Clear Sky Science · es
Una arquitectura neuromórfica multinúcleo altamente eficiente en energía para entrenar redes neuronales espiga profundas
Aprendizaje más inteligente para dispositivos en el borde
Nuestros teléfonos, cámaras y pequeños sensores son cada vez más inteligentes, pero enseñarles nuevas habilidades suele requerir centros de datos con alto consumo energético. Este artículo presenta un nuevo tipo de chip inspirado en el cerebro que puede aprender directamente en dispositivos pequeños empleando mucha menos energía que las actuales unidades gráficas. Su objetivo es llevar un aprendizaje flexible y respetuoso con la privacidad a coches, drones y otros dispositivos que deben reaccionar rápido sin depender constantemente de la nube.
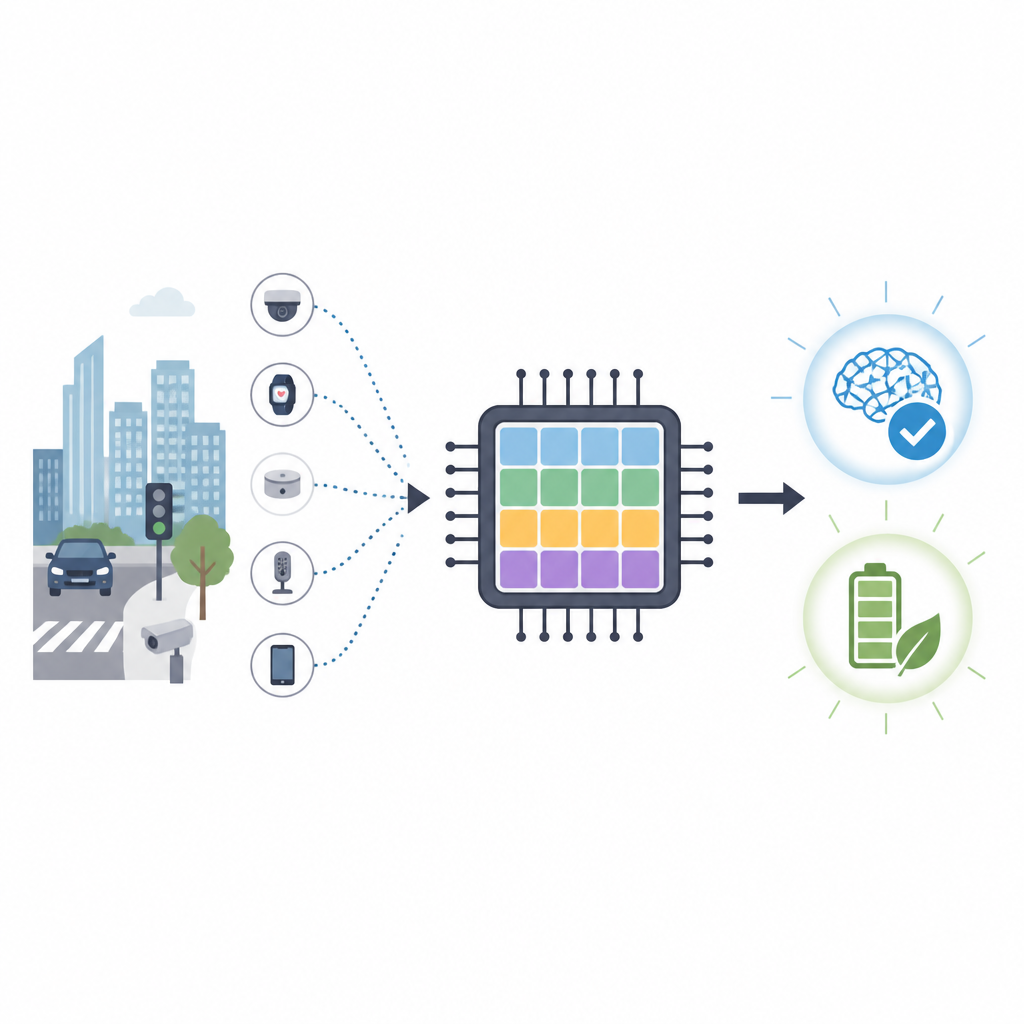
Por qué importan los chips tipo cerebro
Los chips convencionales como las GPU son excelentes para procesar números, pero consumen mucha energía y dependen de enlaces rápidos con servidores remotos. Para tareas como la vigilancia del tráfico o la navegación de drones, enviar datos en bruto a la nube es lento y puede exponer información privada. La computación neuromórfica adopta un enfoque distinto al imitar cómo las redes de células cerebrales intercambian breves espigas eléctricas. Las redes neuronales espiga prometen alta precisión con muchas menos operaciones, lo que las hace atractivas para dispositivos de bajo consumo situados en el borde de la red.
