Clear Sky Science · zh
用于训练深度脉冲神经网络的高能效多核类脑架构
为边缘设备带来更聪明的学习能力
我们的手机、相机和微型传感器变得越来越智能,但教会它们新技能通常需要耗能巨大的数据中心。本文提出了一种新型受大脑启发的计算芯片,能够在小型设备上直接学习,同时比当今的图形处理器消耗更少的能量。它旨在为汽车、无人机和其他需要快速响应且不依赖云端持续支持的设备带来灵活且更注重隐私的学习能力。
类脑芯片为何重要
传统芯片如 GPU 擅长大量数值计算,但它们消耗大量能量并依赖于与远程服务器的高速链路。对于交通监控或无人机导航等任务,将原始数据发送到云端既慢又可能泄露隐私信息。神经形态计算采用不同思路,模拟大脑神经元网络交换短脉冲电信号的方式。脉冲神经网络在运算次数更少的情况下仍有望达到高精度,使其成为置于网络边缘的低功耗设备的有吸引力选择。
脉冲硬件的缺失环节
许多研究芯片已经能高效运行脉冲网络,但几乎所有这类芯片都存在一个关键限制:它们擅长运行固定的已训练模型,但不擅长自行训练大型深度脉冲网络。大多数方案依赖简单的局部学习规则,或将繁重的反复训练过程卸载给 GPU。这意味着设计者无法在学习阶段充分利用潜在的能量节省,也使得小型设备在环境变化(如新的交通标志或照明条件)时难以即时适应。
用于片上学习的新型多核设计
作者提出了一种多核神经形态架构,每个核心包含三个协同工作的引擎:一个处理网络中信号的前向流动,一个传递误差信息的反向通路,另一个负责更新连接强度(权重)。这些核心按二维网格互联,因此深度脉冲网络的不同层可以部署在不同核心上并行工作。一个精心设计的通信网络在脉冲时序下在核心之间传输既快速的单比特脉冲又较慢的精确信号,同时近存储(near-memory)设计将绝大多数数据保留在片上,减少昂贵的外部内存访问。
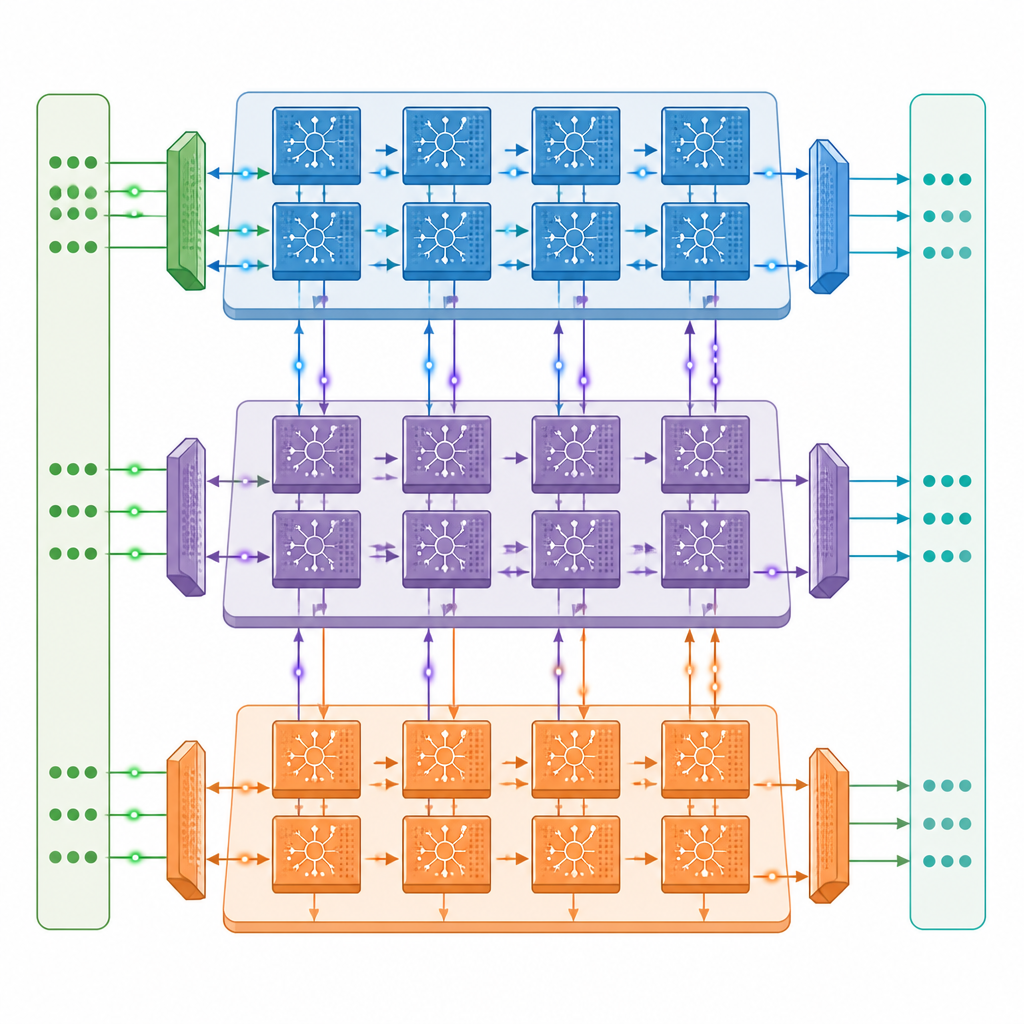
减少数据移动、提高效率
在每个引擎内部,硬件针对脉冲活动的断续特性进行了调优。电路能够检测到神经元群处于静默状态并跳过不必要的计算和内存读取,这一策略在标准图像识别模型的训练中大约可将能耗降低一半。该设计还尽可能重用存储数据,并将脉冲以单比特形式存储,大幅降低对外部内存的需求。在针对流行的深度脉冲版 ResNet 与 VGG 网络的测试中,该原型在训练速度上达到了强大 A100 数据中心 GPU 的约三分之一,尽管其原始计算能力仅约为后者的二十分之一左右,并且明显优于 Jetson Orin 边缘系统。
从实验室原型走向真实的边缘学习
为了证明该思路在仿真之外可行,团队将该架构的较小版本映射到多块 FPGA 板上,并在标准图像与基于事件的手势数据集上训练脉冲网络。该系统支持持续学习(模型随着新样本出现不断更新)和联邦学习(多个设备在本地训练并仅共享紧凑的更新)。在两种情况下,分布式脉冲系统在不集中原始数据的前提下提高了准确性,暗示了未来在智慧城市与机器人领域的应用场景,其中大量设备在学习过程中同时控制能耗与带宽需求。
对日常技术的意义
简而言之,这项工作展示了如何构建一个能适应边缘设备严格功耗预算的类脑训练引擎。通过将许多小型学习核心、智能数据路由和对无谓工作的大幅跳过结合起来,该架构在无需依赖大型数据中心的情况下高效训练深度脉冲网络。如果最终实现为实际芯片,此类设计可帮助相机、汽车与家用设备实时从周围环境中学习,同时保护隐私并节省能源。
引用: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
关键词: 神经形态计算, 脉冲神经网络, 边缘人工智能, 低功耗硬件, 片上学习