Clear Sky Science · nl
Een zeer energiezuinige multi-core neuromorfe architectuur voor het trainen van diepe spiking neurale netwerken
Slimmere leermethoden voor randapparaten
Onze telefoons, camera’s en kleine sensoren worden slimmer, maar ze nieuwe vaardigheden aanleren vereist meestal energieverslindende datacenters. Dit artikel presenteert een nieuw type door het brein geïnspireerde computerchip die direct op kleine apparaten kan leren en daarbij veel minder energie gebruikt dan de huidige grafische processors. Het heeft als doel flexibel, privacyvriendelijk leren te brengen naar auto’s, drones en andere apparaten die snel moeten reageren zonder voortdurend op de cloud te vertrouwen.
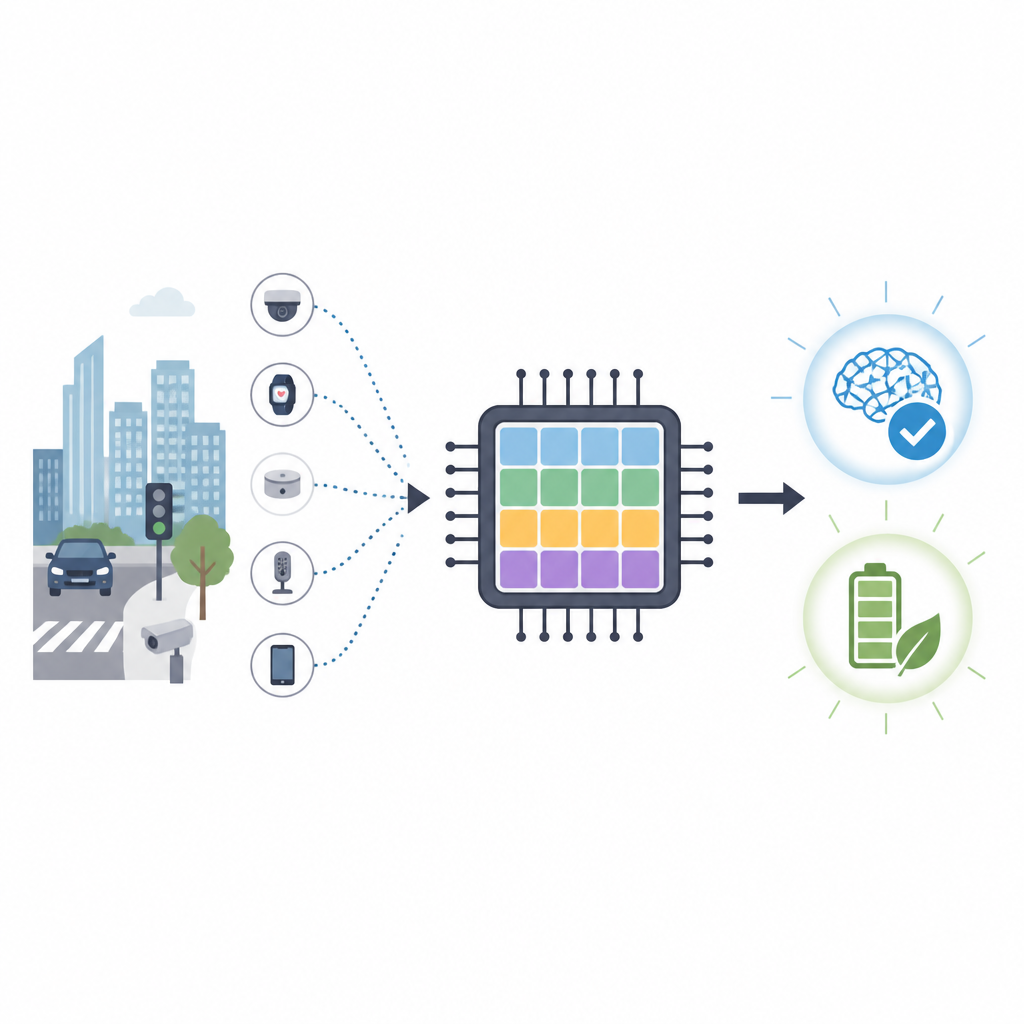
Waarom breinachtige chips ertoe doen
Conventionele chips zoals GPU’s zijn uitstekend in het verwerken van grote rekenklussen, maar ze verbruiken veel energie en zijn afhankelijk van snelle verbindingen naar externe servers. Voor taken zoals verkeersbewaking of drone-navigatie is het versturen van ruwe data naar de cloud traag en kan het privacygevoelig zijn. Neuromorfe computing kiest een andere aanpak door na te bootsen hoe netwerken van hersencellen korte elektrische spikes uitwisselen. Spiking neurale netwerken beloven hoge nauwkeurigheid met veel minder bewerkingen, waardoor ze aantrekkelijk zijn voor energiezuinige apparaten aan de rand van het netwerk.