La pieza que falta en el hardware espiga
Muchos chips de investigación ya ejecutan redes espiga de forma eficiente, pero casi todos comparten una limitación clave: son buenos usando un modelo entrenado y fijo, pero no en entrenar por sí mismos grandes redes espiga profundas. La mayoría se limita a reglas de aprendizaje local simples o descarga el pesado proceso iterativo de entrenamiento a las GPU. Eso impide aprovechar totalmente el potencial de ahorro energético durante el aprendizaje y dificulta que los dispositivos pequeños se adapten sobre la marcha cuando cambian las condiciones, como nuevos señales de tráfico o variaciones de iluminación.
Un nuevo diseño multinúcleo para aprendizaje en chip
Los autores presentan una arquitectura neuromórfica multinúcleo en la que cada núcleo contiene tres motores cooperativos: uno que gestiona las señales que fluyen hacia adelante por la red, otro que envía la información de error hacia atrás y otro que actualiza las fuerzas de conexión. Estos núcleos están conectados en una rejilla bidimensional, de modo que diferentes capas de una red espiga profunda pueden asentarse en núcleos distintos y trabajar en paralelo. Una red de comunicación cuidadosamente diseñada mueve tanto espigas rápidas de un bit como valores más lentos y precisos entre núcleos, sincronizada con el tiempo de las espigas, mientras que un diseño de memoria cercana mantiene la mayor parte de los datos en el chip y reduce los costosos accesos a memoria externa.
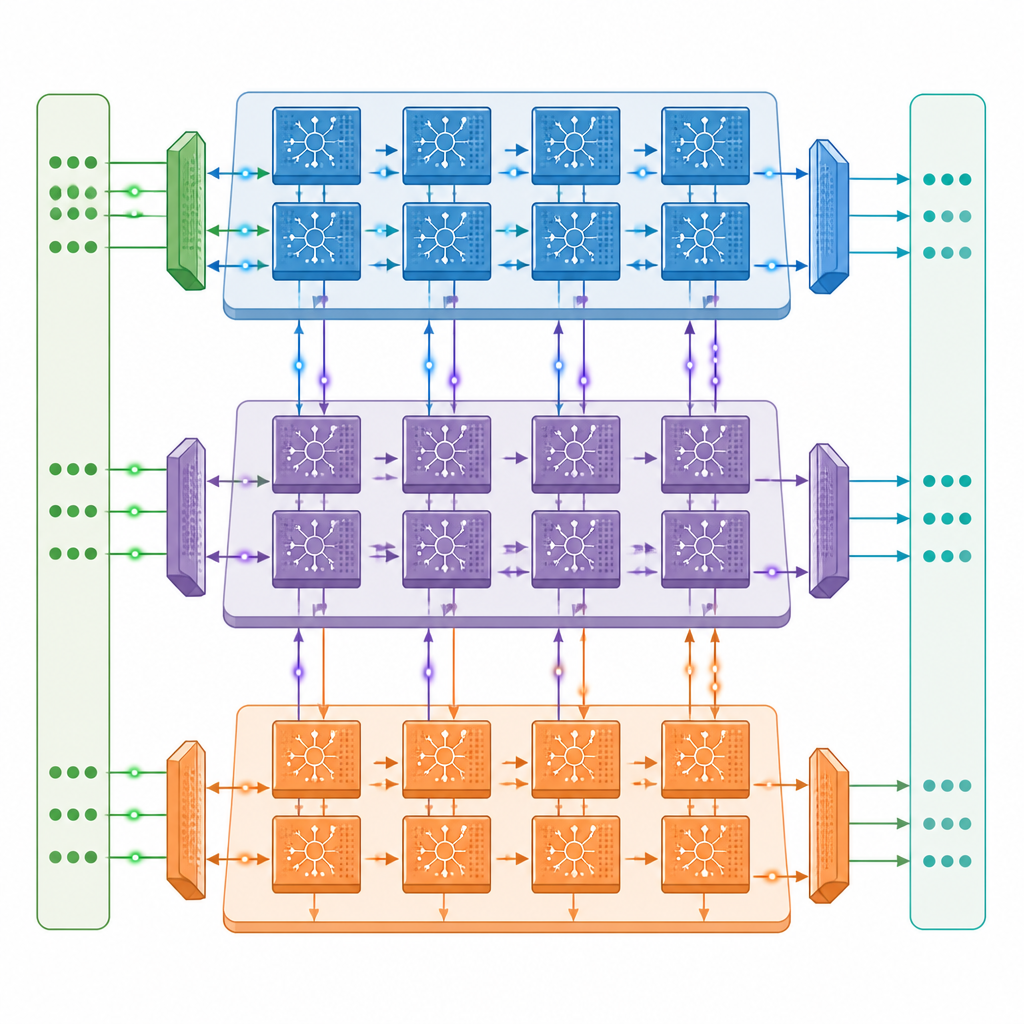
Hacer más con menos movimiento de datos
Dentro de cada motor, el hardware está afinado para la naturaleza intermitente de la actividad por espigas. Los circuitos detectan cuando grupos de neuronas están en silencio y omiten cálculos y lecturas de memoria innecesarios, una estrategia que reduce el consumo energético aproximadamente a la mitad durante el entrenamiento en modelos estándar de reconocimiento de imágenes. El diseño también reutiliza datos almacenados siempre que es posible y codifica las espigas como bits individuales, lo