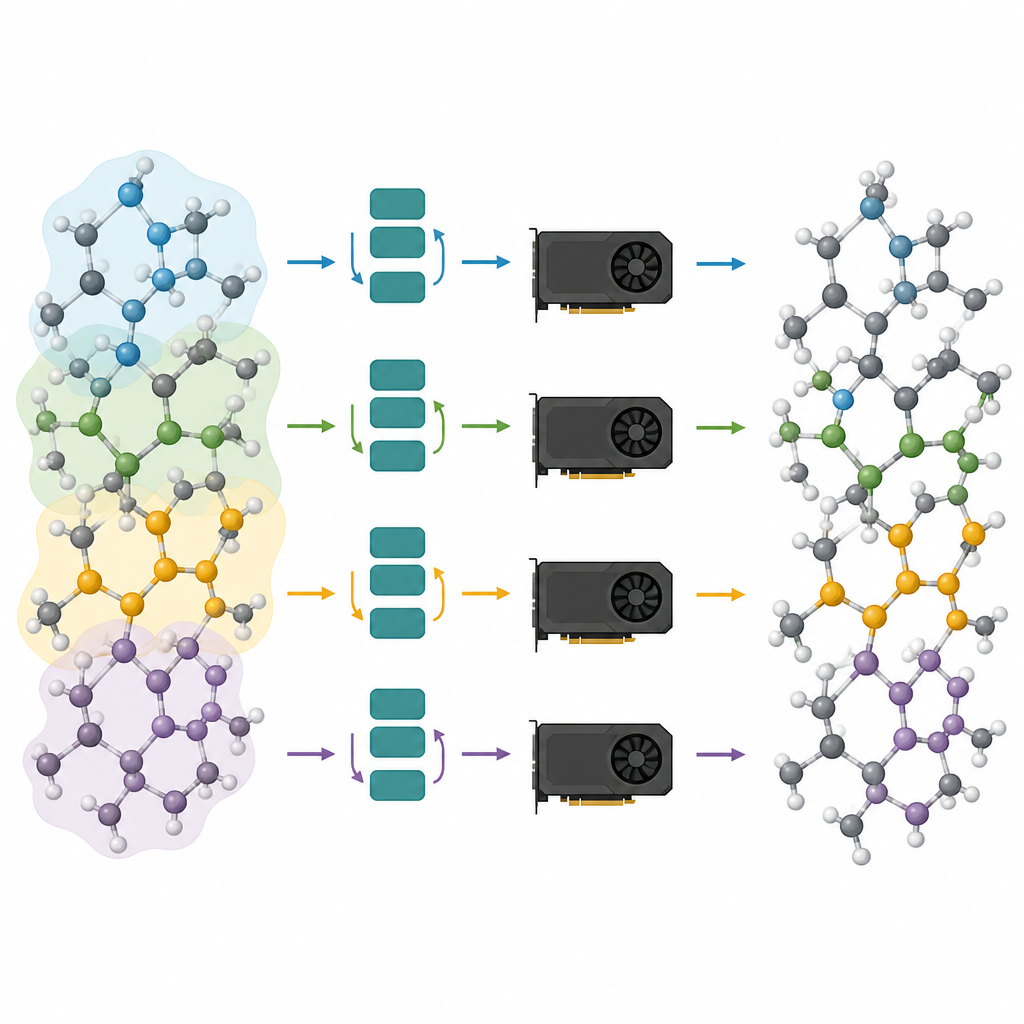
大きな原子系を多数のチップに分割する
剪定モデルは解法の半分にすぎません。残りの半分はそれらを現代のグラフィックスプロセッサ上で効率的に動かすことです。著者らは原子系を、原子をノード、結合や近傍をリンクとするグラフとして捉えます。このグラフを、選択したメッセージ伝播のステップ数に必要なすべての近傍を含む重なり合う部分に分割し、これらの部分グラフを異なるGPUに割り当てます。モデルが浅くなったため必要な近傍は小さくなり、各部分に含まれる追加原子数は管理可能なままです。重要なのは、各プロセッサが重い計算中に通信を必要とせずに独立して自分の部分を実行でき、結果を後で縫い合わせることができる点です。この“ハロー”スタイルの分割により、単一のグラフィックスカードでも複数並列でも同じ手法が機能します。
新しい手法で何が可能になるか
剪定とグラフ分割を組み合わせることで、著者らは速度と規模の大幅な向上を達成しました。彼らは百万原子のシミュレーション、さらには500万原子を超える系でも標準的なハードウェアで実行可能であり、基盤モデルが提供する信頼できる力と構造を維持できることを実証しました。実用的な事例研究では、剪定モデルがリン酸リチウムのアモルファス形成、シリコン–シリカガラスのナノスケール分離、欠陥酸化物表面による白金ナノ粒子の徐々な被覆再現を再現しました。専門外の読者にとっての結論は明白です:本研究は従来は遅くメモリを大量に消費していた原子向けAIを引き締まったエンジンに変え、現実的な材料シミュレーションを駆動することで複雑なデバイスや材料の仮想実験を日常的に行える道を開きます。
引用: Kong, L., Shim, J., Hu, G. et al. Scalable foundation interatomic potentials via message-passing pruning and graph partitioning. npj Comput Mater 12, 180 (2026). https://doi.org/10.1038/s41524-026-02001-4
キーワード: 原子基盤モデル, 分子動力学, グラフニューラルネットワーク, GPUアクセラレーション, 材料シミュレーション