Clear Sky Science · pl
Skalowalne podstawowe potencjały międzyatomowe przez przycinanie przekazywania komunikatów i partycjonowanie grafu
Dlaczego szybsze atomowe filmy mają znaczenie
Wiele technologii, na których nam zależy — od lepszych baterii po czystsze katalizatory — zależy od tego, co robią atomy przez długie czasy i w ogromnych zbiorach cząstek. Symulacje komputerowe mogą tworzyć „filmy” pokazujące ruch atomów, ale najdokładniejsze metody są tak wolne, że zwykle utkną na bardzo małych układach i krótkich skalach czasowych. W artykule przedstawiono sposób zachowania wysokiej dokładności współczesnych modeli sztucznej inteligencji dla atomów przy jednoczesnym obniżeniu kosztu tak bardzo, że stają się praktyczne symulacje milionów atomów trwające nanosekundy na współczesnych procesorach graficznych. 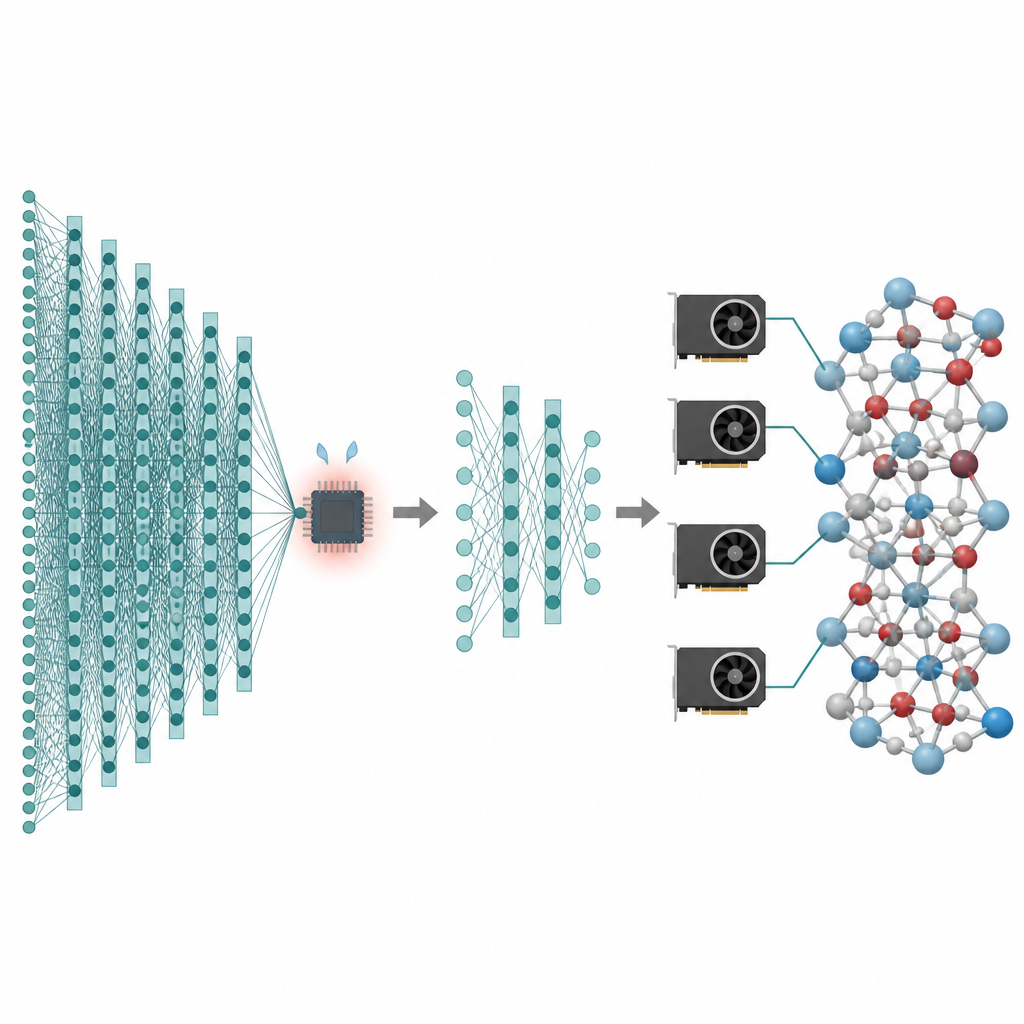
Od dokładności kwantowej do praktycznych granic
Na jednym biegunie metody oparte na mechanice kwantowej opisują interakcje atomowe z dużą szczegółowością, ale są zdecydowanie zbyt wolne dla dużych, realistycznych układów. Aby zapełnić tę lukę, badacze sięgnęli po modele uczenia maszynowego, które uczą się, jak atomy oddziałują, na podstawie danych kwantowych, i zastępują kosztowne obliczenia szybkimi przewidywaniami. Ostatnim dużym krokiem w tej dziedzinie jest pojawienie się „atomistycznych modeli bazowych” — dużych sieci neuronowych trenowanych na rozległych i zróżnicowanych zbiorach struktur atomowych. Modele te można dostroić przy użyciu niewielkiej ilości nowych danych i wciąż dorównują lub przewyższają wiele modeli szytych na miarę pod względem dokładności, co czyni je atrakcyjnymi jako narzędzia ogólne dla nauki o materiałach.
