Clear Sky Science · it
Un'architettura neuromorfica multicore ad alta efficienza energetica per l'addestramento di reti neurali a spike profonde
Apprendimento più intelligente per i dispositivi edge
I nostri telefoni, le fotocamere e i piccoli sensori diventano sempre più intelligenti, ma insegnare loro nuove abilità di solito richiede data center energivori. Questo articolo presenta un nuovo tipo di circuito integrato ispirato al cervello che può apprendere direttamente su dispositivi compatti consumando molto meno energia rispetto alle attuali GPU. L'obiettivo è portare apprendimento flessibile e rispettoso della privacy su auto, droni e altri dispositivi che devono reagire rapidamente senza dipendere continuamente dal cloud.
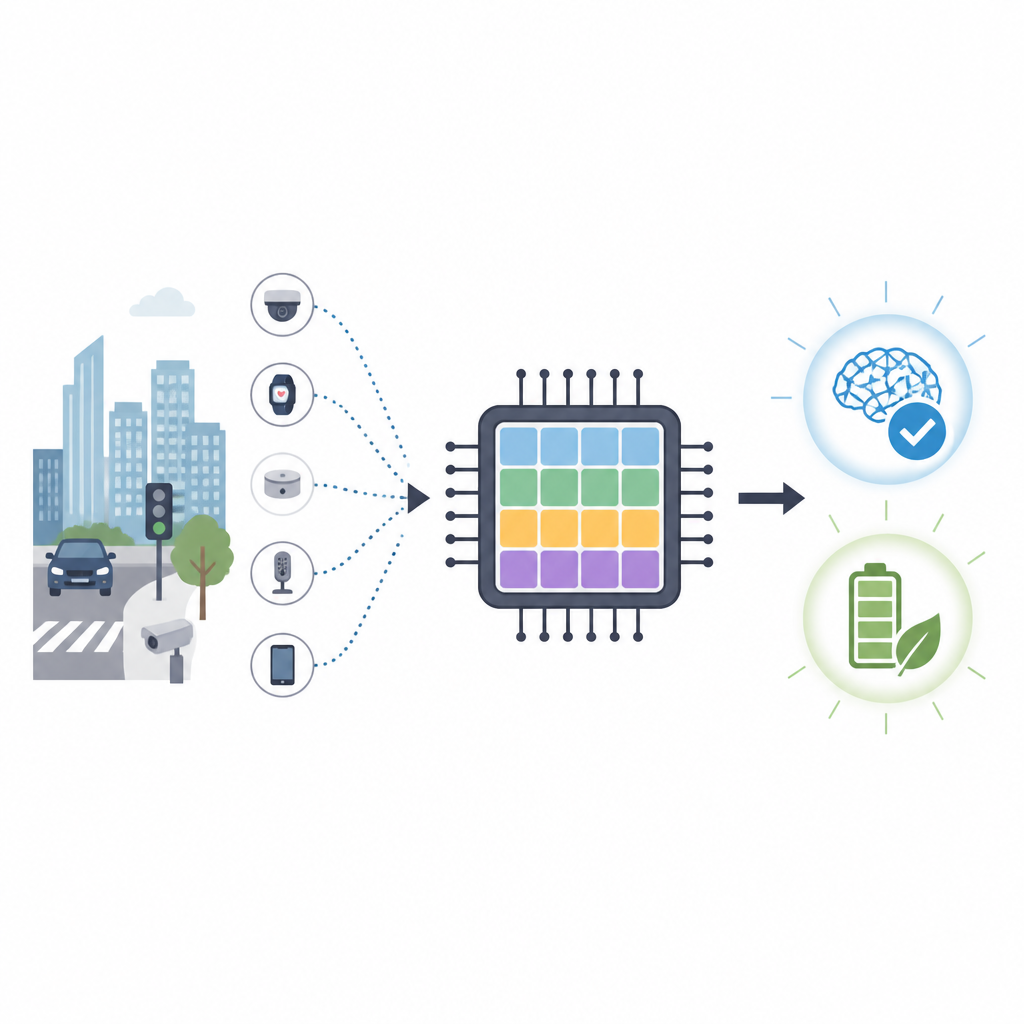
Perché i chip ispirati al cervello sono importanti
I chip convenzionali come le GPU sono eccellenti nel calcolo intensivo, ma consumano molta energia e dipendono da collegamenti veloci verso server remoti. Per compiti come il monitoraggio del traffico o la navigazione dei droni, inviare dati grezzi al cloud è lento e può esporre informazioni private. Il calcolo neuromorfico adotta un approccio diverso imitando il modo in cui le reti di cellule cerebrali scambiano brevi spike elettrici. Le reti neurali a spike promettono alta precisione con molte meno operazioni, rendendole attraenti per dispositivi a basso consumo collocati all'edge della rete.
