Clear Sky Science · ru
Масштабируемые фундаментальные межатомные потенциалы через отсечение передачи сообщений и разбиение графа
Почему важны более быстрые «атомные фильмы»
Многие технологии, которые имеют для нас значение — от улучшенных батарей до более чистых катализаторов — зависят от того, как ведут себя атомы в течение длительного времени и в огромных числах частиц. Компьютерные симуляции могут создавать «фильмы» движения атомов, но самые точные методы настолько медленны, что часто застревают на крошечных системах и очень коротких временах. В этой работе предложен подход, который сохраняет высокую точность современных моделей искусственного интеллекта для атомов при одновременном снижении их стоимости настолько, что моделирования на миллионы атомов и с наносекундным временным масштабом становятся практичными на современных графических процессорах. 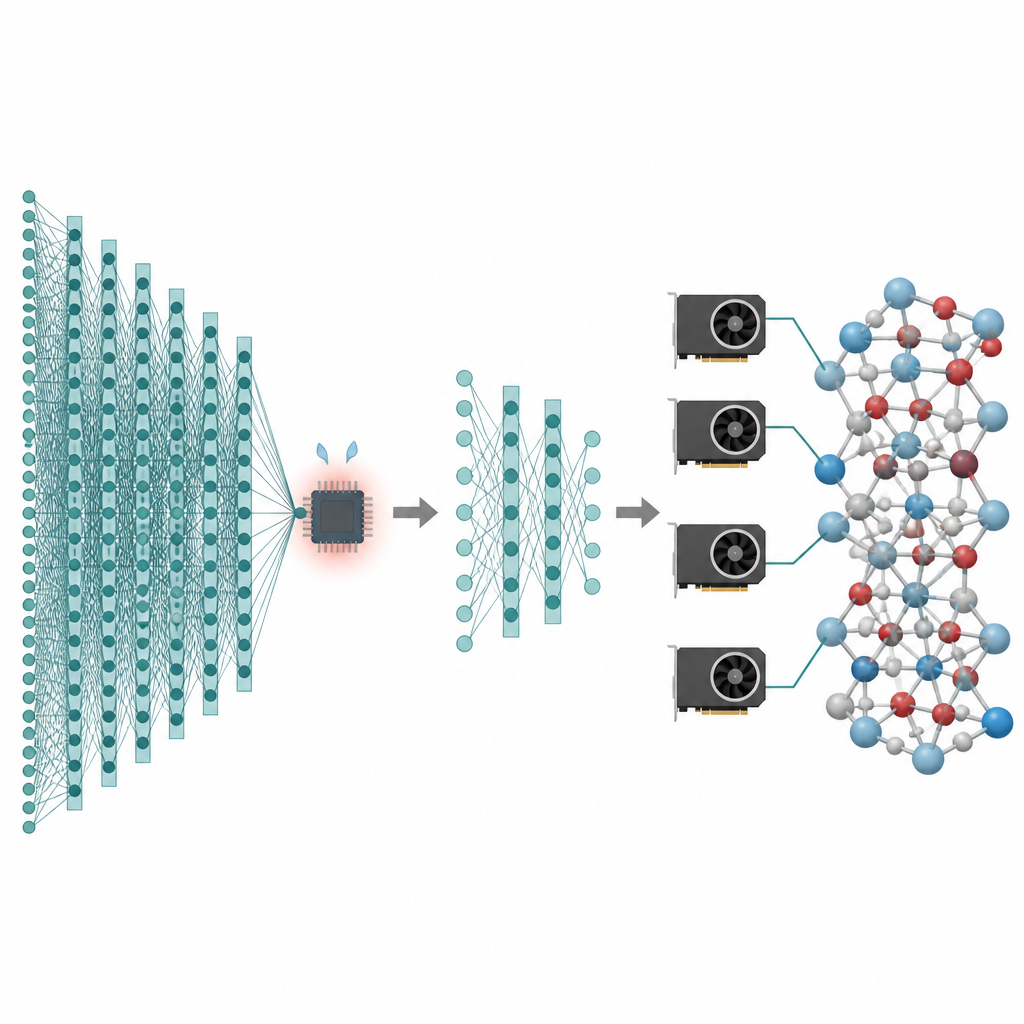
От квантовой точности к практичным пределам
На одном краю спектра квантово-обоснованные методы описывают межатомные взаимодействия с большой детализацией, но они слишком медленны для крупных, реалистичных систем. Чтобы преодолеть этот разрыв, исследователи обратились к моделям машинного обучения, которые учатся предсказывать, как атомы толкают и тянут друг друга, на основе квантовых данных, и заменяют дорогие расчёты быстрыми предсказаниями. Недавний скачок в этой области — появление «атомистических фундаментальных моделей», крупных нейросетей, обученных на обширных и разнообразных наборах атомных структур. Эти модели можно дообучать с небольшим количеством новых данных и они по-прежнему достигают или превосходят по точности многие специально разработанные модели, что делает их привлекательными в качестве универсальных инструментов в материаловедении.