Het ontbrekende stuk in spiking-hardware
Veel onderzoekschips draaien spiking-netwerken al efficiënt, maar bijna al deze ontwerpen hebben een belangrijke beperking: ze zijn goed in het gebruiken van een vooraf getraind model, maar niet in het zelf trainen van grote diepe spiking-netwerken. De meeste vertrouwen op eenvoudige lokale leerregels of offloaden het zware heen-en-weer trainingsproces naar GPU’s. Dat betekent dat ontwerpers het potentiële energiewinst tijdens het leren niet volledig kunnen benutten, en het bemoeilijkt het voor kleine apparaten om zich snel aan te passen wanneer omstandigheden veranderen, zoals nieuwe verkeersborden of lichtomstandigheden.
Een nieuw multi-core ontwerp voor on-chip leren
De auteurs introduceren een multi-core neuromorfe architectuur waarbij elke core drie samenwerkende engines bevat: één die signalen voorwaarts door het netwerk begeleidt, één die foutinformatie terugstuurt, en één die de verbindingssterkten bijwerkt. Deze cores zijn verbonden in een tweedimensionaal raster, zodat verschillende lagen van een diep spiking-netwerk op verschillende cores kunnen draaien en parallel kunnen werken. Een zorgvuldig ontworpen communicatienetwerk verplaatst zowel snelle één-bit spikes als langzamere precieze waarden tussen cores in samenhang met de timing van de spikes, terwijl een near-memory ontwerp de meeste data op de chip houdt en dure trips naar extern geheugen vermindert.
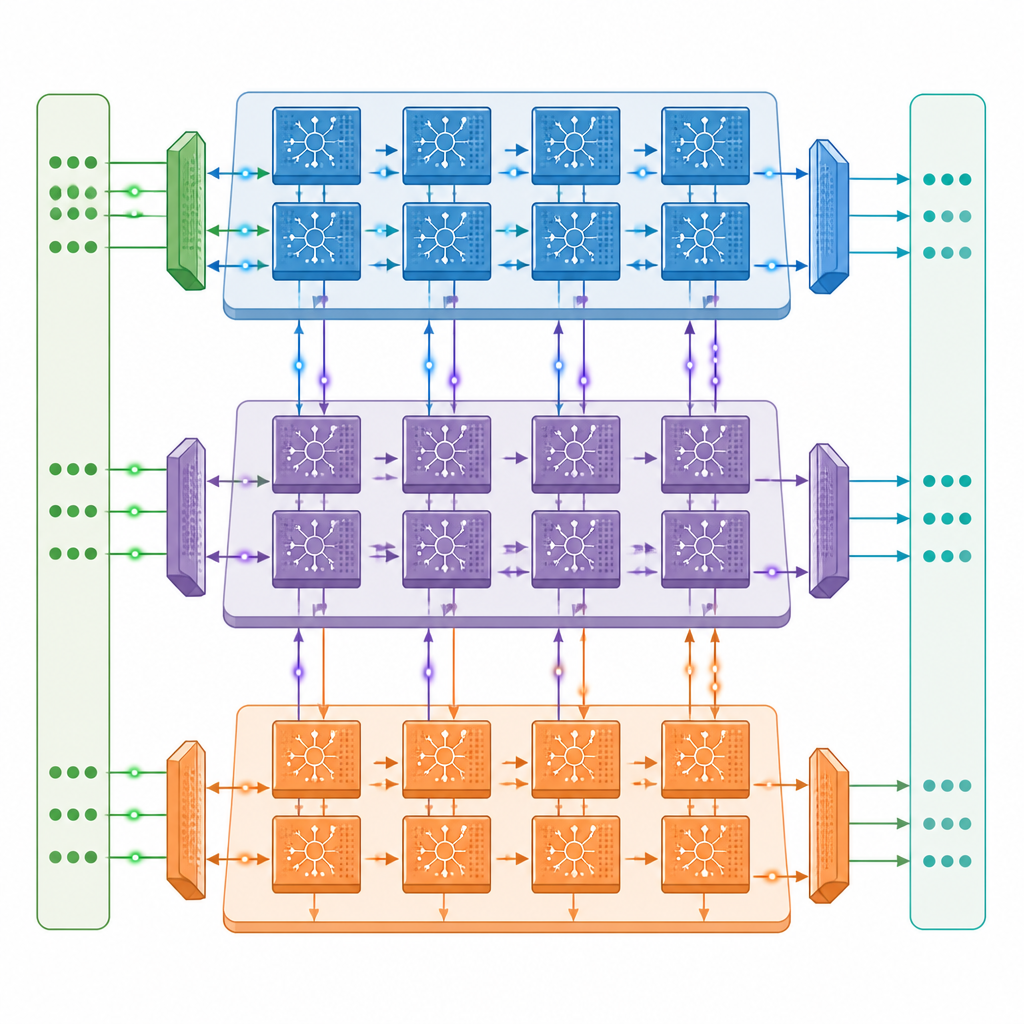
Meer doen met minder databeweging
Binnen elke engine is de hardware afgestemd op het stop-start karakter van spiking-activiteit. Schakelingen detecteren wanneer groepen neuronen stil zijn en slaan overbodige berekeningen en geheugentoegang over, een strategie die het energieverbruik tijdens training op standaard beeldherkenningsmodellen ongeveer halveert. Het ontwerp hergebruikt ook opgeslagen data waar mogelijk en slaat spikes op als enkele