Clear Sky Science · pt
Uma arquitetura neuromórfica multicore altamente eficiente em energia para treinar redes neurais pulsantes profundas
Aprendizado mais inteligente para dispositivos de borda
Nossos telefones, câmeras e pequenos sensores estão ficando mais inteligentes, mas ensiná‑los novas habilidades geralmente exige centros de dados sedentos por energia. Este artigo apresenta um novo tipo de chip inspirado no cérebro que pode aprender diretamente em dispositivos pequenos enquanto consome bem menos energia do que os processadores gráficos atuais. O objetivo é levar aprendizado flexível e que preserva a privacidade para carros, drones e outros aparelhos que precisam reagir rapidamente sem depender constantemente da nuvem.
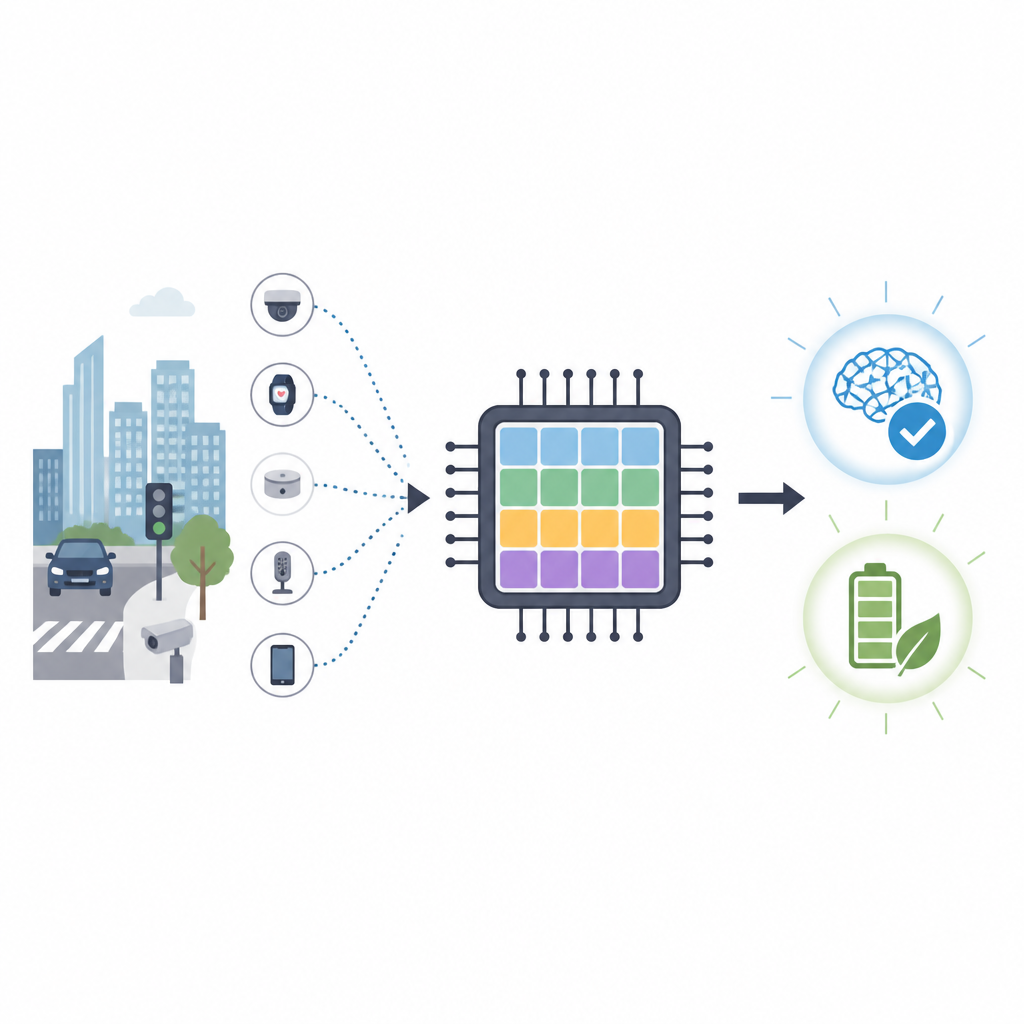
Por que chips inspirados no cérebro importam
Chips convencionais, como GPUs, são excelentes em processar grande quantidade de dados, mas consomem muita energia e dependem de conexões rápidas com servidores distantes. Para tarefas como monitoramento de tráfego ou navegação de drones, enviar dados brutos para a nuvem é lento e pode expor informações privadas. A computação neuromórfica adota uma abordagem diferente, imitando como redes de células cerebrais trocam pequenos pulsos elétricos. Redes neurais pulsantes prometem alta precisão com muito menos operações, tornando‑as atraentes para dispositivos de baixa potência colocados na borda da rede.