La parte mancante nell'hardware a spike
Molti chip di ricerca già eseguono reti a spike in modo efficiente, eppure quasi tutti condividono una limitazione fondamentale: sono bravi a usare un modello addestrato e fisso, ma non a addestrare essi stessi grandi reti a spike profonde. La maggior parte si affida a regole di apprendimento locali semplici o scarica il pesante processo di addestramento avanti e indietro sulle GPU. Ciò significa che i progettisti non possono sfruttare appieno il potenziale risparmio energetico durante l'apprendimento e rende più difficile per i dispositivi piccoli adattarsi al volo quando le condizioni cambiano, ad esempio nuovi segnali stradali o diverse condizioni di illuminazione.
Un nuovo progetto multicore per l'apprendimento on chip
Gli autori introducono un'architettura neuromorfica multicore in cui ogni core contiene tre motori cooperanti: uno che gestisce i segnali che fluiscono in avanti nella rete, uno che invia le informazioni di errore all'indietro e uno che aggiorna le forze di connessione. Questi core sono collegati in una griglia bidimensionale, così diversi strati di una rete a spike profonda possono risiedere su core differenti e lavorare in parallelo. Una rete di comunicazione accuratamente progettata muove sia spike veloci a bit singolo sia valori più lenti e precisi tra i core sincronizzati con il timing degli spike, mentre un design con memoria vicina mantiene la maggior parte dei dati on chip e riduce i costosi accessi alla memoria esterna.
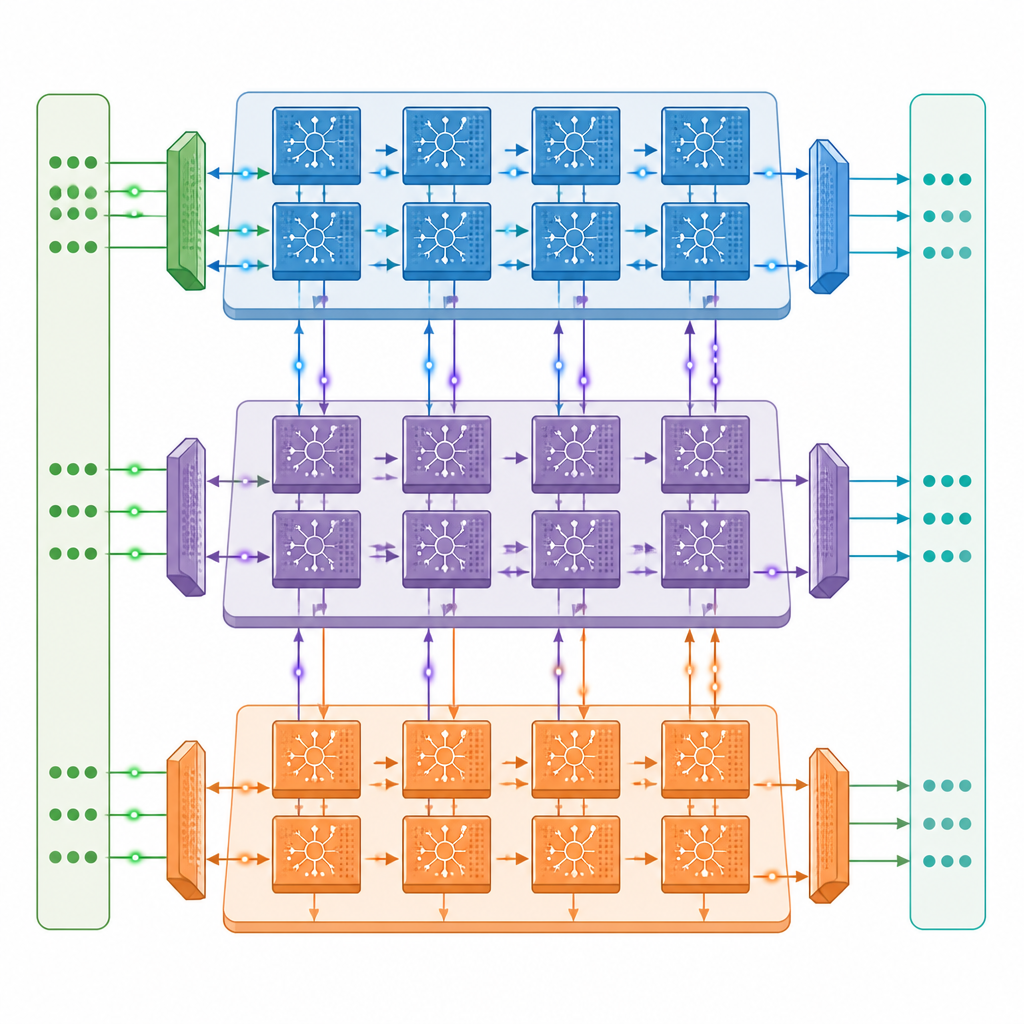
Fare di più con meno movimento di dati
All'interno di ogni motore, l'hardware è sintonizzato sulla natura a intermittenza dell'attività a spike. I circuiti rilevano quando gruppi di neuroni sono silenti e saltano calcoli e letture di memoria non necessari, una strategia che dimezza circa il consumo energetico durante l'addestramento su modelli standard di riconoscimento delle immagini. Il progetto riutilizza inoltre i dati memorizzati ogni volta che è possibile e conserva gli spike come