Когда большие модели становятся обузой
Сила этих фундаментальных моделей одновременно является их слабостью. Чтобы охватить многие элементы и среды связи, они опираются на глубокие сети «передачи сообщений», которые многократно обмениваются информацией между соседними атомами. Каждый добавленный слой помогает атомам ощущать более широкую область вокруг себя, но также раздувает размер модели и объём памяти. В результате такие модели работают намного медленнее, чем более простые ML-потенциалы, и не способны легко обрабатывать структуры гораздо больше десятков тысяч атомов. Для учёных, которым нужно изучать редкие события, медленную диффузию или сложные фазовые переходы, это ограничение превращает мощные модели в нишевые инструменты. Авторы стремятся сохранить преимущества фундаментальных моделей, одновременно устранив лишние затраты.
Обрезка нейросети без потери навыков
Первый шаг в предлагаемом рабочем процессе называется отсечением глубины передачи сообщений. Команда проанализировала, насколько каждый слой в нескольких популярных атомистических фундаментальных моделях действительно меняет внутреннее описание атомов. Они обнаружили эффект «переусреднения»: после того как ранние слои выполнили большую часть работы, последующие слои вносят лишь крошечные, повторяющиеся корректировки. Воспользовавшись этим, они просто оставляют первые несколько слоёв и удаляют остальные, после чего дообучают укороченную модель на данных, специфичных для задач. Тесты на стекле фосфата лития, смешанных системах кремния и кремнезёма, а также на металлических частицах на оксидных опорах показывают, что даже модели с только одним или двумя оставшимися слоями могут достигать почти такой же точности, как полные сети, при значительно меньшем размере и большей скорости. 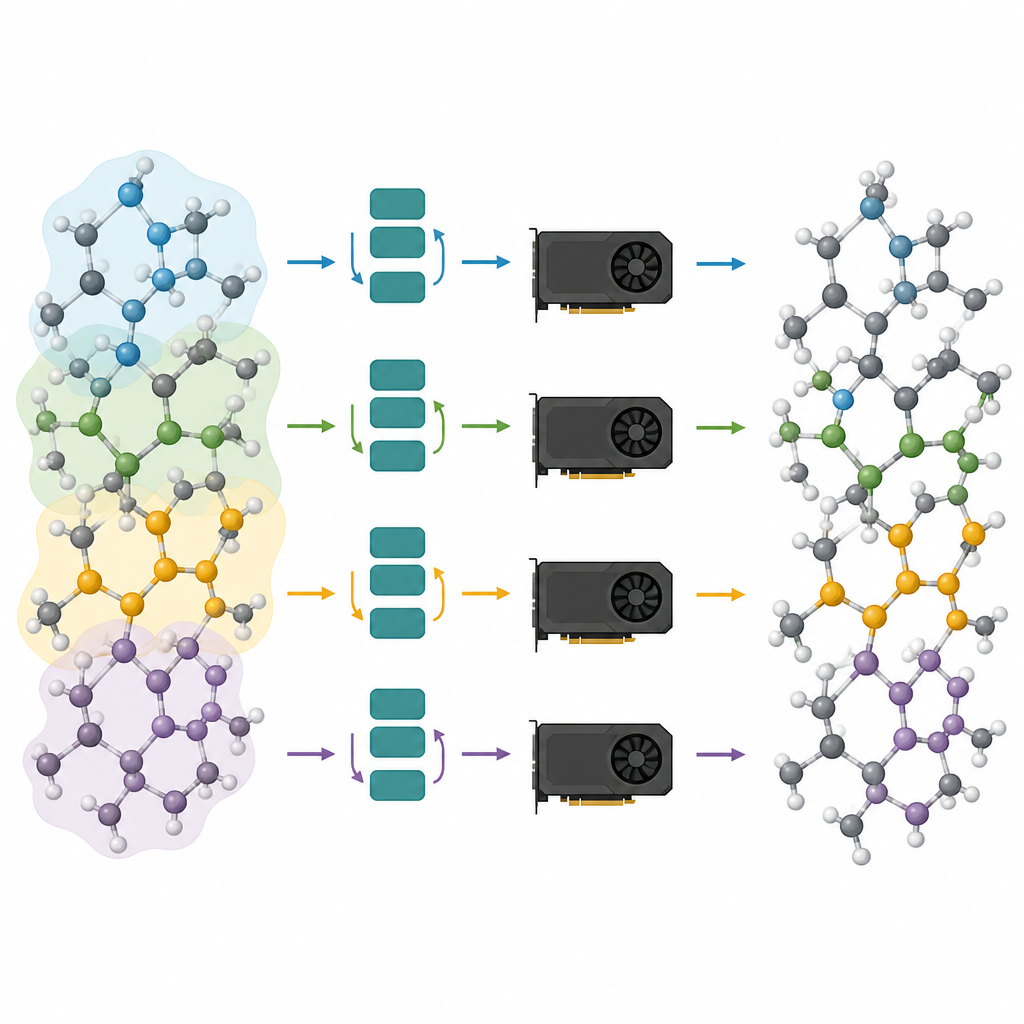
Разбиение больших атомных систем между множеством чипов