A peça que faltava no hardware pulsante
Muitos chips de pesquisa já executam redes pulsantes de forma eficiente, porém quase todos compartilham uma limitação chave: são bons em usar um modelo treinado fixo, mas não em treinar grandes redes pulsantes profundas por conta própria. A maioria recorre a regras locais de aprendizado simples ou offloads do pesado processo de treinamento de vai e vem para GPUs. Isso impede que os projetistas explorem totalmente as economias de energia possíveis durante o aprendizado e dificulta a adaptação rápida de dispositivos pequenos quando as condições mudam, como novos sinais de trânsito ou variações de iluminação.
Um novo projeto multicore para aprendizado no chip
Os autores introduzem uma arquitetura neuromórfica multicore em que cada core contém três motores cooperativos: um que lida com sinais que fluem para frente através da rede, outro que envia informações de erro para trás e um que atualiza as forças das conexões. Esses cores são ligados em uma grade bidimensional, de modo que diferentes camadas de uma rede pulsante profunda podem ficar em cores distintos e trabalhar em paralelo. Uma rede de comunicação cuidadosamente projetada movimenta tanto pulsos rápidos de um bit quanto valores mais lentos e precisos entre os cores em sincronia com o tempo dos pulsos, enquanto um design com memória próxima mantém a maior parte dos dados no chip e reduz viagens caras à memória externa.
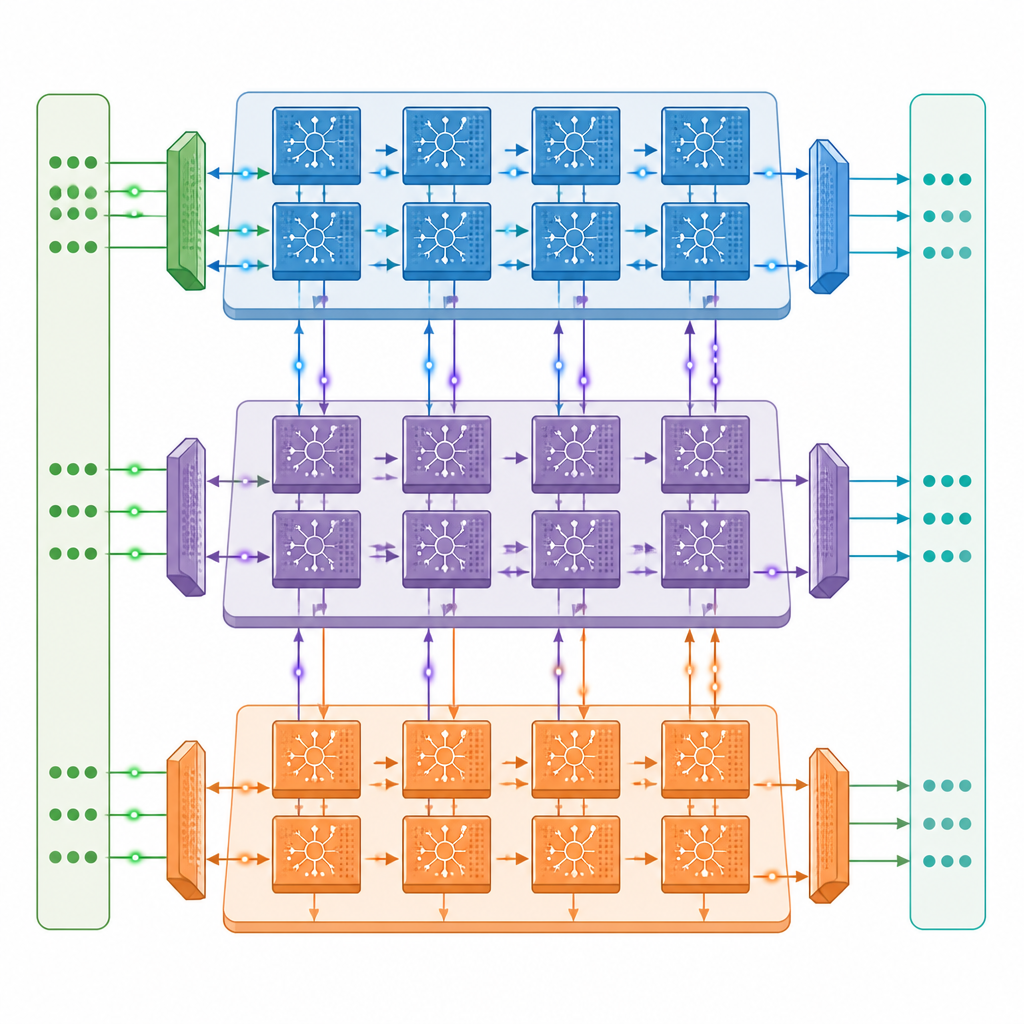
Fazendo mais com menos movimentação de dados
Dentro de cada motor, o hardware é ajustado à natureza intermitente da atividade de pulsos. Circuitos detectam quando grupos de neurônios estão silenciosos e pulam cálculos e leituras de memória desnecessárias, estratégia que reduz o consumo de energia em cerca de metade durante o treinamento em modelos padrão de reconhecimento de imagens. O projeto também reutiliza dados armazenados sempre que possível e guarda pulsos como bits únicos, o que reduz muito a quantidade de memória externa necessária. Em testes com versões pulsantes profundas populares das redes ResNet e VGG, o protótipo atinge até cerca de um terço da velocidade de treinamento de uma poderosa GPU A100 de centro de dados, apesar de ter apenas cerca de um vigésimo de sua capacidade bruta de cálculo, e supera claramente um sistema de borda Jetson Orin.