Kiedy większe modele stają się obciążeniem
Moc tych modeli jest także ich słabością. Aby objąć wiele pierwiastków i środowisk wiązań, polegają one na głębokich sieciach typu „message-passing”, które wielokrotnie wymieniają informacje między sąsiednimi atomami. Każda dodatkowa warstwa pomaga atomom wyczuć szerszy region wokół nich, ale jednocześnie zwiększa rozmiar modelu i zużycie pamięci. W efekcie modele te działają znacznie wolniej niż prostsze potencjały uczenia maszynowego i nie radzą sobie łatwo ze strukturami znacznie większymi niż dziesiątki tysięcy atomów. Dla naukowców badających rzadkie zdarzenia, powolną dyfuzję czy złożone przemiany fazowe, ta bariera wydajności przemienia potężne modele w narzędzia niszowe. Autorzy dążą do zachowania zalet modeli bazowych przy jednoczesnym usunięciu niepotrzebnych kosztów.
Przycinanie sieci neuronowej bez utraty zdolności
Pierwszym krokiem proponowanego przepływu pracy jest przycinanie głębokości przekazywania komunikatów. Zespół przeanalizował, jak bardzo każda warstwa w kilku popularnych atomistycznych modelach bazowych rzeczywiście zmienia wewnętrzny opis atomów. Zauważyli efekt „nadwygładzania”: po tym jak wczesne warstwy wykonały większość pracy, późniejsze warstwy wprowadzają tylko drobne, powtarzające się korekty. Wykorzystując to, pozostawili jedynie pierwsze kilka warstw, usunęli resztę, a następnie dostroili skrócony model na danych specyficznych dla zadania. Testy na szkle fosforanowo-litowym, mieszanych układach krzem–krzemionka oraz cząstkach metalu na podporach tlenkowych pokazują, że nawet modele z zaledwie jedną lub dwiema pozostałymi warstwami mogą osiągnąć niemal taką samą dokładność jak pełne sieci, będąc przy tym znacznie lżejsze i szybsze. 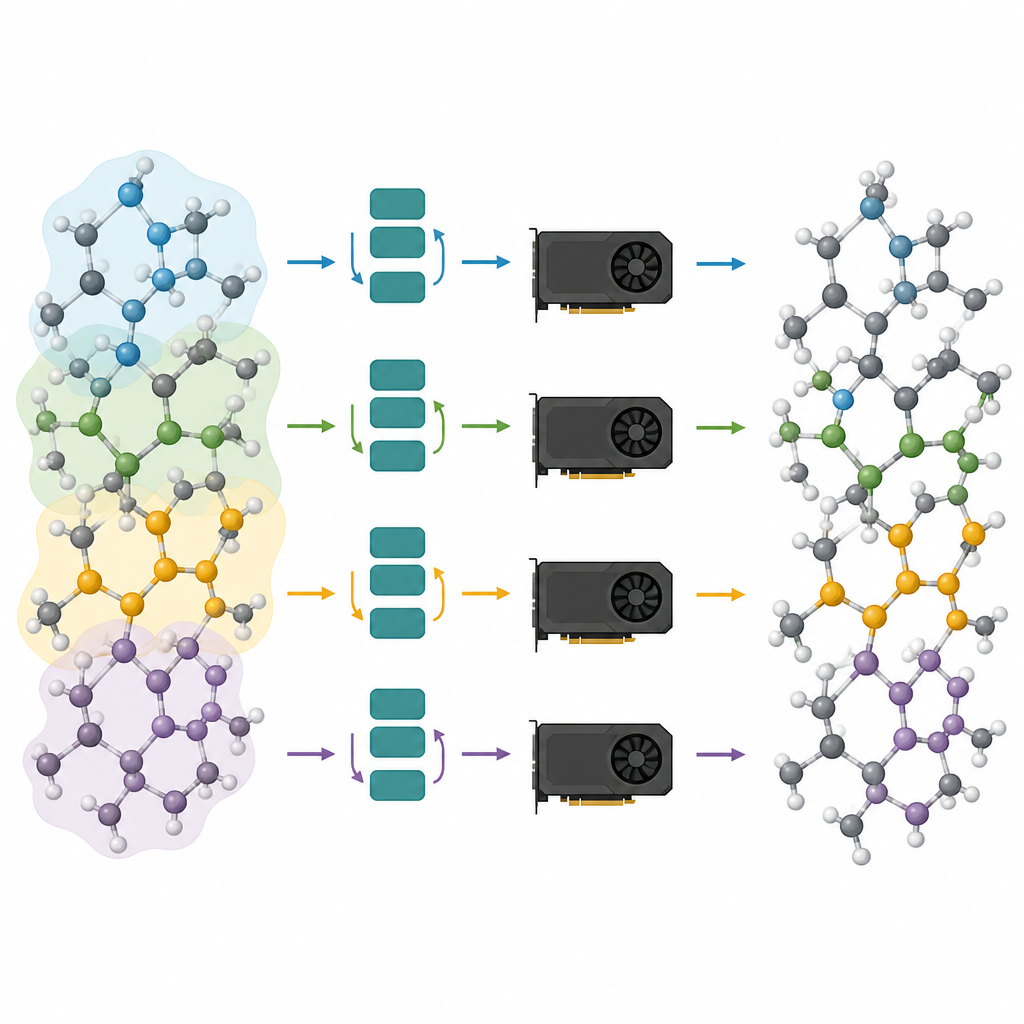
Dzielenie dużych układów atomowych między wiele układów