Отсечённые модели — это лишь половина решения; другая половина — их эффективный запуск на современных графических процессорах. Авторы рассматривают атомную систему как граф, где атомы — это узлы, а связи или близкие соседи — рёбра. Они делят этот граф на перекрывающиеся фрагменты, каждый из которых содержит всех соседей, необходимых для выбранного числа шагов передачи сообщений, и назначают эти подграфы разным GPU. Поскольку модель теперь неглубокая, требуемая окрестность небольшая, и дополнительные атомы в каждом фрагменте остаются управляемыми. Важно, что каждый процессор может независимо выполнять вычисления над своим фрагментом без необходимости обмена данными в течение тяжёлой фазы вычислений, а затем результаты сшиваются вместе. Такое «гало»-разбиение позволяет использовать тот же метод как для одной видеокарты, так и для нескольких, работающих параллельно.
Что дают новые инструменты
Объединив отсечение и разбиение графа, авторы добиваются значительного ускорения и масштабирования. Они демонстрируют, что моделирования на миллион атомов и даже системы с более чем пятью миллионами атомов возможны на стандартном оборудовании при сохранении надёжных сил и структур, которые дают фундаментальные модели. В практических кейсах отсечённые модели воспроизводят формирование аморфного фосфата лития, наноразмерное разделение в кремний–кремнезёмных стёклах и постепенное инкапсулирование платино-наночастицы деформированной оксидной поверхностью. Для неспециалистов посыл ясен: эта работа превращает ранее медленные и прожорливые по памяти атомные ИИ в стройные движки, способные обеспечивать реалистичные моделирования материалов, что открывает дорогу рутинным виртуальным экспериментам над сложными устройствами и материалами.
Цитирование: Kong, L., Shim, J., Hu, G. et al. Scalable foundation interatomic potentials via message-passing pruning and graph partitioning. npj Comput Mater 12, 180 (2026). https://doi.org/10.1038/s41524-026-02001-4
Ключевые слова: атомистические фундаментальные модели, молекулярная динамика, графовые нейронные сети, ускорение на GPU, моделирование материалов