Do protótipo de laboratório ao aprendizado real na borda
Para demonstrar que a ideia funciona além das simulações, a equipe mapeou uma versão menor da arquitetura em múltiplas placas FPGA e treinou redes pulsantes em conjuntos de dados padrão de imagens e gestos baseados em eventos. O sistema lidou com aprendizado contínuo, em que os modelos são atualizados à medida que novos tipos de amostras aparecem, e com aprendizado federado, no qual vários dispositivos treinam localmente e compartilham apenas atualizações compactas. Em ambos os casos, o sistema pulsante distribuído melhorou a precisão sem centralizar dados brutos, sugerindo aplicações futuras em cidades inteligentes e robótica onde muitos dispositivos aprendem juntos mantendo sob controle as demandas de energia e largura de banda.
O que isso significa para a tecnologia do dia a dia
Em termos simples, este trabalho mostra como construir um motor de treinamento inspirado no cérebro que cabe nos apertados orçamentos de energia dos dispositivos de borda. Ao combinar muitos pequenos cores de aprendizado, roteamento inteligente de dados e pular agressivamente trabalho desnecessário, a arquitetura treina redes pulsantes profundas de forma eficiente sem depender de centros de dados gigantes. Se virarem chips, projetos como esse podem ajudar câmeras, carros e aparelhos domésticos a aprenderem com o ambiente em tempo real, preservando a privacidade e economizando energia.
Citação: Li, M., Zhou, H., Xu, X. et al. A highly energy-efficient multi-core neuromorphic architecture for training deep spiking neural networks. Nat Commun 17, 4403 (2026). https://doi.org/10.1038/s41467-026-70586-x
Palavras-chave: computação neuromórfica, redes neurais pulsantes, IA de borda, hardware de baixo consumo, aprendizado no chip