que reduce drásticamente la necesidad de memoria externa. En pruebas con versiones espiga profundas populares de ResNet y VGG, el prototipo alcanza hasta aproximadamente un tercio de la velocidad de entrenamiento de una potente GPU de centro de datos A100, a pesar de tener sólo alrededor de una vigésima parte de su capacidad bruta de cómputo, y supera claramente a un sistema de borde Jetson Orin.
Del prototipo de laboratorio al aprendizaje real en el borde
Para demostrar que la idea funciona más allá de las simulaciones, el equipo mapeó una versión más pequeña de la arquitectura en varias placas FPGA y entrenó redes espiga con conjuntos de datos estándar de imágenes y gestos basados en eventos. El sistema manejó aprendizaje continuo, donde los modelos se actualizan según aparecen nuevos tipos de muestras, y aprendizaje federado, donde varios dispositivos entrenan localmente y comparten sólo actualizaciones compactas. En ambos casos, el sistema espiga distribuido mejoró la precisión sin centralizar datos en bruto, lo que apunta a futuras aplicaciones en ciudades inteligentes y robótica donde muchos dispositivos aprenden juntos manteniendo bajo control la demanda de energía y ancho de banda.
Qué significa esto para la tecnología cotidiana
En términos sencillos, este trabajo muestra cómo construir un motor de entrenamiento tipo cerebro que encaja en los ajustados presupuestos de energía de los dispositivos de borde. Al combinar muchos pequeños núcleos de aprendizaje, enrutamiento inteligente de datos y omisión agresiva de trabajo innecesario, la arquitectura entrena redes espiga profundas de forma eficiente sin apoyarse en gigantescos centros de datos. Si se lleva a chips comerciales, diseños como este podrían ayudar a cámaras, coches y dispositivos domésticos a aprender de su entorno en tiempo real, preservando la privacidad y ahorrando energía.
Cita: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
Palabras clave: computación neuromórfica, redes neuronales espiga, IA en el borde, hardware de bajo consumo, aprendizaje en chip