bits, wat de hoeveelheid extern geheugen sterk vermindert. In tests met populaire diepe spiking-versies van ResNet- en VGG-netwerken bereikt het prototype tot circa een derde van de trainingssnelheid van een krachtige A100-datacenter-GPU, ondanks dat het slechts ongeveer een twintigste van de ruwe rekencapaciteit heeft, en het presteert duidelijk beter dan een Jetson Orin edge-systeem.
Van labprototype naar echt edge-leren
Om te tonen dat het idee verder gaat dan simulaties, heeft het team een kleinere versie van de architectuur op meerdere FPGA-borden gezet en spiking-netwerken getraind op standaard beeld- en event-gebaseerde gebaardatasets. Het systeem ging om met continual learning, waarbij modellen worden bijgewerkt zodra nieuwe soorten voorbeelden verschijnen, en federated learning, waarin meerdere apparaten lokaal trainen en alleen compacte updates delen. In beide gevallen verbeterde het gedistribueerde spiking-systeem de nauwkeurigheid zonder ruwe data te centraliseren, wat wijst op toekomstige toepassingen in slimme steden en robotica waarbij veel apparaten samen leren terwijl energie- en bandbreedtevraag beheerst blijven.
Wat dit betekent voor alledaagse technologie
Simpel gezegd laat dit werk zien hoe je een breinachtige trainingsmotor bouwt die binnen de strakke energiegrenzen van randapparaten past. Door veel kleine leerkernen te combineren, slimme gegevensroutering en agressief overslaan van onnodig werk, traint de architectuur diepe spiking-netwerken efficiënt zonder te leunen op gigantische datacenters. Als dit in chips wordt omgezet, kunnen ontwerpen zoals deze camera’s, auto’s en huishoudelijke apparaten helpen om in real time van hun omgeving te leren, terwijl ze privacy bewaren en energie besparen.
Bronvermelding: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
Trefwoorden: neuromorfe computing, spiking neurale netwerken, edge-AI, energiezuinige hardware, on-chip leren