Przycięte modele to tylko połowa rozwiązania; druga połowa to uruchamianie ich wydajnie na współczesnych procesorach graficznych. Autorzy traktują układ atomowy jako graf, gdzie atomy są węzłami, a wiązania lub bliscy sąsiedzi są krawędziami. Dzielą ten graf na nakładające się fragmenty, z każdym zawierającym wszystkich sąsiadów potrzebnych do wybranego liczby kroków message-passing, i przypisują te podgrafy do różnych procesorów graficznych. Ponieważ model jest teraz płytki, wymagane otoczenie jest niewielkie, a dodatkowe atomy w każdym fragmencie pozostają w granicach rozsądku. Co kluczowe, każdy procesor może uruchomić swój fragment niezależnie, bez komunikacji w czasie ciężkich obliczeń, a wyniki są potem scalane. Tego rodzaju partycjonowanie typu „halo” pozwala tej samej metodzie działać zarówno na pojedynczej karcie graficznej, jak i na kilku pracujących równolegle.
Co umożliwiają nowe narzędzia
Łącząc przycinanie z partycjonowaniem grafu, autorzy osiągają duże zyski w szybkości i skali. Demonstrują, że symulacje milionów atomów, a nawet układy zawierające ponad pięć milionów atomów, są wykonalne na standardowym sprzęcie, przy jednoczesnym zachowaniu wiarygodnych sił i struktur dostarczanych przez modele bazowe. W praktycznych studiach przypadków przycięte modele odtwarzają formowanie amorficznego fosforanu litu, nanoskalowe rozdzielenie w szkłach krzem–krzemionka oraz stopniowe otoczkowanie nanocząstki platyny przez defektową powierzchnię tlenkową. Dla osób spoza specjalizacji przekaz jest jasny: ta praca przemienia wcześniej wolne, pamięciochłonne atomowe AI w oszczędne silniki zdolne zasilać realistyczne symulacje materiałów, otwierając drzwi do rutynowych wirtualnych eksperymentów nad złożonymi urządzeniami i materiałami.
Cytowanie: Kong, L., Shim, J., Hu, G. et al. Scalable foundation interatomic potentials via message-passing pruning and graph partitioning. npj Comput Mater 12, 180 (2026). https://doi.org/10.1038/s41524-026-02001-4
Słowa kluczowe: atomistyczne modele bazowe, dynamika molekularna, grafowe sieci neuronowe, akceleracja GPU, symulacja materiałów