singoli bit, il che riduce fortemente la quantità di memoria esterna necessaria. Nei test con versioni a spike profonde popolari delle reti ResNet e VGG, il prototipo raggiunge fino a circa un terzo della velocità di addestramento di una potente GPU A100 da data center, pur avendo solo circa un ventesimo della sua capacità di calcolo grezza, e sovraperforma nettamente un sistema edge Jetson Orin.
Dal prototipo di laboratorio all'apprendimento reale in edge
Per dimostrare che l'idea funziona oltre le simulazioni, il team ha mappato una versione più piccola dell'architettura su più schede FPGA e ha addestrato reti a spike su dataset standard di immagini e di gesti basati su eventi. Il sistema ha gestito l'apprendimento continuo, in cui i modelli vengono aggiornati man mano che appaiono nuovi tipi di campioni, e l'apprendimento federato, in cui più dispositivi addestrano localmente e condividono solo aggiornamenti compatti. In entrambi i casi, il sistema a spike distribuito ha migliorato l'accuratezza senza centralizzare i dati grezzi, suggerendo applicazioni future per città intelligenti e robotica dove molti dispositivi apprendono insieme mantenendo sotto controllo consumo energetico e larghezza di banda.
Cosa significa per la tecnologia di tutti i giorni
In termini semplici, questo lavoro mostra come costruire un motore di addestramento ispirato al cervello che si adatta ai rigidi vincoli di consumo dei dispositivi edge. Combinando molti piccoli core di apprendimento, instradamento intelligente dei dati e l'elisione aggressiva di lavoro superfluo, l'architettura addestra reti a spike profonde in modo efficiente senza appoggiarsi a grandi data center. Se trasformati in chip, progetti come questo potrebbero aiutare fotocamere, auto e dispositivi domestici a imparare dall'ambiente in tempo reale, preservando la privacy e risparmiando energia.
Citazione: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
Parole chiave: calcolo neuromorfico, reti neurali a spike, edge AI, hardware a basso consumo, apprendimento on chip